在读HDFS文件前,需要先open该文件,这个调用的是org.apache.hadoop.fs.FileSystem类对象,但是由于实际创建的对象是org.apache.hadoop.hdfs.DistributedFileSystem类对象,后者是前者的子类,所以调用父类中的FSDataInputStream open(Path f, int bufferSize)函数最终会调用到子类的该函数中,也就是说会调用org.apache.hadoop.hdfs.DistributedFileSystem类中的FSDataInputStream open(Path f, int bufferSize)函数,我们进入到该函数中,代码如下:
@Override
public FSDataInputStream open(Path f, final int bufferSize)
throws IOException {
//添加读操作次数
statistics.incrementReadOps(1);
//获取绝对路径对应的Path类对象
Path absF = fixRelativePart(f);
return new FileSystemLinkResolver<FSDataInputStream>() {
@Override
public FSDataInputStream doCall(final Path p)
throws IOException, UnresolvedLinkException {
final DFSInputStream dfsis =
dfs.open(getPathName(p), bufferSize, verifyChecksum);
return dfs.createWrappedInputStream(dfsis);
}
@Override
public FSDataInputStream next(final FileSystem fs, final Path p)
throws IOException {
return fs.open(p, bufferSize);
}
}.resolve(this, absF);
}我们看代码的第一行,首先分析一下statistics,这是一个FileSystem中的成员变量,定义代码如下:
protected Statistics statistics;
Statistics类是FileSystem类中的内部类,用来统计一些数据。
赋值是在public void initialize(URI name, Configuration conf) throws IOException函数中,这个函数是在创建org.apache.hadoop.hdfs.DistributedFileSystem类对象之后调用的,用来初始化,代码如下:
/** Called after a new FileSystem instance is constructed.
* @param name a uri whose authority section names the host, port, etc.
* for this FileSystem
* @param conf the configuration
*/
public void initialize(URI name, Configuration conf) throws IOException {
statistics = getStatistics(name.getScheme(), getClass());
resolveSymlinks = conf.getBoolean(
CommonConfigurationKeys.FS_CLIENT_RESOLVE_REMOTE_SYMLINKS_KEY,
CommonConfigurationKeys.FS_CLIENT_RESOLVE_REMOTE_SYMLINKS_DEFAULT);
}我们进入到函数getStatistics中,代码如下:
/**
* Get the statistics for a particular file system
* @param cls the class to lookup
* @return a statistics object
*/
//这个函数是一个同步函数,scheme为协议名称(如http,https,hdfs等)
//cls为对应的Class对象
public static synchronized
Statistics getStatistics(String scheme, Class<? extends FileSystem> cls) {
/* Recording statistics per a FileSystem class
//statisticsTable是FileSystem中的一个静态成员变量,
private static final Map<Class<? extends FileSystem>, Statistics>
statisticsTable = new IdentityHashMap<Class<? extends FileSystem>, Statistics>();
*/
//先判断该map中是否存在key为Class对象的元素
Statistics result = statisticsTable.get(cls);
//如果没有
if (result == null) {
//那么就创建Statistics类对象
result = new Statistics(scheme);
//将该Statistics类对象与Class对象关联起来
statisticsTable.put(cls, result);
}
//否则直接返回
return result;
}回到函数open,我们继续往下分析,代码如下:
return new FileSystemLinkResolver<FSDataInputStream>() {
@Override
public FSDataInputStream doCall(final Path p)
throws IOException, UnresolvedLinkException {
final DFSInputStream dfsis =
dfs.open(getPathName(p), bufferSize, verifyChecksum);
return dfs.createWrappedInputStream(dfsis);
}
@Override
public FSDataInputStream next(final FileSystem fs, final Path p)
throws IOException {
return fs.open(p, bufferSize);
}
}.resolve(this, absF);这里首先创建一个匿名内部类(必须继承一个了类或者实现某个接口,匿名内部类详细介绍),该内部类继承FileSystemLinkResolver<FSDataInputStream>类,我们进入到resolve函数,由于匿名内部类没有重载该函数,那么就会调用父类的,进入到该函数中,代码如下:
/**
* Attempt calling overridden {@link #doCall(Path)} method with
* specified {@link FileSystem} and {@link Path}. If the call fails with an
* UnresolvedLinkException, it will try to resolve the path and retry the call
* by calling {@link #next(FileSystem, Path)}.
