这一节主要讲前面多次的提到的决策树问题,前面的决策树生成算法递归的产生决策树,直到不能继续分支或者达到要求为止,这样的决策树往往对训练数据的分类很准确,因为他就是基于训练数据的熵或者基尼不存度进行分类的,因此对训练数据的会产生过拟合现象,而对未知的数据则没有那么准确。过拟合的本质原因是决策树在训练时追求如何提高训练数据的准确度,而没有考虑构件出的决策树的复杂性,直观上我们能想象出当决策树越复杂时,训练数据的分类效果越好,因为复杂意味着分支多,分支多意味着对数据的分类效果越好。决策树复杂是对训练数据过拟合的本质原因,因此为了提高决策树的泛化能力,需要兼顾决策树的复杂度问题,这个问题如何考虑才能得到比较好的决策树呢?
先弄清楚几个概念,这里的概念很重要,请大家一定要注意,因为这也是下面搞晕的原因:

决策树由节点和有向边组成,其中节点有两种类型: 内部节点和叶节点,内部节点表示一个特征或者属性(如A,B,C都为内部节点),叶节点表示一个类(如D1,D2,,都是叶节点)
目前比较好的解决这个问题的方法就是决策树的剪枝算法,这个算法是怎么工作的呢?或者工作的原理是什么呢?下面我们就一起来看看:
为了让大家更容易理解,在这里先简单的讲解一下李航的《统计学习方法》中的一个例子,这个例子所给的训练数据是贷款申请的数据,根据特征决策是否批准贷款申请,特征有年龄、是否有工作、是否有房子、信贷情况这4个特征:

这里通过熵计算,详情就不说了,直接给出公式和决策树图:


好,我们来详细的看看决策树的决策过程,他是依据信息增益进行决策的,增益越大说明这个特征对最后的分类影响越大,因此从上层到下层信息增益是逐渐下降的,为了追求训练数据的准确率,会不停的进行分支下去,直到信息增益0.此时只有一类了,因此也是最纯净的,所以增益为0 ,但是这也带来了问题就是决策树的分支会很复杂,且对训练数据过拟合,对新数据没有很好的准确度,因此为了提高决策树的泛化能力,就需要决策树不要只追求训练数据的准确度,还要考虑泛化能力,而这个泛化能力的提高是希望决策树对训练数据不要分的那么“仔细”,想要达到这样的效果,一个可行的办法是控制决策树的树枝的复杂性,我们知道决策树的树枝越多说明分的越细,因此可以通过控制树枝的多少来提高决策树的泛化能力,到这里我们找到了,如何解决这个问题的思路了,但是问题是我还要考虑决策的准确率,不能以大幅度降低准度度来提高决策树的的泛化能力,这个是不可取的,因此为了兼顾两者,前辈们提出了剪枝的方法,这个方法是怎么工作呢?其实很简单,首先我还是按照之前的决策生成决策树,此时的决策树对训练数据具有很高的准确度但是泛化能力不好,在此基础上,提出了控制决策树的复杂度,为了兼顾准确度,把二者结合定义一个目标表达式,这个目标表达式是怎么定义呢?这个稍后解释,先引入一个概念,我们知道对分类的数据我们同个信息增益进行决策的,那么这个信息增益充当什么角色呢?如使用决策树进行回归那么我们引入的试试损失函数或者误差函数这个又是充当什么呢?这两个有什么相同之处呢?其实这个两个就是我们决策树的决策依据,在分类中我们以最大的信息增益为决策依据,而在回归中,我们以损失函数作为我们的优化目标,使其达到最小就是我们的最终目的。我们从这里可不可以加入我们的一些限制决策树复杂度的条件呢?其实我们新的目标表达式就是这样来的,我们下面详细看看:
在这里我就不码字了,直接从李航老师的书中解图过来,大家多包涵,我尽量把剪枝的过程说清楚,我看好多博客都说的不清不楚,还有的就是错的,本篇是从问题从发,一步步到表达式,这样才不会觉得很突兀:

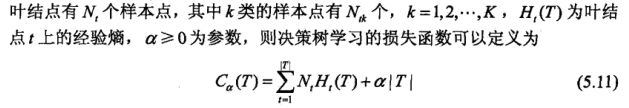
这里需要解释一下此时定义的,此时的定义就把决策依据的损失函数和决策树的复杂的联系起来了,这也是最不好理解的,也是很多博客说不清的地方,在这里只代表本人的理解,有什么问题请留言,我们一起探讨。首先定义时是一个完整的树就是对训练数据准确度很高但是泛化能力不好的原始树,假设这颗树的叶节点个数为|T|,t为树T的某个叶节点(如上图的有自己的房子和有工作都是叶节点),这个叶节点有个样本点,其中K类的样本点个数为
,就这些样本点中有
个样本数据属于K类的,
是指在叶节点的熵,我们知道每个叶节点往下分支的依据是信息增益,其来源就是熵的变化,而且分支越细,熵就越小,因为确定性越来越大了。因此损失函数的定义为:
我们来看看这个公式的意义,等式的右边的第一项求和是 对树T的所有的叶节点的样本数据的熵进行求和(我们知道在回归中损失函数是真实值和预测值的差的平方),而在分类中,以熵为分类依据,理论熵分类完全正确,熵应该为0(因为都是同一类,带来为1),但是如果树叶节点的熵不为零说明分类的不完全正确,同时此时的熵就是损失了或者误差了(这里好多人没解释为什么这样,这里我解释,有疑问的请留言),而后面的一项,是说明这颗树T的叶节点的个数乘以一个系数
,这表明什么呢?简单来说就是衡量了树的复杂度,我们知道一颗树越复杂表明他的树叶越多,因此个数就可以衡量树的复杂度,而
就是用来调整树的复杂度的,稍后会详解
的,好,到这里我们再看看上面的损失函数的合理性,大家应该都可以理解了,如果是回归更容易理解因为是误差函数,这个时候我们求其
的最小值,此时一方面是要求正确率尽可能的高,另一方面是希望复杂度尽可能的低,这样目标公式就建立起来了,我们再看看这个目标公式会发现,此时的损失函数是正对全局优化的即整棵树的所有叶节点的损失和,因此求出来的一定是全局最优的,到这里大家应该都可以理解,我们继续深入:

这里的内容就是我们上面说的,只是作者没详细说明为什么这样算,然而这里也是让人困惑的地方,只有这里搞懂,下面才能深入理解他的剪枝过程,我们接着看李航的书:

下面就详细的介绍一下 是怎样影响复杂度的,首先大家需要明确,我们的损失函数的第一项和第二项是矛盾的:
因为我们整体是希望求的最小值,而上式的第一项是损失误差,希望尽量的小,而要想使损失尽量的小,那么表现在决策树上就是决策树越来越复杂即树叶节点很多,即|T|很多,但是第二项呢?也是希望尽可能的小,在给定 时,希望|T|尽可能的小,因此矛盾就出来了,因此需要找到平衡的|T|,而这个平衡值T就和
有关了,大家还记得岭回归的目标式子么?和那里的岭参数一个道理,在这里我们单独的解释一下这个
的作用:
对任意内部节点t,
剪枝前的状态:有个叶子节点,预测误差是
剪枝后的状态:只有本身一个叶子节点,预测误差是
因此剪枝前的以t节点为根节点的子树的损失函数是 :
剪枝后的损失函数是:
在这里需要解释一下,剪枝后为什么是这样,剪之后就只有他本身的叶节点了,因此直接计算误差,因为只有一个叶节点,所以就是
。
好,到这里我们需要好好探讨一下了,我们知道,决策树随着树叶的增加是损失值是减小的,那么如果我剪掉这个叶节点,是不是就意味着的损失值在增大呢,是的,但是此时的减小为1了,一个增大,一个减小,最后求和的结果是增大还是减小呢?答案是不一定的,这里理解很关键,我们看看剪枝前的公式,发现误差是最小的,但是决策树此时复杂度是最大的,因此对应一个值,那么剪枝后呢?剪之后就是我们知道损失是增大的,但是复杂度即叶节点从
直接变为1了,,因此他们的求和后的结果就有三种情况,要么相等,要么是增大或者减小,这个大家应该可以理解。对于剪枝后的求和如果小于剪枝前的求和,说明复杂度在其中起到关键的作用,而损失函数起的作用很小,简单来说就是剪枝前的叶节点并没有很好的提高准确度但是却带来更复杂的树,因此可以考虑剪去这个叶节点,,这就是剪枝的过程和原理了,这也是李航书中提到的:

