IN 是子查询的关键字,JOIN 是连接的关键字,项目开发中经常会使用到多表查询,而子查询与连接正是实现多表查询的重要途径。那两者是怎么运行的?IN与JOIN哪个更好?下面就来分析与比较。
现在有test1与test2两张表,都没有任何像主键,外键那样的约束,且只有一个字段。两张表是非相关的。
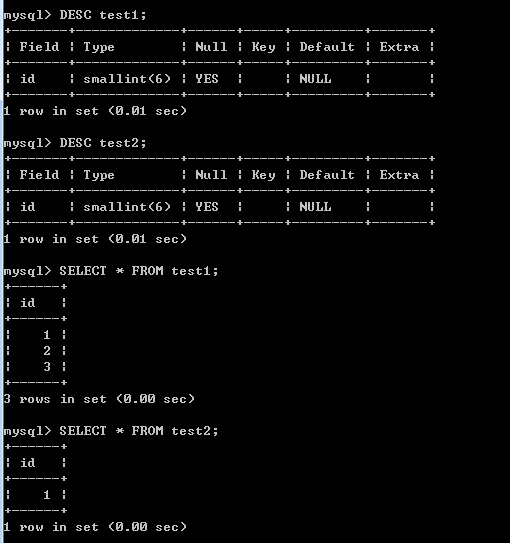
现在使用IN关键字实现子查询,test2作为子查询表(外部表):
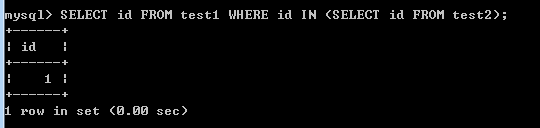
查看执行计划:
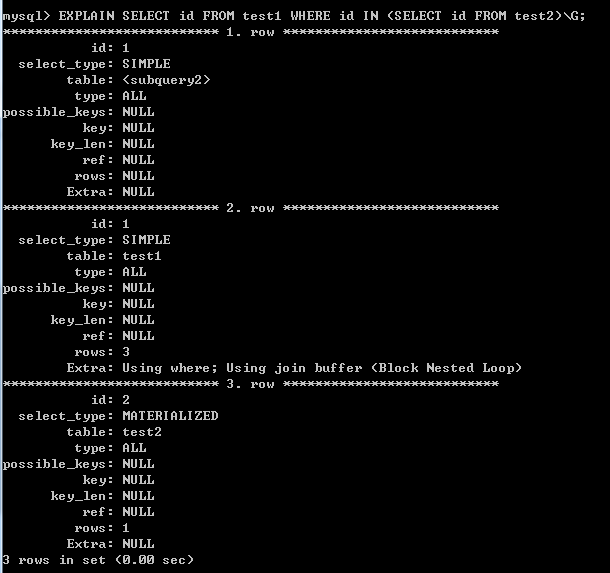
使用JOIN关键字实现连接,同样test2作为外部表:

查看执行计划:
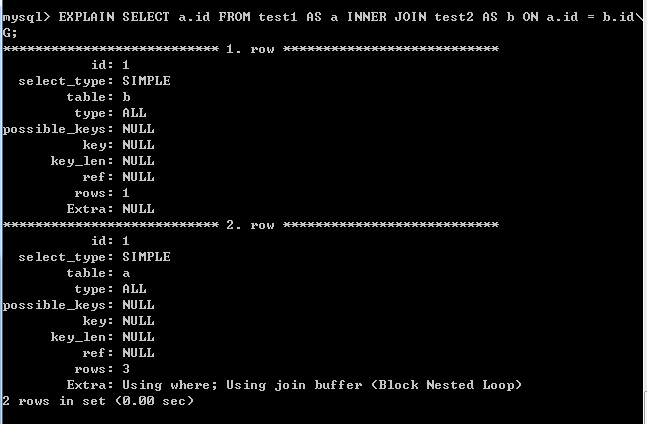
分析:
- 使用IN子查询实现多表查询时,从执行计划可以看出,整个查询分成3个部分,id = 1的查询有两个,id = 2的查询有一个。id大的级别高,优先进行查询。id = 2的查询对应的是test2(子查询表)的FTS。然后进行id = 1的查询,同级别的查询从上往下顺序执行。计划中显示这个查询是个子查询(subquery),同时查询test1的时候,使用到join buffer(Blocked Nested Loop),即连接缓冲(阻塞的嵌套循环)。
- 使用JOIN连接实现多表查询时,先查询test2表(外部表),几乎与IN的方式一样(FTS),再查询test1表,也与IN的方式一样,都用到了join buffer(Blocked Nested Loop)
- 那join buffer(Blocked Nested Loop)究竟是什么意思,我想这篇博客已经解释得很清楚了。http://blog.itpub.net/22664653/viewspace-1692317/
- 总结一下,非相关(无索引)的多表查询中,使用IN与JOIN的查询都是先将外部表的查询结果加入到连接缓冲区,再从内部表拿取数据进入缓冲区进行比较(嵌套循环)。查询计划几乎没有区别。但是,IN存在优先级的关系,比JOIN多了一次subquery的查询,在这种情况下,JOIN更优。
现在在test1表中添加主键(索引),在test2表中添加外键约束(索引),两张表是相关的。
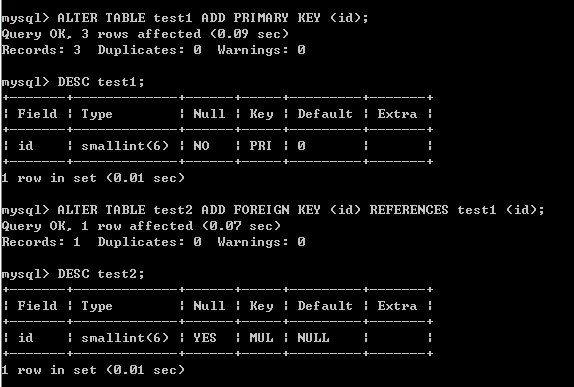
进行同样的查询,返回结果是一样的:
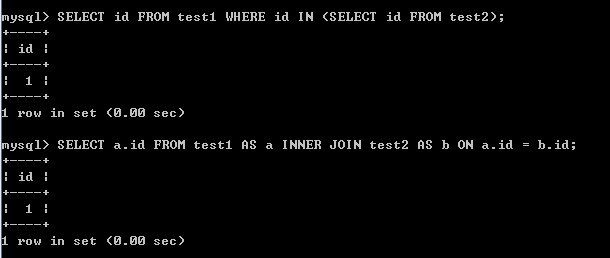
查看IN方式的执行计划:
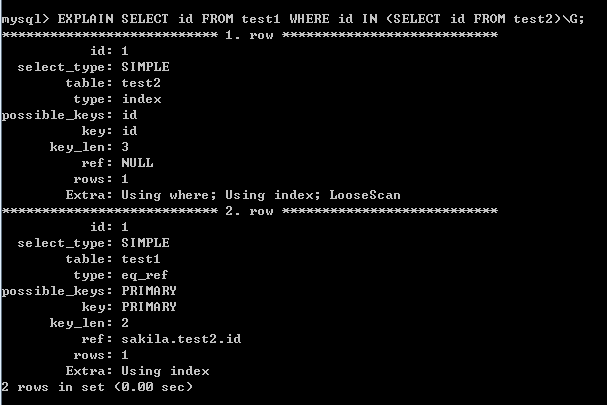
查看JOIN方式的执行计划:
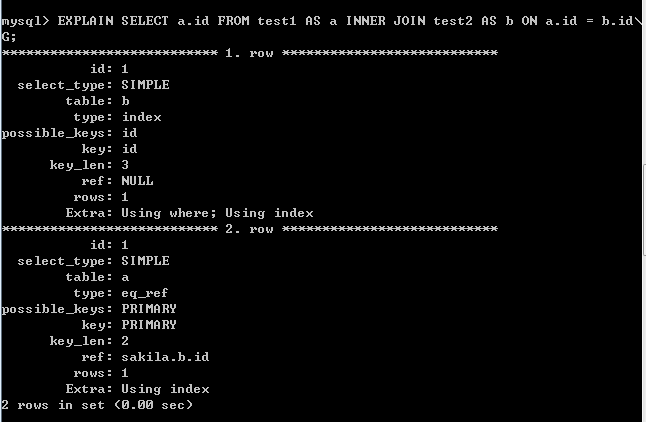
分析:
- 现在使用IN方式进行查询时,不再像非相关那样显示子查询subquery了(若是子查询会有不同的优先级),而是有个参照的过程!先借助索引对外部表test2进行扫描;再借助索引对test1进行扫描,其中参照了test2的id列。
- 使用JOIN方式也是一样有一个参照的过程!