* @param filesys FileSystem with which to try call
* @param path Path with which to try call
* @return Generic type determined by implementation
* @throws IOException
*/
public T resolve(final FileSystem filesys, final Path path)
throws IOException {
int count = 0;
T in = null;
Path p = path;
// Assumes path belongs to this FileSystem.
// Callers validate this by passing paths through FileSystem#checkPath
FileSystem fs = filesys;
for (boolean isLink = true; isLink;) {
try {
//调用doCall函数,这个函数会调用继承了FileSystemLinkResolver<FSDataInputStream>的匿名
//类中的doCall函数
in = doCall(p);
isLink = false;
} catch (UnresolvedLinkException e) {//如果调用doCall函数抛出了不能解析链接的异常
if (!filesys.resolveSymlinks) {//如果不能使用软链接,那么抛出异常,提示要打开的目录包
//含了软链接,而系统配置中关闭了解析软链接的支持
throw new IOException("Path " + path + " contains a symlink"
+ " and symlink resolution is disabled ("
+ CommonConfigurationKeys.FS_CLIENT_RESOLVE_REMOTE_SYMLINKS_KEY
+ ").", e);
}
if (!FileSystem.areSymlinksEnabled()) {
throw new IOException("Symlink resolution is disabled in" +
" this version of Hadoop.");
}
//FsConstants.MAX_PATH_LINKS为最大解析软链接的递归次数
if (count++ > FsConstants.MAX_PATH_LINKS) {
throw new IOException("Possible cyclic loop while " +
"following symbolic link " + path);
}
// Resolve the first unresolved path component
//解析第一个不能解析的路径
//fs.getUri()返回namenode对应的URI类对象,里面是namenode的访问地址,p是Path类对象,里
//面存储了要打开文件的路径信息,
p = FSLinkResolver.qualifySymlinkTarget(fs.getUri(), p,
