RCNN系列检测器奠定了检测模型two stage的网络结构,首先通过一系列方法(传统的selective search 即 RCNN,RPN结构即fasterRCNN)产生足够的区域候选,然后通过分类网络判别区域候选是否为目标并同时回归出目标的位置。这种two stage的网络存在一些明显的弊端:
- 速度瓶颈,由于第一阶段产生的区域候选一般超多,通常几千上万个,因此后续的分类回归的速度无法做到很快。
- 训练麻烦,通常为交替训练的模型,网络结构不够优雅。
- 无法考虑全局信息,由于是先产生区域候选,然后进行特征提取,无法在进行分类回归时考虑全局的信息。因此其对于背景的误Recall也较高(误检多)。
YOLO作为one stage 检测模型的开端,为了解决上述的two stage的典型弊端而生,主要想法就是对于原图进行区域划分,不再进行Region Proposal环节,每个区域就负责回归对应的目标的位置及类别就好,效果也很显著,在GPU机器能够实现45fps,Fast YOLO能够实现155fps,另外对背景的误判率也显著低于RCNN系列。同时有个很有意思的点,YOLO因为能够考虑到图像全局信息,在模型的迁移和泛化效果上要好于其他检测网络。
网络框架

- Resize成448*448,图片分割得到7*7网格(cell)
- CNN提取特征和预测:卷积部分负责提特征。全连接部分负责预测:a) 7*7*2=98个bounding box(bbox) 的坐标xcenter,ycenter,w,h 和是否有物体的confidence 。 b) 7*7=49个cell所属20个物体的概率。
- 过滤bbox(通过nms)

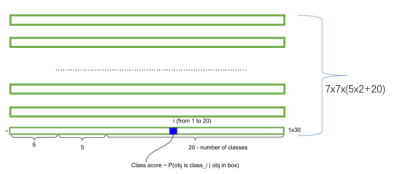
Yolo V1网络设计很是简洁,首先将输入图片划分为S*S个珊格,然后每个格子回归出B个检测框,每个检测框包含5个值(x,y,w,h,conf),区别于Rcnn系列,x,y为目标中心点相对于珊格边界的偏移比例,w,h为目标宽高相对于输入图像的比例,conf为预测目标与所有GT的IOU。同时每个珊格回归出其包含类别i的概率。将目标检测问题转换为完全的回归问题。对于每张图来说,只需要回归出S*S*(B*5+C)的tensor即可。在Pascal VOC测试集上,S默认为7,B为2。

网络训练
YOLO将输入图像分成SxS个格子(如下图的7x7个网格grid cell),每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。如下图所示,图中物体狗的中心点(红色原点)落入第5行、第2列的格子内,所以这个格子负责预测图像中的物体狗。

每个格子输出B个bounding box(包含物体的矩形区域)信息,以及C个物体属于某种类别的概率信息(属于狗对应的那类置为1)。

最后一层输出为 (7*7)*30的维度。每个 1*1*30的维度对应原图7*7个cell中的一个,1*1*30中含有类别预测和bbox坐标预测。总得来讲就是让网格负责类别信息,bounding box主要负责坐标信息(部分负责类别信息:confidence也算类别信息)。具体如下:
每个网格(1*1*30维度对应原图中的cell)要预测2个bounding box (图中黄色实线框),Bounding box信息包含5个数据值,分别为(xcenter,ycenter,w,h)和confidence,其中x,y是指当前格子预测得到的物体的bounding box的中心位置的坐标。w,h是bounding box的宽度和高度。注意:实际训练过程中,w和h的值使用图像的宽度和高度进行归一化到[0,1]区间内;x,y是bounding box中心位置相对于当前格子位置的偏移值,并且被归一化到[0,1]。
confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息:

其中如果有ground true box(人工标记的物体)落在一个grid cell里,第一项取1,否则取0。 第二项是预测的bounding box和实际的ground truth box之间的IOU值(以像素为单位,用真实区域的像素面积归一化到[0,1]区间)。
综上,每个bounding box要预测xcenter,ycenter,w,h,confidence共5个值,2个bounding box共10个值,对应1*1*30维度特征中的前10个。

每个网格还要预测类别信息,论文中有20类。7x7的网格,每个网格要预测2个 bounding box 和 20个类别概率,输出就是 7x7x(5x2+20) =1470维。(通用公式:SxS个网格,每个网格要预测B个bounding box还要预测C个categories,输出就是S x S x (5*B+C)的一个tensor。 注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的)
训练策略
- ImageNet Pretrain Backbone
- 由于包含一些小目标,因此将网络输入从224 提升到 448
- 平衡背景前景对于分类及坐标回归的影响,由于非目标区域一般是多于目标区域的,会将conf拉向0,这会减弱前景对于loss的贡献,因此yolo通过放大前景对于loss的权重进行一定均衡。前背景权重分别为5,0.5.
- 首层fc后加入dropout、同时加入随机的线性变换和裁剪及调整HSV的饱和度和亮度进行argument用以减弱overfitting。
- 由于部分大的目标可能占据多个珊格,因此加入了nms处理,提升2-3%map。
损失函数设计
Backbone是典型的Inception model。Loss计算方式,多类loss混加,即对于x,y,w,h的回归loss + 检测框包含目标的概率的conf + grid cell 包含目标类别的分类loss。虽然每个grid cell具有多个检测框结果,但是只通过最高IOU的框计算conf,也就是“Responsible”机制。


