版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_38736612/article/details/81415304
一、什么是正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符,及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。(非Python独有,python中re模块实现)
二、常见的匹配模式

re.match
re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回None。
最常规的匹配:
import re
content = "Hello 123 4567 World_This is a Regex Demo"
result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}.*Demo$',content)
print(result)import re
content = "Hello 123 4567 World_This is a Regex Demo"
print(len(content))
result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}.*Demo$',content)
print(result)
print(result.group())
print(result.span())泛匹配
import re
content = "Hello 123 4567 World_This is a Regex Demo"
result = re.match('^Hello.*Demo$',content)
print(result)
print(result.group())
print(result.span())匹配目标
import re
content = "Hello 1234567 World_This is a Regex Demo"
result = re.match('^Hello\s(\d+)\sWorld.*Demo$',content)
print(result)
print(result.group(1))
print(result.span())贪婪匹配
import re
content = "Hello 1234567 World_This is a Regex Demo"
result = re.match('^He.*(\d+).*Demo$',content)
print(result)
print(result.group(1))
print(result.span())非贪婪匹配
import re
content = "Hello 1234567 World_This is a Regex Demo"
result = re.match('^He.*?(\d+).*Demo$',content)
print(result)
print(result.group(1))
print(result.span())匹配模式
import re
content = '''Hello 1234567 World_This
is a Regex Demo'''
result = re.match('^He.*(\d+).*Demo$',content)
print(result)
print(result.group(1))
print(result.span())import re
content = '''Hello 1234567 World_This
is a Regex Demo'''
result = re.match('^He.*(\d+).*Demo$',content,re.S)
print(result)
print(result.group(1))
print(result.span())转义
import re
content = 'price is $5.00'
result = re.match('^price is \$5\.00',content)
print(result)总结:尽量使用泛匹配、是用括号得到匹配目标、尽量使用非贪婪模式、有换行符就用re.S
re.search
re.search扫描整个字符串并返回第一个成功的匹配。
扫描二维码关注公众号,回复:
3951379 查看本文章

import re
content = "Extra String Hello 123 4567 World_This is a Regex Demo"
result = re.match('Hello.*?(\d+).*?Demo$',content)
print(result)import re
content = "Extra String Hello 123 4567 World_This is a Regex Demo"
result = re.search('Hello.*?(\d+).*?Demo$',content)
print(result)总结:为匹配方便,能用search就不用match。
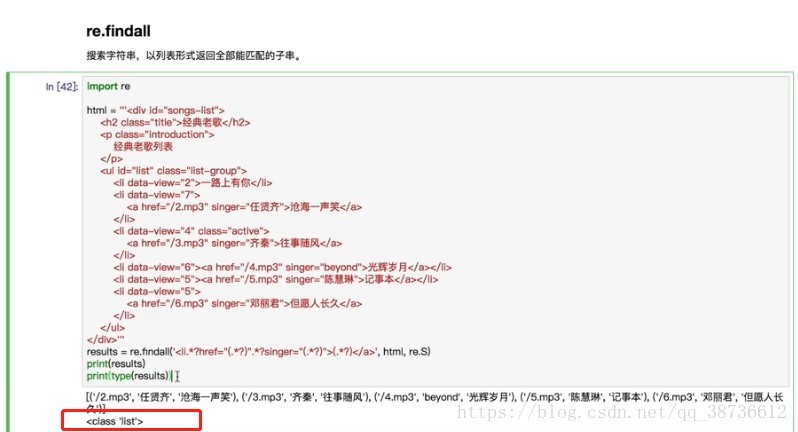
re.findall

re.sub
import re
content = "Extra String Hello 1234567 World_This is a Regex Demo"
conteent = re.sub('\d+','replacement',content)
print(conteent)import re
content = "Extra String Hello 1234567 World_This is a Regex Demo"
content = re.sub('\d+','',content)
print(content)import re
content = "Extra String Hello 1234567 World_This is a Regex Demo"
content = re.sub('(\d+)',r'\1 8910',content)
print(content)re.compile
将正则表达式编译为正则对象,以便复用该匹配模式。
import re
content = "Hello 123 4567 World_This is a Regex Demo"
pattern = re.compile('^Hello\s\d\d\d\s\d{4}\s\w{10}.*Demo$')
result = re.match(pattern,content)
print(result)