filesys.resolveLink(p));
fs = FileSystem.getFSofPath(p, filesys.getConf());
// Have to call next if it's a new FS
if (!fs.equals(filesys)) {
return next(fs, p);
}
// Else, we keep resolving with this filesystem
}
}
// Successful call, path was fully resolved
return in;
}这里使用到了HDFS的软链接和硬链接知识,这个跟linux的软链接和硬链接相同,关于这个概念可以查看软链接和硬链接,这里不再赘述。我们下面来分析一下filesys.resolveLink(p)代码,这个函数是调用DistributedFileSystem类中的,用来解析软链接,函数代码如下:
@Override
protected Path resolveLink(Path f) throws IOException {
statistics.incrementReadOps(1);
//getPathName用来获取文件路径,getLinkTarget用来解析软链接
String target = dfs.getLinkTarget(getPathName(fixRelativePart(f)));
if (target == null) {
throw new FileNotFoundException("File does not exist: " + f.toString());
}
return new Path(target);
}我们进入到getLinkTarget函数中,代码如下:
/**
* Resolve the *first* symlink, if any, in the path.
*
* @see ClientProtocol#getLinkTarget(String)
*/
public String getLinkTarget(String path) throws IOException {
checkOpen();
try {
//这里最终会调用namenode中的对应函数,而namenode是一个代理对象
return namenode.getLinkTarget(path);
} catch (RemoteException re) {
throw re.unwrapRemoteException(AccessControlException.class,
FileNotFoundException.class);
}
}关于namenode这个代理对象的由来我们前面章节已经介绍过了,我这边在此总结一下:
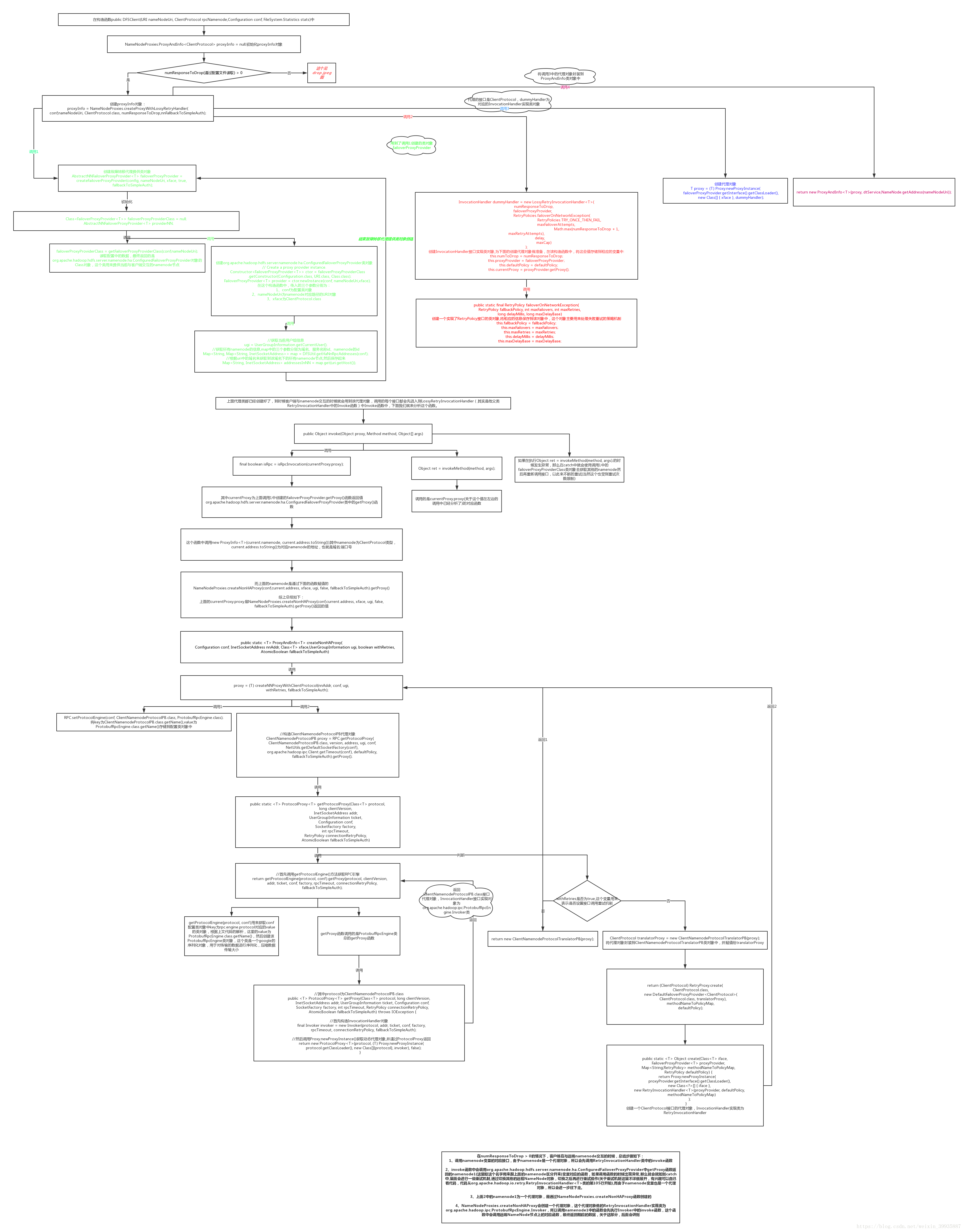
DFSClient.jpeg
上图中的drop.jpeg如下:
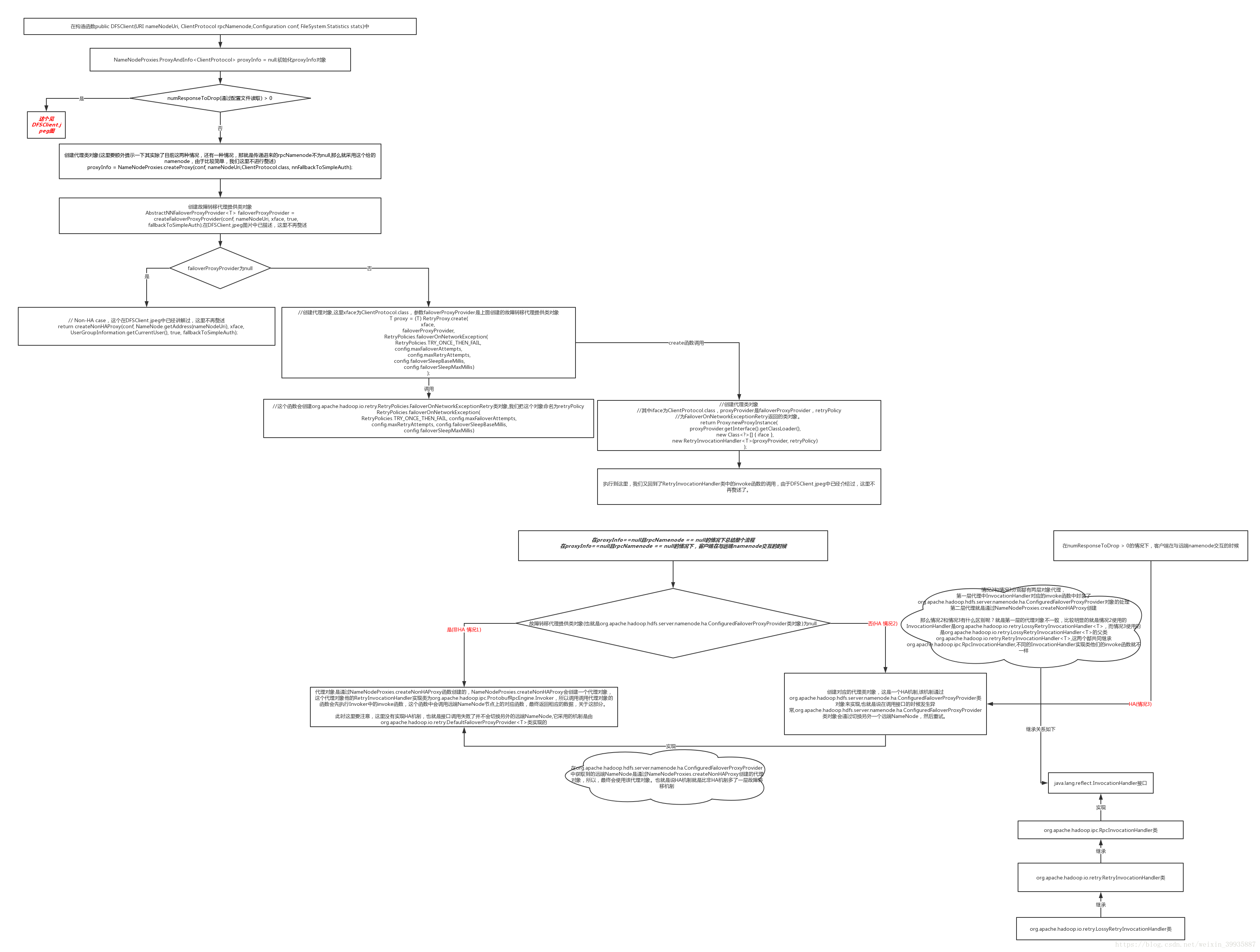
至此namenode这个代理对象的由来我们就总结到这里,下面我们继续往下分析。
namenode.getLinkTarget函数会调用ClientNamenodeProtocolTranslatorPB类中的getLinkTarget函数,而该函数如下:
