本文将对如何在Springboot项目中整合hive-jdbc进行简单示例和介绍,项目的完整目录层次如下图所示。
官方帮助文档地址:https://cwiki.apache.org/confluence/display/Hive/HiveClient#HiveClient-JDBC
添加依赖与配置
首先,需要在工程POM文件中引入hive-jdbc所需的Maven依赖。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop</artifactId>
<version>2.5.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.3.3</version>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.aggregate</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-jdbc</artifactId>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>然后,在核心配置文件 application.yml 中添加数据源相关配置。
hive:
url: jdbc:hive2://172.16.250.234:10000/hive
driver-class-name: org.apache.hive.jdbc.HiveDriver
type: com.alibaba.druid.pool.DruidDataSource
user: hadoop
password: Pure@123
# 下面为连接池的补充设置,应用到上面所有数据源中
# 初始化大小,最小,最大
initialSize: 1
minIdle: 3
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 30000
validationQuery: select 1
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20配置数据源与JdbcTemplate
我们可以使用SpringBoot默认的 org.apache.tomcat.jdbc.pool.DataSource 数据源,并使用这个数据源装配一个JdbcTemplate。
import org.apache.tomcat.jdbc.pool.DataSource;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.env.Environment;
import org.springframework.jdbc.core.JdbcTemplate;
@Configuration
public class HiveJdbcConfig {
private static final Logger logger = LoggerFactory.getLogger(HiveJdbcConfig.class);
@Autowired
private Environment env;
@Bean(name = "hiveJdbcDataSource")
@Qualifier("hiveJdbcDataSource")
public DataSource dataSource() {
DataSource dataSource = new DataSource();
dataSource.setUrl(env.getProperty("hive.url"));
dataSource.setDriverClassName(env.getProperty("hive.driver-class-name"));
dataSource.setUsername(env.getProperty("hive.user"));
dataSource.setPassword(env.getProperty("hive.password"));
logger.debug("Hive DataSource Inject Successfully...");
return dataSource;
}
@Bean(name = "hiveJdbcTemplate")
public JdbcTemplate hiveJdbcTemplate(@Qualifier("hiveJdbcDataSource") DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
}我们也可以使用数据源,本例中使用的是Druid数据源,其配置内容如下。
import javax.sql.DataSource;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import com.alibaba.druid.pool.DruidDataSource;
@Configuration
@ConfigurationProperties(prefix = "hive")
public class HiveDruidConfig {
private String url;
private String user;
private String password;
private String driverClassName;
private int initialSize;
private int minIdle;
private int maxActive;
private int maxWait;
private int timeBetweenEvictionRunsMillis;
private int minEvictableIdleTimeMillis;
private String validationQuery;
private boolean testWhileIdle;
private boolean testOnBorrow;
private boolean testOnReturn;
private boolean poolPreparedStatements;
private int maxPoolPreparedStatementPerConnectionSize;
@Bean(name = "hiveDruidDataSource")
@Qualifier("hiveDruidDataSource")
public DataSource dataSource() {
DruidDataSource datasource = new DruidDataSource();
datasource.setUrl(url);
datasource.setUsername(user);
datasource.setPassword(password);
datasource.setDriverClassName(driverClassName);
// pool configuration
datasource.setInitialSize(initialSize);
datasource.setMinIdle(minIdle);
datasource.setMaxActive(maxActive);
datasource.setMaxWait(maxWait);
datasource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);
datasource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis);
datasource.setValidationQuery(validationQuery);
datasource.setTestWhileIdle(testWhileIdle);
datasource.setTestOnBorrow(testOnBorrow);
datasource.setTestOnReturn(testOnReturn);
datasource.setPoolPreparedStatements(poolPreparedStatements);
datasource.setMaxPoolPreparedStatementPerConnectionSize(maxPoolPreparedStatementPerConnectionSize);
return datasource;
}
// 此处省略各个属性的get和set方法
@Bean(name = "hiveDruidTemplate")
public JdbcTemplate hiveDruidTemplate(@Qualifier("hiveDruidDataSource") DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
}使用DataSource操作 Hive
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import javax.sql.DataSource;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 使用 DataSource 操作 Hive
*/
@RestController
@RequestMapping("/hive")
public class HiveDataSourceController {
private static final Logger logger = LoggerFactory.getLogger(HiveDataSourceController.class);
@Autowired
@Qualifier("hiveJdbcDataSource")
org.apache.tomcat.jdbc.pool.DataSource jdbcDataSource;
@Autowired
@Qualifier("hiveDruidDataSource")
DataSource druidDataSource;
/**
* 列举当前Hive库中的所有数据表
*/
@RequestMapping("/table/list")
public List<String> listAllTables() throws SQLException {
List<String> list = new ArrayList<String>();
