最近工作在做一个推荐系统,之前也有用TensorFlow写过一个,后来学习了spark,觉得用spark来做这个推荐系统应该会更简单一些,在这里,我们一起来学习一下用pandas和spark做推荐系统。我们的数据源是后台收集的用户听了哪些歌手的歌曲,我们数据的同学将清洗好的歌手数据给到我之后,是这个样子的:
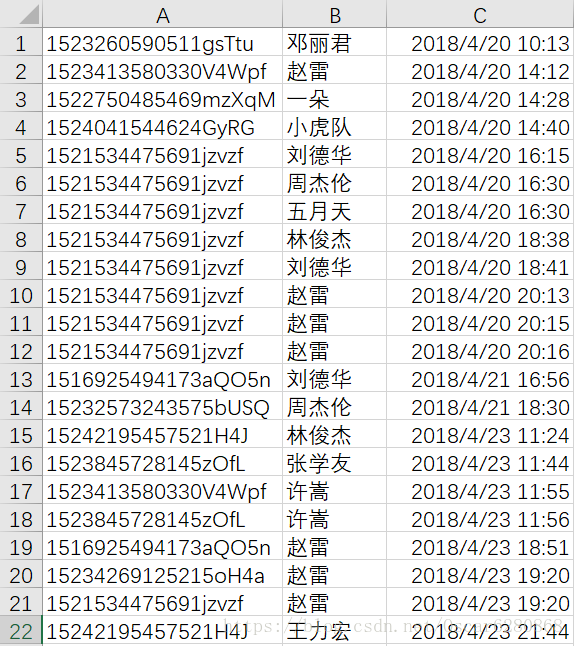
这是部分用户听过的歌手数据,基本也都是一些测试的数据,A列表示我们用户的后台ID,B列表示用户所听的歌手,C列表示用户听歌的时间。拿到这些数据,首先就要思考一下如何来使用这些数据,我的认为是用户听某个歌手的频次越高,就代表这个用户越喜欢这个歌手,暂且就把听某个歌手的频次作为这个用户对这个歌手的评分。首先,我们要对这个原始的数据进行预处理,这里我们运用的是pandas。首先我们运用pandas读取我们的.csv数据并且给与每一列命名:
singer_recom = pd.read_csv("dataset/singer.csv", header = None, encoding = 'gbk', names = ['UserTitle', 'SingerTitle', 'Date'])然后我们可以看看这个列表:
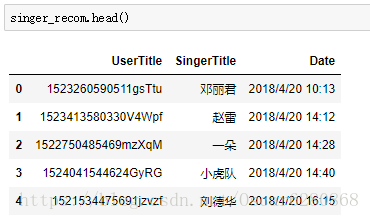
读取了这些数据之后,我们可以去掉重复的数据:
singer3 = singer_recom.drop_duplicates(subset = 'UserTitle', keep = 'first')去掉重复数据之后,我们给每一个用户ID分配一个int型的ID,并创建一个用户和歌手的列表,方便后续的计算:
singer3['UserID'] = range(0, singer3.shape[0])
columns = ["UserTitle", "UserID"]
singer_user = singer3[columns]我们来看看分配了数据之后的用户ID:
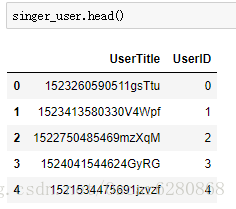
可以看到我们给每一个用户的UserTitle都分配了一个UserID,接着我们将user_id转化成一维数组,索引对象是我们的user,在这里我们用的是pandas 的Series:
user = singer_user['UserTitle'].values
user_id = singer_user['UserID'].values
series_custom = Series(user_id, index = user)然后我们再将UserID添加在原有的列表中的最后一列:
trans_id = []
for i in singer_recom["UserTitle"]:
trans_id.append(series_custom[i])
singer_recom["UserID"] = trans_id我们可以得到新的列表,这个列表中心添加了一列UserID:
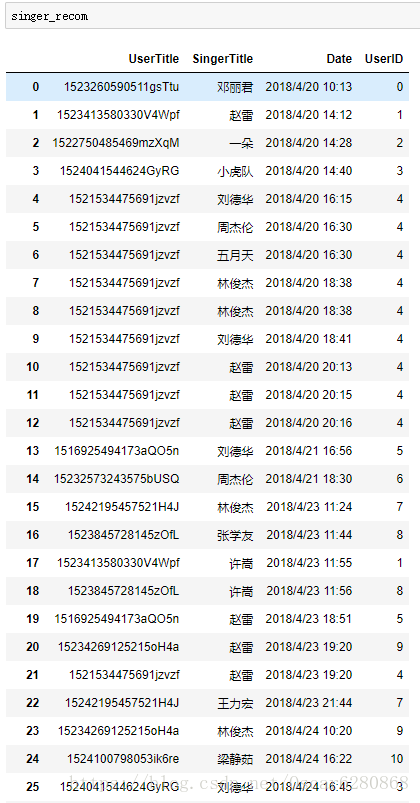
这个列表中,最后一列表示UserTitle映射的UserID,然后我们再次将这份数据去掉重复的部分,前面我们对用户的ID进行了映射,同样因为歌手名也是字符串类型的,为了方便处理,我们同样要像上述那样来对歌手名分配相应的ID,代码如下:
singer4 = singer_recom.drop_duplicates(subset='SingerTitle', keep = 'first')