@Override
public String getLinkTarget(String path) throws AccessControlException,
FileNotFoundException, IOException {
GetLinkTargetRequestProto req = GetLinkTargetRequestProto.newBuilder()
.setPath(path).build();
try {
GetLinkTargetResponseProto rsp = rpcProxy.getLinkTarget(null, req);
return rsp.hasTargetPath() ? rsp.getTargetPath() : null;
} catch (ServiceException e) {
throw ProtobufHelper.getRemoteException(e);
}
}其中的rpcProxy是ClientNamenodeProtocolPB类的代理对象,而该代理对象在调用接口函数的时候会先调用org.apache.hadoop.ipc.ProtobufRpcEngine.Invoker类中的invoke函数,这个函数会先将调用信息序列化,然后通过RPC将数据发送到远端namenode端,namenode端收到消息后,会先反序列化,然后解析信息,并调用相应的函数,并将函数执行结果序列化,再将序列化数据通过RPC返回客户端。我们看看invoke函数,代码如下:
/**
* This is the client side invoker of RPC method. It only throws
* ServiceException, since the invocation proxy expects only
* ServiceException to be thrown by the method in case protobuf service.
*
* ServiceException has the following causes:
* <ol>
* <li>Exceptions encountered on the client side in this method are
* set as cause in ServiceException as is.</li>
* <li>Exceptions from the server are wrapped in RemoteException and are
* set as cause in ServiceException</li>
* </ol>
*
* Note that the client calling protobuf RPC methods, must handle
* ServiceException by getting the cause from the ServiceException. If the
* cause is RemoteException, then unwrap it to get the exception thrown by
* the server.
