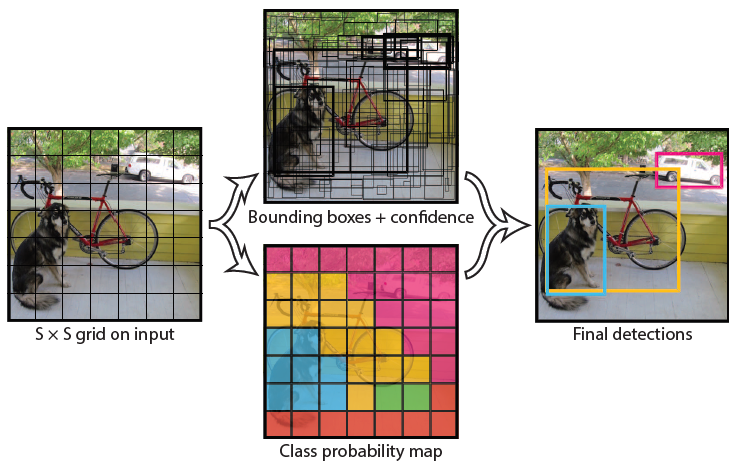
将目标检测作为回归问题,整张图作为网络的输入,将物体检测与分类合到一起,整张图作为输入,输出为回归bounding box的位置信息和其所属的类别
- DPM:使用滑动窗口,对每个分区进行分类
- RCNN:具有复杂的管道而且是缓慢和难以优化,因为每个组件必须单独训练
基本思路
- 将图片分为S*S的区域,此处不是RCNN那样对每个区域进行分类,而是进过CNN后,得到S*S个像素点的特征图
- 每个网格单元负责检测目标中心落在此处的目标,网格单元预测B个bbox回归信息和置信度分数(回归信息有4个值,x和y是bbox相对于网格的偏移量,w和h是bbox相对于整张图的尺寸比例。confidence代表了所预测的bbox中含有object的置信度和这个box预测的有多准两重信息)
- 最后特征图是 S*S, 每个像素点有B个5坐标Bbox位置信息和1个类别信息,S*S*(B*5+C)
- 吴恩达:S*S*B*(5+C).每个bbox都是自己的分类结果
上述中confidence的计算公式为:如果有object落在一个grid cell里,Pr(Object)取1,否则取0
每个网格预测的class信息 和每个bbox所预测的confidence相乘,得到每个bbox的class-specific confidence score:
得到每个bbox属于某一类的概率。对class-specific confidence score设置阈值进行筛选,并通过NMS得到最终结果
训练
- 对训练数据中的每个ground truth,指定S*S*B个bbox中的一个与之对应(IOU最大)
- confidence取值:对所有bbox,若与ground truth对应,取值应为两者的IOU,其他bbox为0
- 激活函数:leaky rectified linear activation:漏泄ReLu:
