关键词:向量、矩阵、数组、数据框、因子、列表
近期开始上手R语言,可能是出于对机器学习的兴趣吧从而了解到这门语言;
之前也看过人生苦短的Python,当然这两门语言都是人工智能技术中很好的工具;
二者也存在一些相同之处,当然是除了开源之外的一些相同之处;
本人参考的书籍是R语言实战[Robert I. Kabacoff]撰写的
1、向量
有的书籍上说向量是R语言最基本的数据类型,我觉得还是很有道理的,即使是初学者,从后面的几个数据类型也能看出这里面的深意。如果你还记得学校里面学过的线性代数这门课,并且有幸还记得向量的数学定义,那么向量,包括后面的几个数据类型,你理解起来会很舒服。
在R里面向量是存储数值型、字符型或逻辑型数据的一维数组(注意和后面的数组类型对比反思)。简单来说,向量里面的数据只允许是同一种类型,与MATLAB不同,R里面的向量创建语句如下:
a <- c(1, 2, 3, 4, 5)
b <- c("a", "b", "c")
c <- c(TRUE, FALSE, FALSE)顺带回顾一下,R里面的赋值符号是“<-”或者“->”,操作顺序与箭头方向一样,当然“=”也能用,故以下代码基本等价:
a <- 3
3 -> a
a = 3大佬告诉我,R里面少用“=”,有时候会出现问题,甚至会被同行取笑。真的是抛bug又丢人,留意。
在生成第一个向量a的时候,你会发现这个向量的元素的连续的数值型数据,如果你是聪明人的话肯定不会在面临需要用一个向量保存1-50的时候一个一个字地敲。测试下面的代码,你会发现a和b没什么区别
a <- c(1, 2, 3, 4, 5)
b <- c(1 : 5)
c <- c(5 : 1)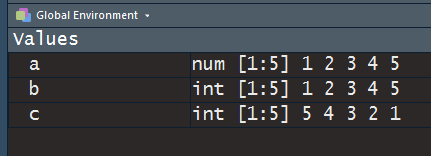
上文说过向量是最基本的数据类型,因为单个常量其实可以看做只有一个元素的向量,又叫标量,这和其他高级语言类似:
pi <- 3.14
today <- "2018/4/27"
ChinaNumberOne <- TRUE如何访问向量的元素呢?正如你曾在学习java或者C的时候也想过的那样。
这里的方法会清新得让你欢呼,因为从访问单个元素的格式上看和java他们没什么区别,但访问多个元素的时候更是让你觉得很欢快。

正如你所看到的,这里潜藏着对非计算机职业人员的业余爱好者一个非常好理解的特性:R语言里面的first one是1,而不是从0开始。所以a[2]在这里指的不是3,而是2。
如果我想单独访问向量的任何几个元素呢?只要你知道它们的确切位置,在[]里面你就可以用c()函数完成你想要的了,其实c()函数也生成了一个向量,所以下面的方法和上图无异。同理得4 3 2的来头。

简练的代码总带给人以好感。
2、矩阵
矩阵这个概念,放在C里面可以叫做二维数组,在这里你可以理解为多个向量的组合(这和线性代数里面的向量组基本一致)。但在矩阵生成的过程我并不认为是简单的拼凑维度一样的向量,因为它看上去更像向量生成,只不过你会规定一行(列)只能写多少字,而当程序一行写不下时它会换一行(列)继续。
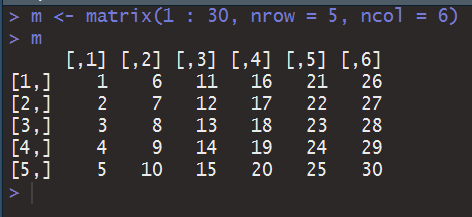
但当你访问某一个元素的时候,你又确实是按下标来的,正如你在C里面一样。不过R的优势在于,你可以直接访问一行一列组成的向量。
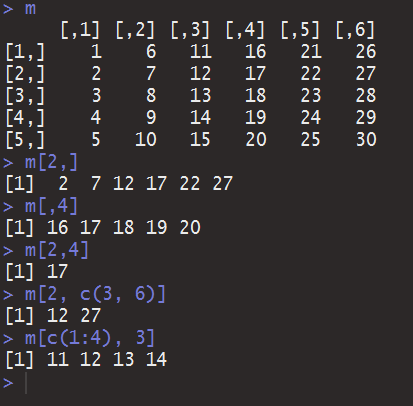
如果你熟悉MATLAB或者Python的话,那对[2,]和[,4]的格式应该和你的鞋子一样熟悉。这样的缺省只指明了行列,便能以一种在编译原理作业中可能被认为是语法错误的姿态,方便的让C里面的几十行代码华丽变为5个字母。那你有想过把行列都缺省了会怎样么?