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws ServiceException {
long startTime = 0;
if (LOG.isDebugEnabled()) {
startTime = Time.now();
}
if (args.length != 2) { // RpcController + Message
throw new ServiceException("Too many parameters for request. Method: ["
+ method.getName() + "]" + ", Expected: 2, Actual: "
+ args.length);
}
if (args[1] == null) {
throw new ServiceException("null param while calling Method: ["
+ method.getName() + "]");
}
TraceScope traceScope = null;
// if Tracing is on then start a new span for this rpc.
// guard it in the if statement to make sure there isn't
// any extra string manipulation.
if (Trace.isTracing()) {
traceScope = Trace.startSpan(
method.getDeclaringClass().getCanonicalName() +
"." + method.getName());
}
//构造请求头域,标明在上面接口上调用上面方法
RequestHeaderProto rpcRequestHeader = constructRpcRequestHeader(method);
if (LOG.isTraceEnabled()) {
LOG.trace(Thread.currentThread().getId() + ": Call -> " +
remoteId + ": " + method.getName() +
" {" + TextFormat.shortDebugString((Message) args[1]) + "}");
}
//获取请求调用的参数,例如RenameRequestProto
Message theRequest = (Message) args[1];
final RpcResponseWrapper val;
try {
//调用PRC.Client发送请求
val = (RpcResponseWrapper) client.call(RPC.RpcKind.RPC_PROTOCOL_BUFFER,
new RpcRequestWrapper(rpcRequestHeader, theRequest), remoteId,
fallbackToSimpleAuth);
} catch (Throwable e) {
if (LOG.isTraceEnabled()) {
LOG.trace(Thread.currentThread().getId() + ": Exception <- " +
remoteId + ": " + method.getName() +
" {" + e + "}");
}
if (Trace.isTracing()) {
traceScope.getSpan().addTimelineAnnotation(
"Call got exception: " + e.getMessage());
}
throw new ServiceException(e);
} finally {
if (traceScope != null) traceScope.close();
}
if (LOG.isDebugEnabled()) {
long callTime = Time.now() - startTime;
LOG.debug("Call: " + method.getName() + " took " + callTime + "ms");
}
Message prototype = null;
try {
//获取返回参数类型,RenameResponseProto
prototype = getReturnProtoType(method);
} catch (Exception e) {
throw new ServiceException(e);
}
Message returnMessage;
try {
//序列化响应信息并返回
returnMessage = prototype.newBuilderForType()
.mergeFrom(val.theResponseRead).build();
if (LOG.isTraceEnabled()) {
LOG.trace(Thread.currentThread().getId() + ": Response <- " +
remoteId + ": " + method.getName() +
" {" + TextFormat.shortDebugString(returnMessage) + "}");
}
} catch (Throwable e) {
throw new ServiceException(e);
}
//返回结果
return returnMessage;
}将调用的函数和参数封装到对应的类对象中后,使用PRC发送请求到远程namenode端。代码如下:
//调用PRC.Client发送请求
val = (RpcResponseWrapper) client.call(RPC.RpcKind.RPC_PROTOCOL_BUFFER,
new RpcRequestWrapper(rpcRequestHeader, theRequest), remoteId,
fallbackToSimpleAuth);其中RPC.RpcKind是一个枚举,里面元素为序列化方式,这里RPC.RpcKind.RPC_PROTOCOL_BUFFER表示使用ProtobufRpcEngine类中的序列化方式。new RpcRequestWrapper(rpcRequestHeader, theRequest)用来将函数和参数存储到RpcRequestWrapper类对象中。这里我们先来看看client的由来,client是一个org.apache.hadoop.ipc.Client类对象,构造函数如下:
/** Construct an IPC client whose values are of the given {@link Writable}
* class. */
//valueClass为继承Writable的类对应的Class对象
//conf为配置文件对象
//factory为一个创建Socket类对象的工厂类对象
public Client(Class<? extends Writable> valueClass, Configuration conf,
SocketFactory factory) {
this.valueClass = valueClass;
this.conf = conf;
this.socketFactory = factory;
this.connectionTimeout = conf.getInt(CommonConfigurationKeys.IPC_CLIENT_CONNECT_TIMEOUT_KEY,
CommonConfigurationKeys.IPC_CLIENT_CONNECT_TIMEOUT_DEFAULT);
this.fallbackAllowed = conf.getBoolean(CommonConfigurationKeys.IPC_CLIENT_FALLBACK_TO_SIMPLE_AUTH_ALLOWED_KEY,
CommonConfigurationKeys.IPC_CLIENT_FALLBACK_TO_SIMPLE_AUTH_ALLOWED_DEFAULT);
this.clientId = ClientId.getClientId();
this.sendParamsExecutor = clientExcecutorFactory.refAndGetInstance();
}根据上面的逻辑,factory通过NetUtils.getDefaultSocketFactory(conf)产生,该函数代码如下:
/**
* Get the default socket factory as specified by the configuration
* parameter <tt>hadoop.rpc.socket.factory.default</tt>
*
* @param conf the configuration
* @return the default socket factory as specified in the configuration or
* the JVM default socket factory if the configuration does not
* contain a default socket factory property.