损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification这个三个方面达到很好的平衡。简单的全部采用了sum-squared error loss(均方和误差)作为loss函数来优化模型参数,即网络输出的S*S*(B*5 + C)维向量与真实图像的对应S*S*(B*5 + C)维向量的均方和误差。如下式所示:

其中,coordError、iouError和classError分别代表预测数据与标定数据之间的坐标误差、IOU误差和分类误差。
a) 8维的localization error和20维的classification error同等重要显然是不合理的;
b) 如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。解决方案如下:

对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏一点更不能忍受。而sum-square error loss中对同样的偏移loss是一样。 为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。 如下图:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大。
注:小框的loss要比大框的loss大很多。

一个网格预测多个bounding box,在训练时我们希望每个object(ground true box)只有一个bounding box专门负责(一个object 一个bbox)。具体做法是与ground true box(object)的IOU最大的bounding box负责该ground true box(object)的预测。这种做法称作bounding box predictor的specialization(专职化)。每个预测器会对特定(sizes,aspect ratio or classed of object)的ground true box预测的越来越好。(个人理解:IOU最大者偏移会更少一些,可以更快速的学习到正确位置)
特别注意:
1、YOLO方法模型训练依赖于物体识别标注数据,因此,对于非常规的物体形状或比例,YOLO的检测效果并不理想。
2、YOLO采用了多个下采样层,网络学到的物体特征并不精细,因此也会影响检测效果。
3、YOLO loss函数中,大物体IOU误差和小物体IOU误差对网络训练中loss贡献值接近(虽然采用求平方根方式,但没有根本解决问题)。因此,对于小物体,小的IOU误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性。
网络测试

对每一个网格的每一个bbox执行同样操作: 7x7x2 = 98 bbox (每个bbox既有对应的class信息又有坐标信息)
得到每个bbox的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
区别与two stage的检测网络,YOLO除了速度快外最为典型的优势就是能够感知上下文信息,感受野通常为全图,因此其泛化能力会更好,同时会大量降低对于背景的错误Recall。如下图,YOLO对背景内容的误判率(4.75%)比fast rcnn的误判率(13.6%)低很多。但是YOLO的定位准确率较差,占总误差比例的19.0%,而fast rcnn仅为8.6%。

优点:
1、YOLO比Faster R-CNN的速度提高了一倍以上,但是MAP略有下降;
2、能够感知上下文信息,感受野通常为全图,因此其泛化能力会更好,同时YOLO在训练和推理过程中能‘看到’整张图像的整体信息,使得误检率降低(不易检测到背景);
3、泛化能力要明显优于two stage网络。
缺点:
- 易漏检:比较致命的伤在于珊格划分的方式,所以一张图最多只能回归出S*S个目标,因此对于小目标及密集目标效果肯定会差。每个grid 只预测一个类别的 Bounding Boxes,而且最后只取置信度最大的那个Box。这就导致如果多个不同物体(或者同类物体的不同实体)的中心落在同一个网格中,会造成漏检;
- 定位精度低:另外相比于先Proposal 超多的框然后NMS合并,这种方式在与边缘准确率就完全依赖回归效果了,预测的 Box 对于尺度的变化比较敏感,因此边界不会特别准确,在尺度上的泛化能力比较差(由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是对小物体的处理上,还有待加强);
- 测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
改进
为提高物体定位精准性和召回率,YOLO作者提出了YOLO9000,提高训练图像的分辨率,引入了faster rcnn中anchor box的思想,对各网络结构及各层的设计进行了改进,输出层使用卷积层替代YOLO的全连接层,相比YOLO,YOLO9000在识别种类、精度、速度、和定位准确性等方面都有大大提升。
问题
在训练过程中,网格所预测的两个黄色的bounding boxes是怎样生成的?
YOLO中两个bbox是人为选定的(2个不同 长宽比)的box,Faster RCNN也是人为选定的(9个 不同长宽比和scale),YOLOv2是统计分析ground true box的特点得到的(5个)。YOLO是直接回归真实坐标,而Faster是回归偏移量。
论文:You Only Look Once: Unified, Real-Time Object Detection
参考资料:
https://zhuanlan.zhihu.com/p/24916786
https://zhuanlan.zhihu.com/p/87590466
https://zhuanlan.zhihu.com/p/25236464