- 这时两种方式的查询也没有用到上面所说的连接缓冲区与阻塞嵌套循环。
- 总结一下,当两张表相关(外键相连)时,无论是IN还是JOIN,联合查找都是一个参照的过程。
写到这里,似乎IN与JOIN在表相关(逻辑外键)的时候,并不知道哪个更优,下面就来实践一下。
实际应用:
下面使用MySQL的示例数据库sakila(customer表中有599个顾客信息,主键为customer_id。rental表中有16044行数据,其中的主键为rental_id,外键列customer_id参考customer表中的主键)分别执行IN与JOIN实现多表查询:
IN查询语句:SELECT CONCAT(first_name,last_name) FROM customer WHERE customer_id IN (SELECT customer_id FROM rental WHERE rental_id <=16000);
结果(返回了599条客户名字信息):
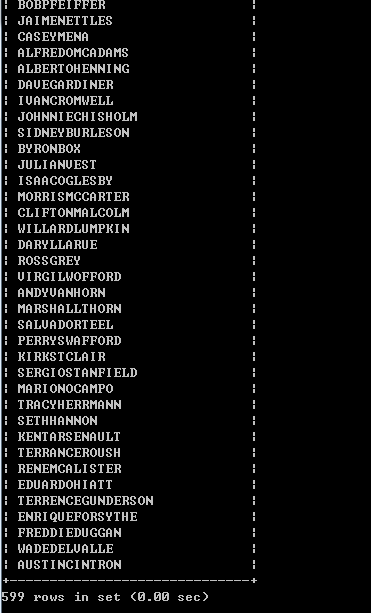
慢查询日志:
# Time: 160717 21:17:58
# User@Host: root[root] @ localhost [127.0.0.1] Id: 17
# Query_time: 0.000000 Lock_time: 0.000000 Rows_sent: 599 Rows_examined: 1198
use sakila;
SET timestamp=1468761478;
SELECT CONCAT(first_name,last_name) FROM customer WHERE customer_id IN (SELECT customer_id FROM rental WHERE rental_id <=16000);
JOIN查询语句:SELECT CONCAT(first_name,last_name) FROM customer AS a INNER JOIN rental AS b ON a.customer_id = b.customer_id WHERE rental_id<=16000;
结果(返回了15995行数据,发现里面有很多重复的名字):
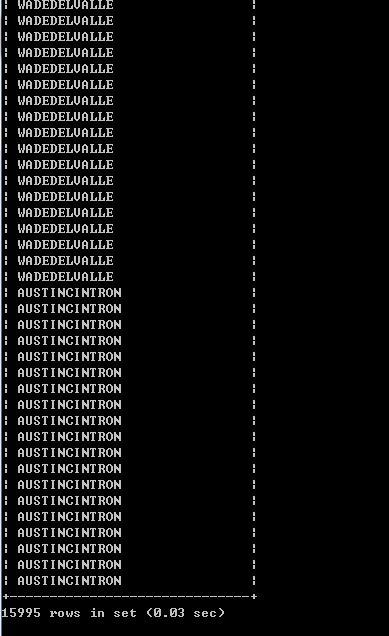
慢查询日志:
# Time: 160717 21:19:17
# User@Host: root[root] @ localhost [127.0.0.1] Id: 18
# Query_time: 0.030000 Lock_time: 0.000000 Rows_sent: 15995 Rows_examined: 16643
SET timestamp=1468761557;
SELECT CONCAT(first_name,last_name) FROM customer AS a INNER JOIN rental AS b ON a.customer_id = b.customer_id WHERE rental_id<=16000;
使用DISTINCT关键字去重的JOIN查询语句:SELECT DISTINCT CONCAT(first_name,last_name) FROM customer AS a INNER JOIN rental AS b ON a.customer_id = b.customer_id WHERE rental_id <=16000;
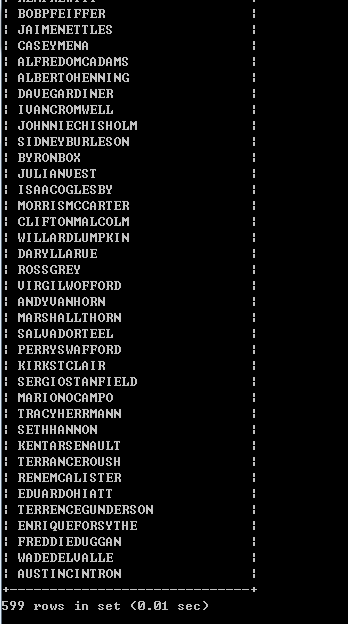
慢查询日志:
# Time: 160717 21:20:31
# User@Host: root[root] @ localhost [127.0.0.1] Id: 19
# Query_time: 0.010000 Lock_time: 0.000000 Rows_sent: 599 Rows_examined: 1797
SET timestamp=1468761631;
SELECT DISTINCT CONCAT(first_name,last_name) FROM customer AS a INNER JOIN rental AS b ON a.customer_id = b.customer_id WHERE rental_id <=16000;
分析:
- 由于rental表的customer_id列作为外键列,参照的是customer表的主键customer_id。因此在该查询上两张表是相关表。上面已经分析了这样的IN与JOIN实现多表查询就不存在连接缓冲与阻塞的嵌套循环。但都是通过参照的关系进行查找。
- 通过比较查找时间(SQL效率)与检索行数(磁盘IO),在这种情况下我会选择IN进行查询。