*/
public static SocketFactory getDefaultSocketFactory(Configuration conf) {
String propValue = conf.get(
CommonConfigurationKeysPublic.HADOOP_RPC_SOCKET_FACTORY_CLASS_DEFAULT_KEY,
CommonConfigurationKeysPublic.HADOOP_RPC_SOCKET_FACTORY_CLASS_DEFAULT_DEFAULT);
if ((propValue == null) || (propValue.length() == 0))
return SocketFactory.getDefault();
return getSocketFactoryFromProperty(conf, propValue);
}该函数会返回一个工厂类对象,这个工厂类对象会创建Socket类对象,用来客户端和远程namenode端通讯。我们看一下创建Socket类对象的代码:
@Override
public Socket createSocket() throws IOException {
/*
* NOTE: This returns an NIO socket so that it has an associated
* SocketChannel. As of now, this unfortunately makes streams returned
* by Socket.getInputStream() and Socket.getOutputStream() unusable
* (because a blocking read on input stream blocks write on output stream
* and vice versa).
*
* So users of these socket factories should use
* NetUtils.getInputStream(socket) and
* NetUtils.getOutputStream(socket) instead.
*
* A solution for hiding from this from user is to write a
* 'FilterSocket' on the lines of FilterInputStream and extend it by
* overriding getInputStream() and getOutputStream().
*/
return SocketChannel.open().socket();
}java.nio.channels.SocketChannel这个类是java的NIO提供的,关于NIO我们后面会讲到。
我们继续往下,进入到client.call函数中,代码如下:
/**
* Make a call, passing <code>rpcRequest</code>, to the IPC server defined by
* <code>remoteId</code>, returning the rpc response.
*
* @param rpcKind
* @param rpcRequest - contains serialized method and method parameters
* @param remoteId - the target rpc server
* @param serviceClass - service class for RPC
* @param fallbackToSimpleAuth - set to true or false during this method to
* indicate if a secure client falls back to simple auth
* @returns the rpc response
* Throws exceptions if there are network problems or if the remote code
* threw an exception.