到这里,相信大家还是能理解的,不理解的请留言,我们继续讨论,我们知道,剪枝前和剪枝后的大小还取决于,因为
不同,得到的结果可能不同,那么
取何止更好呢?这个值怎么取才能是全局最优剪枝呢?我们继续深入探讨:
此时我们令剪枝前和剪枝后的两式相等:
即得到:
求出:
也就是说当等于这个值时剪枝前和剪枝后的损失结果是一样的,这个就是灵界条件了,好,我们知道临界条件了,下面是到底如何取
才能取到全局最优的剪枝后的决策树呢?
这时我们需要再看看这个表达式:
我们发现在中间起着制约的作用,但是它到底代表什么物理意义呢?我们来分析一下,我们知道,我们求
的最小值,如果
很大时加入为无穷大,则此时要想最小,就需要
最小,如果
很小假如为0时,此时
可以取到很大,同时也说明了,当
=0时,树很复杂,训练数据准确率很高即过拟合,因此可以看出
是衡量损失函数剪枝后的损失程度的量。
这里如何选择参数呢?哪个参数对应的损失最小同时复杂度最小呢?我们知道,一旦给定一个
值,则就会对应一个最优的剪枝树,只是哪个是最优的,则需要遍历了,如何遍历呢?

此时大家应该可以看懂了吧,人们是找到所有可能剪枝的剪枝后树,然后通过数据交叉验证,看看哪个的错误率和泛化能力最好就选择哪个。

好,剪枝过程基本讲完了,下面我们以CART数的创建和剪枝为例进行系统的讲解:
CART树的生成是以二叉树为分支的,分为分类和回归,这里就不详细讲了,请看李航的《统计学习方法》第68页,下面直接给出生成算法了:


生成还是和以前的决策树一样,我们看看剪枝算法:
CART剪枝:
先说明一下,该算法是采用动态规划进行设计的,因此他先计算树T的所有节点的损失值,剪枝是从下到上进行剪枝的:

上面的第6步有错误,应该返回到底三步,要不然最小值永远不变了 ,之所以返回到第三步就是计算全局的,在此更新。李航网上已经勘误了,大家需要注意
刚开始设置为无穷大,,然后计算所有内部节点的
,然后取一个最小的值赋值给
,我们知道,所有的节点的
肯定是不一样的,
最小说明|T|很大,那么就可以剪枝了,此时记录对应的剪枝后的树,存储起来,减掉以后,全局的节点的
都会变化,此时在次计算所有的
,然后继续剪枝,这里需要强调的是这是递归实现动态规划,因此它是在第一个剪枝的基础上进行再次剪枝的,因为重新计算了
,那么那个最小的
一定比之前的要大,直到根节点结束。下面能解释我的理解:

就是说因为是递归,所以只要满足条件才会全部返回,我也不知道这样理解对不对,感觉有问题的请留言我们一起交流,机器学习算法写完后我会开一篇算法专栏,把常用的算法总结一下。
好,本篇到此结束,有疑问请留言,这是本人的理解难免会有错误,请多包涵,可以一起讨论,微信号:zsffuture