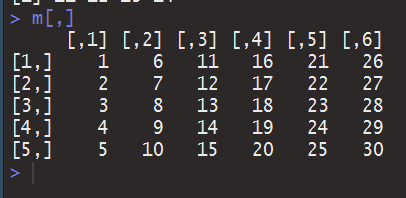
结果当然也是华丽丽的,和直接输入m没有区别,输出了矩阵的所有元素。
你可能会发现,上面生成m的语句,出来的结果是按列顺序排列矩阵元素的。其实这也是矩阵生成的默认顺序,但不是唯一的,你仍然能按行顺序,不过下面的生成函数你值得拥有:
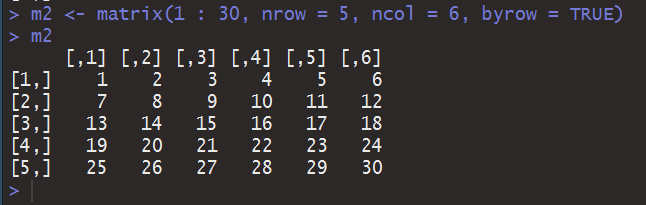
在做数据分析的时候可能还需要对每行每列进行解释,这时候自然少不了标签。
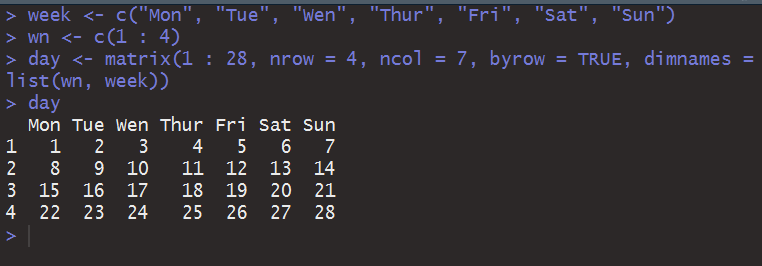
这看上去像是个日历,当然我也是出于这个才举出的这个例子。
3、数组

当然数组的访问和矩阵是类似的,不过是多了一组下标。
4、数据框
如果你刚从C/C++或者java阵营偷偷跑过来了解R,那接下来的数据类型可能让你眼前一亮,它更像是数据库里面的操作,甚至很好的契合的你在数据处理上的一些需求。在向量、矩阵和数组中,我们只能放入同一种数据类型,所以那些箱子或者包裹里面你甚至不能同时将5.56mm子弹和7.62mm子弹放在一起,当然你也不允许向放了子弹的箱子装手雷,如果你是个士兵的话我相信你会把这样的箱子都突突了,特别是上级让你保证后勤补给及时的时候。
好吧,比起矩阵,这才是真正的把向量拼凑在一起的数据类型。
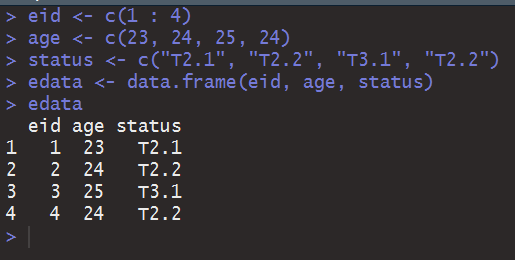
如果你来自BAT的T,你对T2.1肯定比我了解。与矩阵那时不同,这里的age可能不是标签那么简单了。
因为你可以针对性的输出某一列,你甚至能用$符号表示一个数据框的变量:
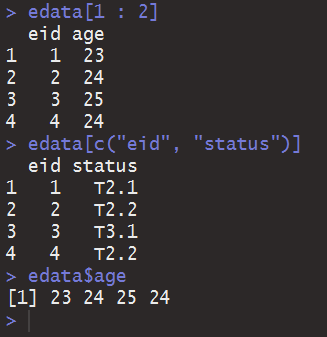
如果一个数据框有很多变量,而在某一段代码中又需要引用它的很多个变量,那么使用$的话就需要在每次引用变量的时候都加上“数据框名$”的前缀,就像你以前学C++而且不知道using namespace std;的时候,每次都可能写很多std::。在R里面我们其实也有using namespace std;这样的简化操作,不过形式有点不一样:
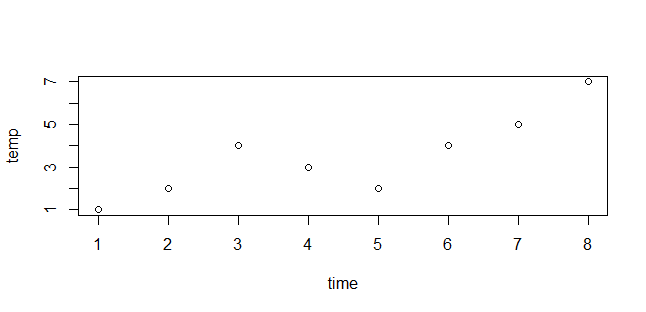
time <- c(1 : 8)
temp <- c(1, 2, 4, 3, 5, 2, 4, 7)
tdata <- data.frame(time, temp)
attach(tdata)
plot(time, temp)
detach(tdata)也许这个例子不够好,但如果有两个数据框,假设它们叫tdata1和tdata2,它们都有temp这个变量,但tdata1表示的是北京的温度数据,而tdata2是南京的数据,那直接引用time和temp进行绘图就会出现二义性的问题。而attach和detach比较方便的解决了部分问题,在attach和detach之间的变量引用,可以省去$部分。
5、因子
这似乎是个很抽象的概念。
其实之前你已经用到过因子的概念,还记得数据框那里的例子么,我们来看看字符型数据变量status在数据框里面是什么样:
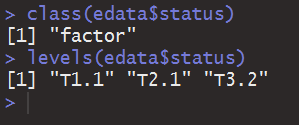
显然,factor的意思就是因子。在用文本数据创建数据框的时候,R会将文本默认为类别数据并转换。levels显示的是该变量的因子水平,这在R里面是一个术语,如果你能把因子当成枚举类型去思考,那因子水平看上去就像是一个枚举类的定义,当然在这里它是动态的。
6、列表
列表可以算作R语言的基本类型中最复杂的了,列表的定义称之为:一些成分的有序集合,而成分可以是任何数据类型,甚至可以是列表。
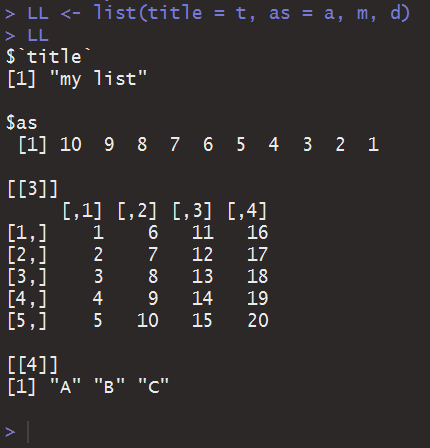
几乎就像结构体一般,引用起来也很方便。
我现在差不多已经明白为什么有人说,
有的语言,一行代码,
就能解决另一些语言成百上千行代码才能实现的功能。
当然这基本是抛开时间成本对比而言的。