*/
public Writable call(RPC.RpcKind rpcKind, Writable rpcRequest,
ConnectionId remoteId, int serviceClass,
AtomicBoolean fallbackToSimpleAuth) throws IOException {
//构造Call对象,并将序列化类型信息、函数和参数信息封装到Call类对象中
final Call call = createCall(rpcKind, rpcRequest);
//构造Connection对象,首先会根据remoteId到缓存中去取,如果没有找到那么就创建一个对象,同时将该对象保存到缓存中去,方便下次使用。
Connection connection = getConnection(remoteId, call, serviceClass,
fallbackToSimpleAuth);
try {
connection.sendRpcRequest(call); // send the rpc request
} catch (RejectedExecutionException e) {
throw new IOException("connection has been closed", e);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
LOG.warn("interrupted waiting to send rpc request to server", e);
throw new IOException(e);
}
boolean interrupted = false;
synchronized (call) {
while (!call.done) {
try {
call.wait(); // wait for the result
} catch (InterruptedException ie) {
// save the fact that we were interrupted
interrupted = true;
}
}
if (interrupted) {
// set the interrupt flag now that we are done waiting
Thread.currentThread().interrupt();
}
//提取出Call对象中保存的异常,直接抛出
if (call.error != null) {
if (call.error instanceof RemoteException) {
call.error.fillInStackTrace();
throw call.error;
} else { // local exception
InetSocketAddress address = connection.getRemoteAddress();
throw NetUtils.wrapException(address.getHostName(),
address.getPort(),
NetUtils.getHostname(),
0,
call.error);
}
} else {//如果成功执行,则返回Call对象中保存的RPC响应消息
//服务器成功发回响应信息,返回RPC响应
return call.getRpcResponse();
}
}
}call函数中调用createCall函数,该函数代码如下:
Call createCall(RPC.RpcKind rpcKind, Writable rpcRequest) {
return new Call(rpcKind, rpcRequest);
}这个函数用来创建一个Call类对象,我们进入到Call的构造函数中,代码如下:
private Call(RPC.RpcKind rpcKind, Writable param) {
this.rpcKind = rpcKind;//序列化类型
this.rpcRequest = param;//函数和参数封装类对象
//callId的创建代码为
//private static final ThreadLocal<Integer> callId = new ThreadLocal<Integer>();
final Integer id = callId.get();
if (id == null) {
this.id = nextCallId();
} else {
callId.set(null);
this.id = id;
}
//retryCount的创建代码为
//private static final ThreadLocal<Integer> retryCount = new ThreadLocal<Integer>();
final Integer rc = retryCount.get();
if (rc == null) {
this.retry = 0;
} else {
this.retry = rc;
}
}关于ThreadLocal的详解请看,ThreadLocal类详解
关于java中引用的详解,java引用详解
我们继续回到call函数中,继续进行讲解,执行代码如下:
connection.sendRpcRequest(call); 我们进入到sendRpcRequest函数中,代码如下:
/** Initiates a rpc call by sending the rpc request to the remote server.
* Note: this is not called from the Connection thread, but by other
* threads.
* @param call - the rpc request
*/
public void sendRpcRequest(final Call call)
throws InterruptedException, IOException {
//判断连接是否关闭了,如果关闭了,那么就直接返回,就无需执行下面的代码
if (shouldCloseConnection.get()) {
return;
}
// Serialize the call to be sent. This is done from the actual
// caller thread, rather than the sendParamsExecutor thread,
// so that if the serialization throws an error, it is reported
// properly. This also parallelizes the serialization.
//
// Format of a call on the wire:
// 0) Length of rest below (1 + 2)
// 1) RpcRequestHeader - is serialized Delimited hence contains length
// 2) RpcRequest
//
// Items '1' and '2' are prepared here.
//先构造RPC请求头
final DataOutputBuffer d = new DataOutputBuffer();
RpcRequestHeaderProto header = ProtoUtil.makeRpcRequestHeader(
call.rpcKind, OperationProto.RPC_FINAL_PACKET, call.id, call.retry,
clientId);
//将RPC请求头写入输出流
header.writeDelimitedTo(d);
//将RPC请求(包括请求元数据和请求参数)写入输出流
call.rpcRequest.write(d);
//这里使用线程池将请求发送出去,请求包括三个部分:1、长度 2、PRC请求头 3、RPC请求(包括请求元数据以及请求参数)
synchronized (sendRpcRequestLock) {
Future<?> senderFuture = sendParamsExecutor.submit(new Runnable() {
@Override
public void run() {
try {
synchronized (Connection.this.out) {
if (shouldCloseConnection.get()) {
return;
}
if (LOG.isDebugEnabled())
LOG.debug(getName() + " sending #" + call.id);
byte[] data = d.getData();
int totalLength = d.getLength();
out.writeInt(totalLength); // Total Length 总长度
out.write(data, 0, totalLength);// RpcRequestHeader + RpcRequest RPC请求头+RPC请求(请求元数据+参数)
out.flush();
}
} catch (IOException e) {
// exception at this point would leave the connection in an
// unrecoverable state (eg half a call left on the wire).