// Statement statement = jdbcDataSource.getConnection().createStatement();
Statement statement = druidDataSource.getConnection().createStatement();
String sql = "show tables";
logger.info("Running: " + sql);
ResultSet res = statement.executeQuery(sql);
while (res.next()) {
list.add(res.getString(1));
}
return list;
}
/**
* 查询Hive库中的某张数据表字段信息
*/
@RequestMapping("/table/describe")
public List<String> describeTable(String tableName) throws SQLException {
List<String> list = new ArrayList<String>();
// Statement statement = jdbcDataSource.getConnection().createStatement();
Statement statement = druidDataSource.getConnection().createStatement();
String sql = "describe " + tableName;
logger.info("Running: " + sql);
ResultSet res = statement.executeQuery(sql);
while (res.next()) {
list.add(res.getString(1));
}
return list;
}
/**
* 查询指定tableName表中的数据
*/
@RequestMapping("/table/select")
public List<String> selectFromTable(String tableName) throws SQLException {
// Statement statement = jdbcDataSource.getConnection().createStatement();
Statement statement = druidDataSource.getConnection().createStatement();
String sql = "select * from " + tableName;
logger.info("Running: " + sql);
ResultSet res = statement.executeQuery(sql);
List<String> list = new ArrayList<String>();
int count = res.getMetaData().getColumnCount();
String str = null;
while (res.next()) {
str = "";
for (int i = 1; i < count; i++) {
str += res.getString(i) + " ";
}
str += res.getString(count);
logger.info(str);
list.add(str);
}
return list;
}
}使用 JdbcTemplate 操作 Hive
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.dao.DataAccessException;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 使用 JdbcTemplate 操作 Hive
*/
@RestController
@RequestMapping("/hive2")
public class HiveJdbcTemplateController {
private static final Logger logger = LoggerFactory.getLogger(HiveJdbcTemplateController.class);
@Autowired
@Qualifier("hiveDruidTemplate")
private JdbcTemplate hiveDruidTemplate;
@Autowired
@Qualifier("hiveJdbcTemplate")
private JdbcTemplate hiveJdbcTemplate;
/**
* 示例:创建新表
*/
@RequestMapping("/table/create")
public String createTable() {
StringBuffer sql = new StringBuffer("CREATE TABLE IF NOT EXISTS ");
sql.append("user_sample");
sql.append("(user_num BIGINT, user_name STRING, user_gender STRING, user_age INT)");
sql.append("ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' "); // 定义分隔符
sql.append("STORED AS TEXTFILE"); // 作为文本存储
logger.info("Running: " + sql);
String result = "Create table successfully...";
try {
// hiveJdbcTemplate.execute(sql.toString());
hiveDruidTemplate.execute(sql.toString());
} catch (DataAccessException dae) {
result = "Create table encounter an error: " + dae.getMessage();
logger.error(result);
}
return result;
}
/**
* 示例:将Hive服务器本地文档中的数据加载到Hive表中
*/
@RequestMapping("/table/load")
public String loadIntoTable() {
String filepath = "/home/hadoop/user_sample.txt";
String sql = "load data local inpath '" + filepath + "' into table user_sample";
String result = "Load data into table successfully...";
try {
// hiveJdbcTemplate.execute(sql);
hiveDruidTemplate.execute(sql);
} catch (DataAccessException dae) {
result = "Load data into table encounter an error: " + dae.getMessage();
logger.error(result);
}
return result;
}
/**
* 示例:向Hive表中添加数据
*/
@RequestMapping("/table/insert")
public String insertIntoTable() {
String sql = "INSERT INTO TABLE user_sample(user_num,user_name,user_gender,user_age) VALUES(888,'Plum','M',32)";
String result = "Insert into table successfully...";
try {
// hiveJdbcTemplate.execute(sql);
hiveDruidTemplate.execute(sql);
} catch (DataAccessException dae) {
result = "Insert into table encounter an error: " + dae.getMessage();
logger.error(result);
}
return result;
}
/**
* 示例:删除表
*/
@RequestMapping("/table/delete")
public String delete(String tableName) {
String sql = "DROP TABLE IF EXISTS "+tableName;
String result = "Drop table successfully...";
logger.info("Running: " + sql);
try {
// hiveJdbcTemplate.execute(sql);
hiveDruidTemplate.execute(sql);
} catch (DataAccessException dae) {
result = "Drop table encounter an error: " + dae.getMessage();
logger.error(result);
}
return result;
}
}启动测试
通过运行HiveApplication类的main方法启动项目,接下来对每个示例方法进行测试。
创建Hive表
待项目启动后,在浏览器中访问 http://localhost:8080/hive2/table/create 来创建一张 user_sample 测试表:
user_sample 表的创建 sql 如下:
create table user_sample
(
user_num bigint,
user_name string,
user_gender string,
user_age int
) row format delimited fields terminated by ',';
查看Hive表
测试表创建完成后,通过访问 http://localhost:8080/hive/table/list 来查看hive库中的数据表都有哪些?
返回如下内容:

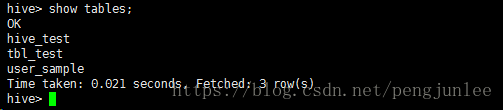
在Hive客户端中使用 show tables 命令查看,与浏览器中看到的数据表相同,内容如下:
访问 http://localhost:8080/hive/table/describe?tableName=user_sample 来查看 user_sample 表的字段信息:
返回如下内容:

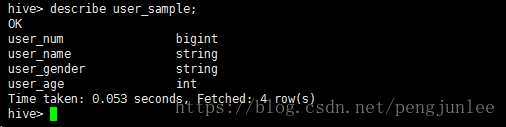
在Hive客户端中使用 describe user_sample 命令进行查看,与浏览器中看到的数据表字段相同。
导入数据
接下来进行数据导入测试,先在Hive服务器的 /home/hadoop/ 目录下新建一个user_sample.txt 文件,内容如下:
622,Lee,M,25
633,Andy,F,27
644,Chow,M,25
655,Grace,F,24
666,Lily,F,29
677,Angle,F,23然后在浏览器中访问以下地址,将 /home/hadoop/user_sample.txt 文件中的内容加载到 user_sample 数据表中。
http://localhost:8080/hive2/table/load
数据导入成功之后,访问 http://localhost:8080/hive/table/select?tableName=user_sample ,返回如下内容:

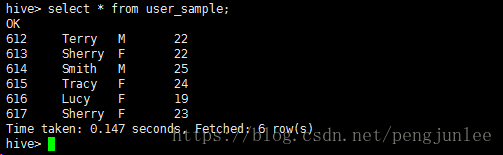
在Hive客户端中使用 select * form user_sample 命令进行查看,与浏览器中看到的内容相同。
插入数据
再访问 http://localhost:8080/hive2/table/insert 来测试向 user_sample 表中插入一条数据。

Hive客户端打印的Map-Reduce执行过程日志如下:

再次访问 http://localhost:8080/hive/table/select?tableName=user_sample ,内容如下:

项目源码已上传至CSDN,资源地址:https://download.csdn.net/download/pengjunlee/10613827