singer4['SingerID'] = range(0, singer4.shape[0])
columns = ["SingerTitle", "SingerID"]
singer_singer = singer4[columns]处理之后,我们可以得到映射ID之后的歌手ID:
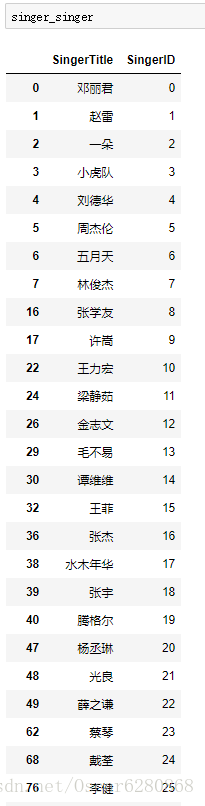
当然了,这张图只是部分歌手的ID映射,同样的道理,我们要讲歌手ID这一列加入到原来的数据列表中,于是我们可以进行如下的操作:
singer = singer_singer['SingerTitle'].values
singer_id = singer_singer['SingerID'].values
series_custom = Series(singer_id,index=singer)
trans_singer = []
for i in singer_recom["SingerTitle"]:
trans_singer.append(series_custom[i])
singer_recom["SingerID"] = trans_singer操作完成之后我们添加了”SingerID”这一列的数据,如下图所示:
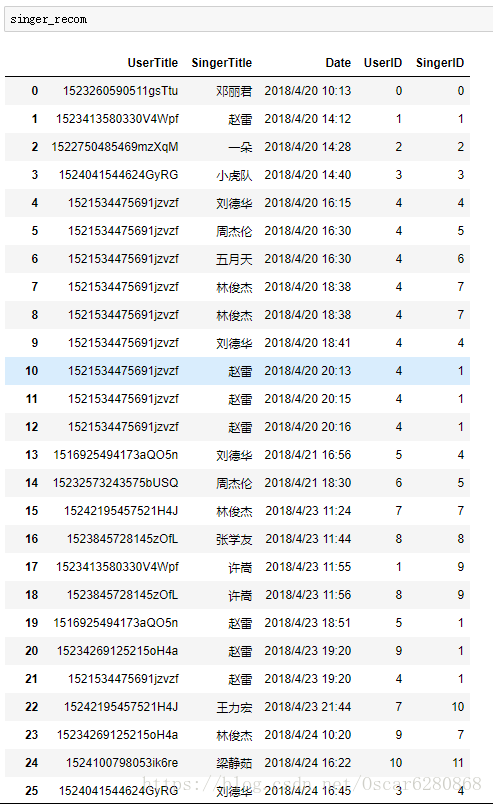
当然这只是一部分的数据,我们可以看到最后一列添加了歌手的ID值,接下来我们根据用户和歌手的ID对这些数据进行排序:
singer_recom = singer_recom.sort_values(["UserID", "SingerID"], inplace = False)在排序之后,我们可以得到一个完整的歌手和用户的数据列表:
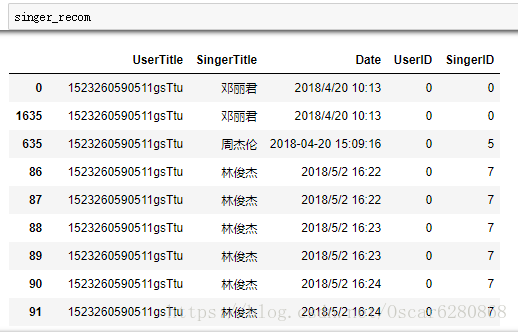
在得到这个完整的数据列表之后,我们并不是所有的数据都需要的,所以接下来我们保留有用的特征数据,将UserID和SingerID进行聚合操作,这里用到的是聚合函数pandas中的groupby:
target = singer_recom.groupby(['UserID', 'SingerID']).size().reset_index()在聚合了UserID和SingerID之后,我们可以用reset_index()函数将groupby之后的数据使用size()方法统计使用评率之后,转换成DataFrame对象,处理之后我们可以得到如下结果:
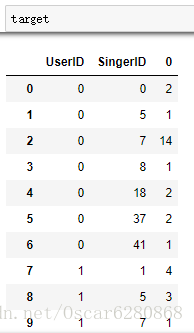
然后我们可以将每个歌手的频次标注出来,然后听的歌手的频次就是我们对这个歌手的打分,打分系统是一个复杂的系统,我们暂且很简单地认为用户听哪个歌手的歌多,就对这个歌手的评分就高:
target.columns = ['UserID', 'SingerID', 'Rating']最后我们可以得到含有打分项的列表:
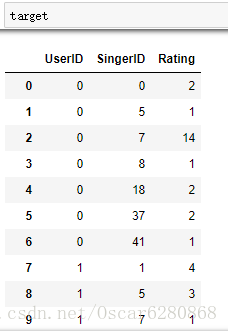
为了方便我们对照歌手名,我们将歌手名和用户名merge到这张表中来:
df_user = pd.merge(target, singer_singer, on = 'SingerID', how = 'left', suffixes = ('_', ''))
df_user = pd.merge(df_user, singer_user, on = 'UserID', how = 'left', suffixes = ('_', ''))在merge完成之后,我们的数据预处理就完成了,就可以得到我们需要的数据格式了,然后我们把预处理完成之后的.csv数据储存起来:
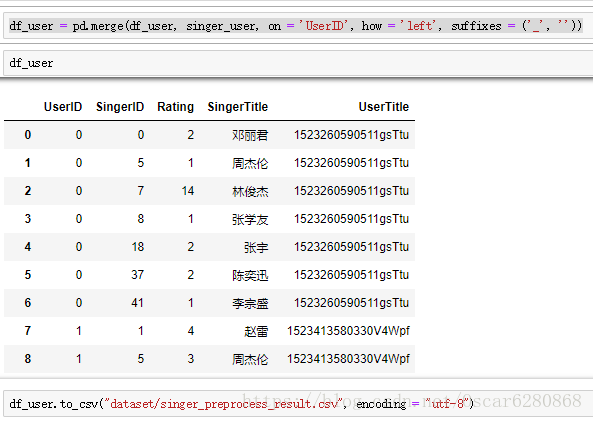
上面就是我们拿到数据之后到预处理完成之后的过程,接下来我们就是进行推荐算法的实现,这里我们用到的是pyspark,首先我们导入pyspark库,然后读取我们已经经过预处理之后的数据:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("singer_recommendation").master("local").getOrCreate()
df = spark.read.format('com.databricks.spark.csv').options(header = 'true', inferschema = 'true').load("dataset/singer_preprocess_result.csv")在导入了数据之后,我们再来进行特征的提取,在spark中直接可以使用select()方法:
df_singer_recommend = df.select("UserID", "SingerID", "Rating")在进行完特征提取之后,我们这里就要用到spark的rdd了,什么是RDD?RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度,创建rdd的代码如下:
singer_rdd = df_singer_recommend.rdd
trainingRDD = singer_rdd.cache()这里运用到了rdd的缓存cache方法,这样可以将rdd缓存到磁盘或者内存中,以便于后续的复用。准备好了这些之后,我们就可以开始训练模型了,首先我们要导入spark的库:
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating这里用到的是pyspark库中的ALS算法,关于ALS算法,我稍后会再发布一篇博文再细说这个推荐算法,这里我们就暂且理解这是一个推荐系统的算法,然后我们就可以去训练一个推荐系统的模型:
rank = 10
numIterations = 10
model = ALS.train(trainingRDD, rank, numIterations)这里我们来看看ALS中的train方法,这里的rank表示隐藏因子的个数,numIterations表示迭代的次数,然后trainingRDD表示我们训练的数据源,这是我们pyspark中的API,很方便使用的,然后训练完了之后我们就可以得到我们的模型model,这里我们再来简单地看看ALS算法是怎么一回事,ALS算法其实是交替最小二乘法,比如用户听歌,如果每个歌手都是一个维度,但是用户只会去听部分自己喜欢的歌手的歌,所以在这整个矩阵中,只会有很小的一部分会有值,大部分的地方都是没有值的,我们就认为这个矩阵就是一个稀疏矩阵,然后我们要想办法将这个矩阵的数据填满,让她形成一个稠密的矩阵,操作起来就是说通过降维的方法来补全矩阵,对矩阵没有出现的值进行估值,场用的方法就是SVD(奇异值分解),这个方法在矩阵分解之前需要先把评分矩阵R缺失值补全,补全之后稀疏矩阵R矩阵表示成稠密矩阵R’,然后我们可以将R’矩阵进行分解成:
在这个公式中,假如R’是一个m x n的矩阵,那么可以分解成,U矩阵的转秩m x k,S矩阵k x s,和V矩阵s x n矩阵相乘,这个公式中,选取U中的K列和V中的s行作为隐特征数,从而达到降维的目的。ALS推荐算法大概的思想就是这个样子,我后续会写一篇关于ALS的算法的详细介绍,大家一起学习,这里就点到为止。接下来我们定义一个方法来返回top5的商品ID:
def top5_productID(userID):
recommendedResult = model.recommendProducts(userID, 5)
product_id_list = []
for i in range(5):
product_id_list.append(recommendedResult[i].product)
return product_id_list这里就是利用spark的API中的recommendProducts方法来返回排名最高的5个商品ID。有了这个list,我们再来构建一个dataframe:
def construct_dataframeData(userList):
data = []
for user in userList:
res = top5_productID(user)
res.insert(0, user)
data.append(res)
return data通过这个方法,我们就可以将每一个用户推荐的5个商品,也就是将每一个用户所推荐的5个歌手插入到dataframe中:
data = construct_dataframeData(unique_userid_list)接着我们可以得到一个结构体dataframe:

这个就是我们推荐结果矩阵中的一部分结果,第一个数字表示用户的UserID,后面的5个数字表示推荐给用户的SingerID,其实这个矩阵就相当于是我们的推荐结果,我们接下来需要做的就是将这个矩阵解析成我们可以看得懂的文本矩阵输出。所以我们再写一个方法,将我们数字的矩阵映射成文本的矩阵结果输出:
def parse_data(dataList):
res = []
for item in dataList:
res_item = []
UserTitle = df.filter(df['UserID'] == item[0]).select("UserTitle").collect()[0].UserTitle
res_item.append(UserTitle)
for i in range(1, 6):
SingerTitle = df.filter(df['SingerID'] == item[i]).select("SingerTitle").collect()[0].SingerTitle
res_item.append(SingerTitle)
res.append(res_item)
return res通过这个方法,我们将数字矩阵可以转化成文本矩阵,我们来看看最终推荐的部分结果吧:

这样就可以看到每一个用户所对用的最喜欢的5个歌手,所以我们就得到了推荐最终的结果,我们可以将这些结果导出成.csv:
df_res = pd.DataFrame(parseData, columns = ['UserTitle', 'SingerName1', 'SingerName2', 'SingerName3', 'SingerName4', 'SingerName5'])
df_res.to_csv("singer_recommend_result.csv", index=False, encoding="utf-8")有了这个推荐列表,我们可以将这个列表上线到我们的后台服务中去。到这里我们就可以说利用spark完成了一个完整的歌手推荐系统,希望这篇精心的博文能够对大家的数据预处理以及推荐系统的设计实现,有了一个新的认识,新的启发,对大家的推荐系统理解有所帮助。本人能力有限,如在博文内容中有所纰漏,还望大家不吝指教,如果有转载,也请标明博文出处,蟹蟹。