目录
R 基本数据结构及操作
一、R 基本数据结构
1》向量
在R中,一切都是向量(vector)。R 中没有单独的标量。
# 创建一个向量 a<-c(1,2,3,4,7) a
筛选
#在变量a中筛选出1 a[1] #在变量a中筛选出7 a[5] #在变量a中筛选出前三个 a[1:3] #在变量a中筛选出小于4的值 a[a<4]
合并向量
使用c()
c(a[1],2,a[1:3],4)
》结果是 1,2,1,2,3,4
2》矩阵
矩阵,从本质上来说就是多维的向量,用matrix函数创建
a<-matrix(c(1,2,3,4),2) a #一共有1,2,3,4 四个数,排成2行。数字顺序默认按列排。例如,第一行为1,3;第一列为1,2.
#如果让数据按行排序。
b<-matrix(c(1,2,3,4),2,byrow=TRUE)
#可以使用seq、rep函数来创建矩阵
#seq函数 产生等差数列 seq(起始数,终点数,间隔),下面的代码的意思是 产生 1~9 共9个数。排成3行。
d<-matrix(seq(1,9,1),3)
#rep 函数 产生重复数 rep(1,4) 产生4个1;rep(c(1,2,3),c(1,2,3)) 产生1个1,2个2,3个3.
#下面代码 产生9个重复的1,排成3行。
e<-matrix(rep(1,9),3)
#产生1~20 个数,排成4行,5列
f<-matrix(1:20,4,5)
筛选
与向量筛选一样,可以采用下标进行筛选。
#筛选矩阵a中 第一行的第一个数 #a[1,1] ,第一个1表示第一行,第二个1表示第一列。 a[1,1] #筛选矩阵a 中第二行的第一个数 a[2,1] #筛选矩阵a 中第二行第三个数。 a[2,3] #输出错误信息,下标超出界限。 #筛选矩阵d 中第一列的前两个数 d[1:2,1] #筛选矩阵d中第二列的第二,第三个数
d[2:3,2]
#筛选矩阵 f 中第四列的前三个数
f[1:3,4]
3》数据框
数据框类似矩阵,与矩阵不同的是,数据框可以有不同的数据类型。 一般做数据分析,我们把一个类似 excel 的表格读入 R ,默认的格式 就是数据框 , 可见数据框是一个非常重要的数据结构。用data.frame 创建数据框。在要分析的数据中,每一行代表一个样本,每一列代表一个 变量。采用R内置的数据集来看。
data("iris") head(iris)
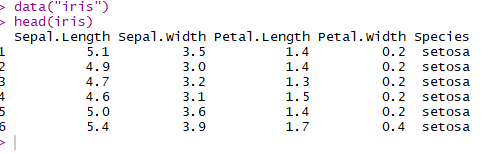
筛选
筛选数据框与矩阵相似,都可以通过数字下标来获取子集,不同地是因为数据框有不同的列名,我们也可以通过列名来获取某一特定列,例如
iris$Sepal.Length

使用names 函数来获取列名。
names(iris)

4》列表
列表是一种递归式的向量,我们可以用列表来存储不同类型的数据
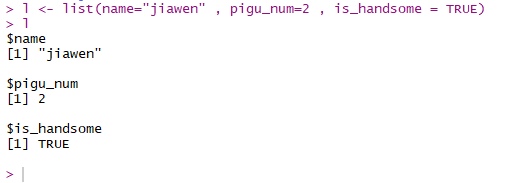
筛选
跟数据框一样的方式
l$name

判断变量的数据结构,可以使用 is. 函数。
#判断a 是否是向量。 is.vetor(a) #返回结果是TRUE 表明是,返回结果是FALSE 表明不是该数据结构 #判断a 是否是数组 is.array(a) #判断a 是否是矩阵 is.matrix(a) #判断a 是否是数据框 is.dataframe(a) #判断a 是否是列表 is.list(a)
变换数据结构
使用as. 函数
#把矩阵a 变为数据框,并赋值给g. g<-as.dataframe(a) #把矩阵a 变成列表,并赋值给h h<- as.list(a)