// So, close the connection, killing any outstanding calls
//如果发生发送异常,则直接关闭连接
markClosed(e);
} finally {
//the buffer is just an in-memory buffer, but it is still polite to
// close early
//之前申请的buffer给关闭了,比较优雅
IOUtils.closeStream(d);
}
}
});
//获取执行结果
try {
//这里会一直阻塞,直到结果返回
senderFuture.get();
} catch (ExecutionException e) {
Throwable cause = e.getCause();
//如果有异常则直接抛出
// cause should only be a RuntimeException as the Runnable above
// catches IOException
if (cause instanceof RuntimeException) {
throw (RuntimeException) cause;
} else {
throw new RuntimeException("unexpected checked exception", cause);
}
}
}
}客户端通过RPC将请求发送到namenode端,然后namenode端进行相应的操作,并将结果返回到客户端,open函数中最终会调用匿名函数的doCall函数,代码如下:
public FSDataInputStream doCall(final Path p)
throws IOException, UnresolvedLinkException {
final DFSInputStream dfsis =
dfs.open(getPathName(p), bufferSize, verifyChecksum);
return dfs.createWrappedInputStream(dfsis);
}该函数调用dfs.open,该函数会创建DFSInputStream类对象,构造函数如下:
DFSInputStream(DFSClient dfsClient, String src, int buffersize, boolean verifyChecksum
) throws IOException, UnresolvedLinkException {
this.dfsClient = dfsClient;
this.verifyChecksum = verifyChecksum;
this.buffersize = buffersize;
this.src = src;
this.cachingStrategy =
dfsClient.getDefaultReadCachingStrategy();
openInfo();
}该构造函数中最终会调用openInfo函数,代码如下:
/**
* Grab the open-file info from namenode
*/
synchronized void openInfo() throws IOException, UnresolvedLinkException {
lastBlockBeingWrittenLength = fetchLocatedBlocksAndGetLastBlockLength();
int retriesForLastBlockLength = dfsClient.getConf().retryTimesForGetLastBlockLength;
while (retriesForLastBlockLength > 0) {
// Getting last block length as -1 is a special case. When cluster
// restarts, DNs may not report immediately. At this time partial block
// locations will not be available with NN for getting the length. Lets
// retry for 3 times to get the length.
if (lastBlockBeingWrittenLength == -1) {
DFSClient.LOG.warn("Last block locations not available. "
+ "Datanodes might not have reported blocks completely."
+ " Will retry for " + retriesForLastBlockLength + " times");
waitFor(dfsClient.getConf().retryIntervalForGetLastBlockLength);
lastBlockBeingWrittenLength = fetchLocatedBlocksAndGetLastBlockLength();
} else {
break;
}
retriesForLastBlockLength--;
}
if (retriesForLastBlockLength == 0) {
throw new IOException("Could not obtain the last block locations.");
}
}该函数会到远端namenode上获取要打开的文件的信息,我们进入函数fetchLocatedBlocksAndGetLastBlockLength()中代码如下:
private long fetchLocatedBlocksAndGetLastBlockLength() throws IOException {
final LocatedBlocks newInfo = dfsClient.getLocatedBlocks(src, 0);
if (DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("newInfo = " + newInfo);
}
if (newInfo == null) {
throw new IOException("Cannot open filename " + src);
}
if (locatedBlocks != null) {
Iterator<LocatedBlock> oldIter = locatedBlocks.getLocatedBlocks().iterator();
Iterator<LocatedBlock> newIter = newInfo.getLocatedBlocks().iterator();
while (oldIter.hasNext() && newIter.hasNext()) {
if (! oldIter.next().getBlock().equals(newIter.next().getBlock())) {
throw new IOException("Blocklist for " + src + " has changed!");
}
}
}
locatedBlocks = newInfo;
long lastBlockBeingWrittenLength = 0;
if (!locatedBlocks.isLastBlockComplete()) {
final LocatedBlock last = locatedBlocks.getLastLocatedBlock();
if (last != null) {
if (last.getLocations().length == 0) {
if (last.getBlockSize() == 0) {
// if the length is zero, then no data has been written to
// datanode. So no need to wait for the locations.
return 0;
}
return -1;
}
final long len = readBlockLength(last);
last.getBlock().setNumBytes(len);
lastBlockBeingWrittenLength = len;
}
}
fileEncryptionInfo = locatedBlocks.getFileEncryptionInfo();
currentNode = null;
return lastBlockBeingWrittenLength;
}dfsClient.getLocatedBlocks(src, 0);获取要打开文件的块信息,为后面的读写操作做准备,总结一下,open用来获取指定文件在namenode中的块信息,通过块信息就可以使得客户端向datanode发送读写请求,关于读写操作,我们后面会讲到。