一、聚类
1.k-means
首先随意给出聚类中心,然后进行分配和优化。
初始位置非常重要,不同的初始位置可能会使最后的聚类结果完全不一样。并且可能会使结果陷入局部最优:
2.sklearn中的k-means
最重要的三个参数:
n_cluster:聚类数量,默认为8;
max_iter:最大迭代次数,默认为300;
n_init: 不同初始化的数量,默认为10。
3.选择 K
可以通过多种方式选择聚类 k。我们将研究一种简单的方式,叫做“肘部方法”。肘部方法会绘制 k 的上升值与使用该 k 值计算的总误差分布情况。
如何计算总误差? 一种方法是计算平方误差。假设我们要计算 k=2 时的误差。有两个聚类,每个聚类有一个“图心”点。对于数据集中的每个点,我们将其坐标减去所属聚类的图心。然后将差值结果取平方(以便消除负值),并对结果求和。这样就可以获得每个点的误差值。如果将这些误差值求和,就会获得 k=2 时所有点的总误差。
我们对每个 k(介于 1 到数据集中的元素数量之间)执行误差计算,绘制图表,即可确定合适的K值。
4.k 均值通常不喜欢缺失值。
为了使 sklearn 对缺少值的数据集运行 k 均值聚类,我们首先需要将其转型为稀疏 csr 矩阵类型(如 SciPi 库中所定义)。
要从 pandas dataframe 转换为稀疏矩阵,我们需要先转换为 SparseDataFrame,然后使用 pandas 的 to_coo() 方法进行转换。
注意:只有较新版本的 pandas 具有to_coo()。
5.电影评分的 k 均值聚类
我们使用 k 均值根据用户的评分对用户进行聚类。这样就形成了具有相似评分的用户聚类,因此通常具有相似的电影品位。基于这一点,当某个用户对某部电影没有评分时,我们对该聚类中所有其他用户的评分取平均值,该平均值就是我们猜测该用户对该电影的喜欢程度。
关于协同过滤的更多信息
这是一个简单的推荐引擎,展示了“协同过滤”的最基本概念。有很多可以改进该引擎的启发法和方法。为了推动在这一领域的发展,Netflix 设立了 Netflix 奖项 ,他们会向对 Netflix 的推荐算法做出最大改进的算法奖励 1,000,000 美元。
在 2009 年,“BellKor's Pragmatic Chaos”团队获得了这一奖项。这篇论文介绍了他们采用的方式,其中包含大量方法。
Netflix 最终并没有使用这个荣获 1,000,000 美元奖励的算法,因为他们采用了流式传输的方式,并产生了比电影评分要庞大得多的数据集——用户搜索了哪些内容?用户在此会话中试看了哪些其他电影?他们是否先看了一部电影,然后切换到了其他电影?这些新的数据点可以提供比评分本身更多的线索。
深入研究
我们实际上可以使用几乎一样的代码进行商品级推荐。例如亚马逊的“购买(评价或喜欢)此商品的客户也购买了(评价了或喜欢)以下商品:” 。我们可以在应用的每个电影页面显示这种推荐。为此,我们只需将数据集转置为“电影 X 用户”形状,然后根据评分之间的联系对电影(而不是用户)进行聚类。
二、层次聚类法与密度聚类
1.k-meand几乎能帮你从任何数据中提取模式。但它并不是完美无缺的。

这就是把类定义为到质心距离的弊端。这使得k-means总是试图寻找高维领域呈圆形、球形或超球面形的类。
2.层次聚类
层次聚类的结果能让我们直观地了解类之间的关系:

密度聚类。
主要关注其中的DBSCAN(具有噪声的基于密度的聚类方法)。它一般把一些密集分布的点聚类,再讲其他剩余的点标记为噪音。这个算法对双月牙型数据集非常适用。

3.层次聚类:单连接聚类法
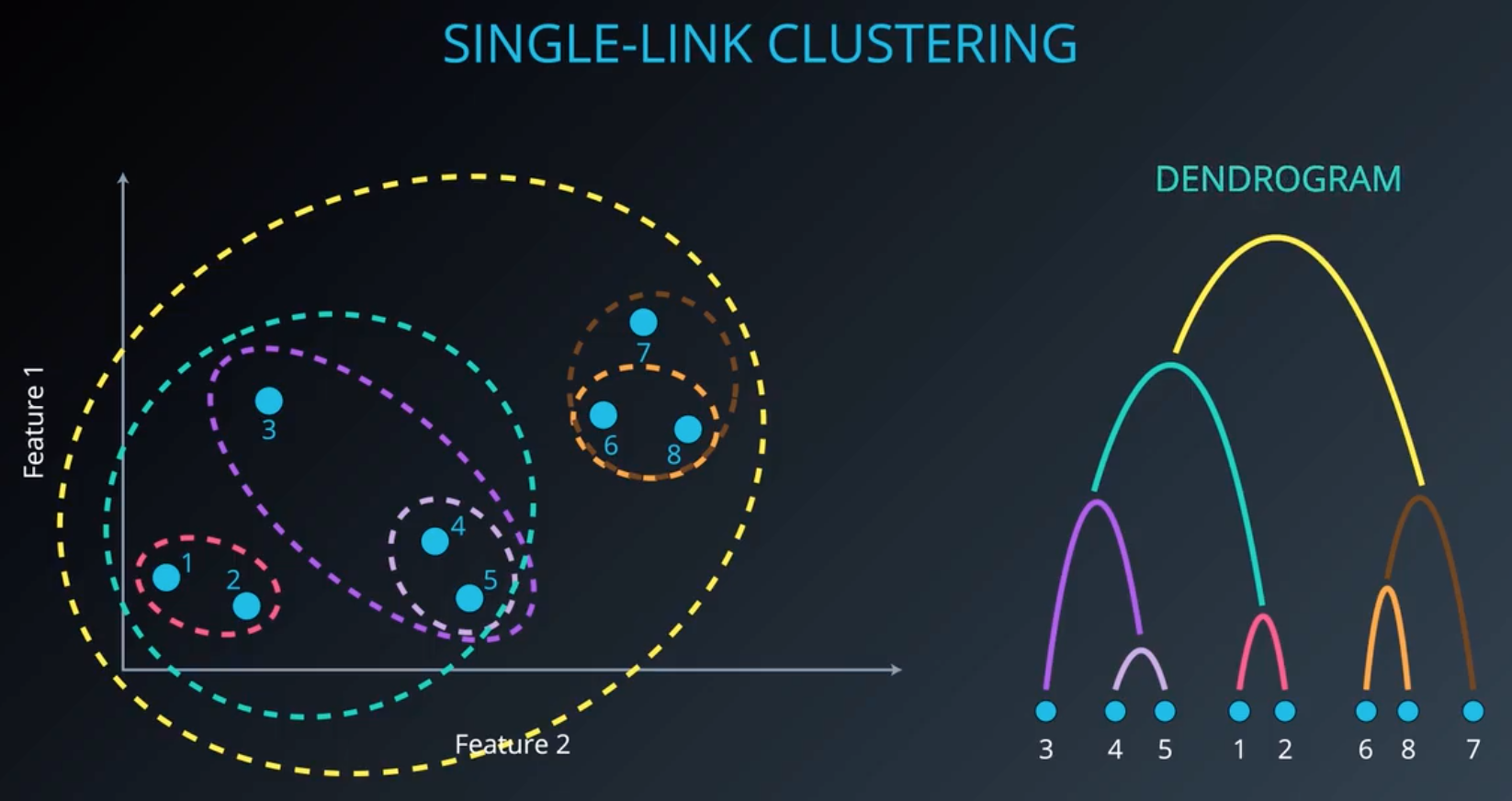
7号点到橘色分类的距离如何计算是区分不同层次聚类方法的一个标准,是7号点到6号点的距离,还是7号点到8号点的距离,还是这两个距离的平均值,还是另有答案。单连接聚类法关注的是类的最短距离,也就是6和7这两点的距离,因为6是距7最近的点。
那么类在哪里?
我们要给单连接聚类法的输入是我们要找的类的数量。只需要砍树就行:
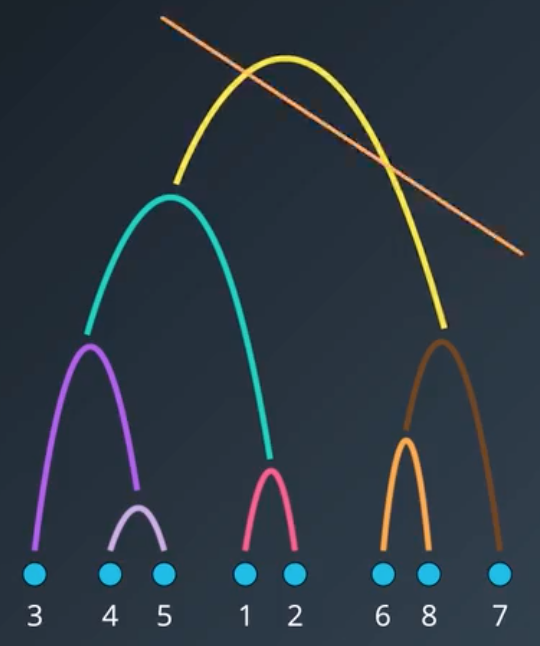
弊端:单连接聚类法有时候会产生狭长的类,但大多数时候,我们想要的,都是紧凑的类;有时候还会导致所形成的类,一个类囊括大多数数据的情况,因此,我们才需要学习其他的层次聚类方法。
分类效果及系统树:

分类效果图只能展示二维数据,系统树能展示任意维数据,所以它能帮我们对数据集做视觉化处理。
4.三种不同的层次聚类法
sklearn中是没有单连接聚类法的。但以下三种都有,它们都属于sklearn框架中凝聚聚类(agglomerative clustering)成分中的一部分,凝聚聚类法并不包括单连接聚类,但包括全连接聚类。
全连接聚类:关注的是两个类中,两点之间的最远距离,将它定义为两类之间的距离。这是全连接聚类和单连接聚类唯一的区别。这种距离衡量方法使得产生的类比较紧凑。但最佳距离衡量方法取决于数据集和目标效果。
组平均聚类:计算任意两类中任意两点之间的距离,然后取平均值,即为两类间的距离。
离差平方和:

5.sklearn中使用层次聚类:
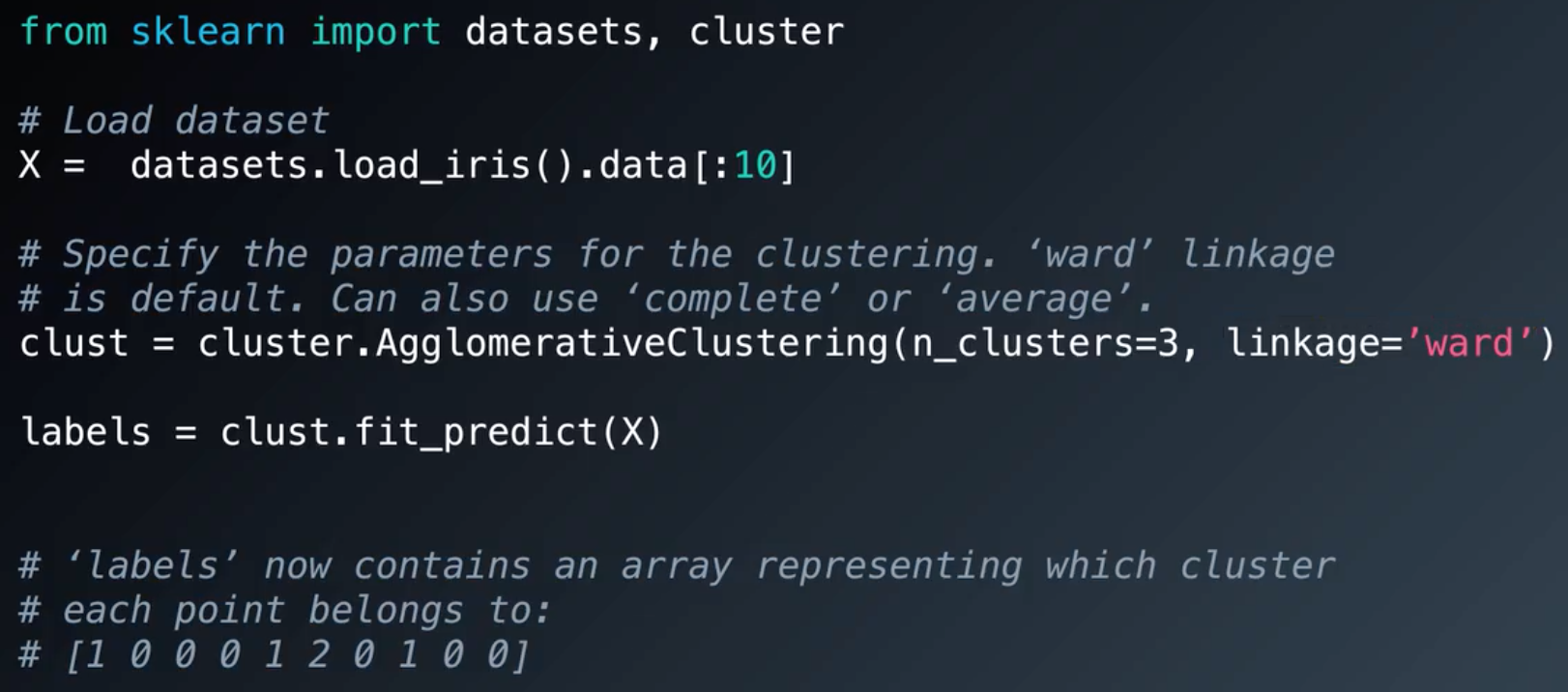
离差平方和(ward)是预设方法
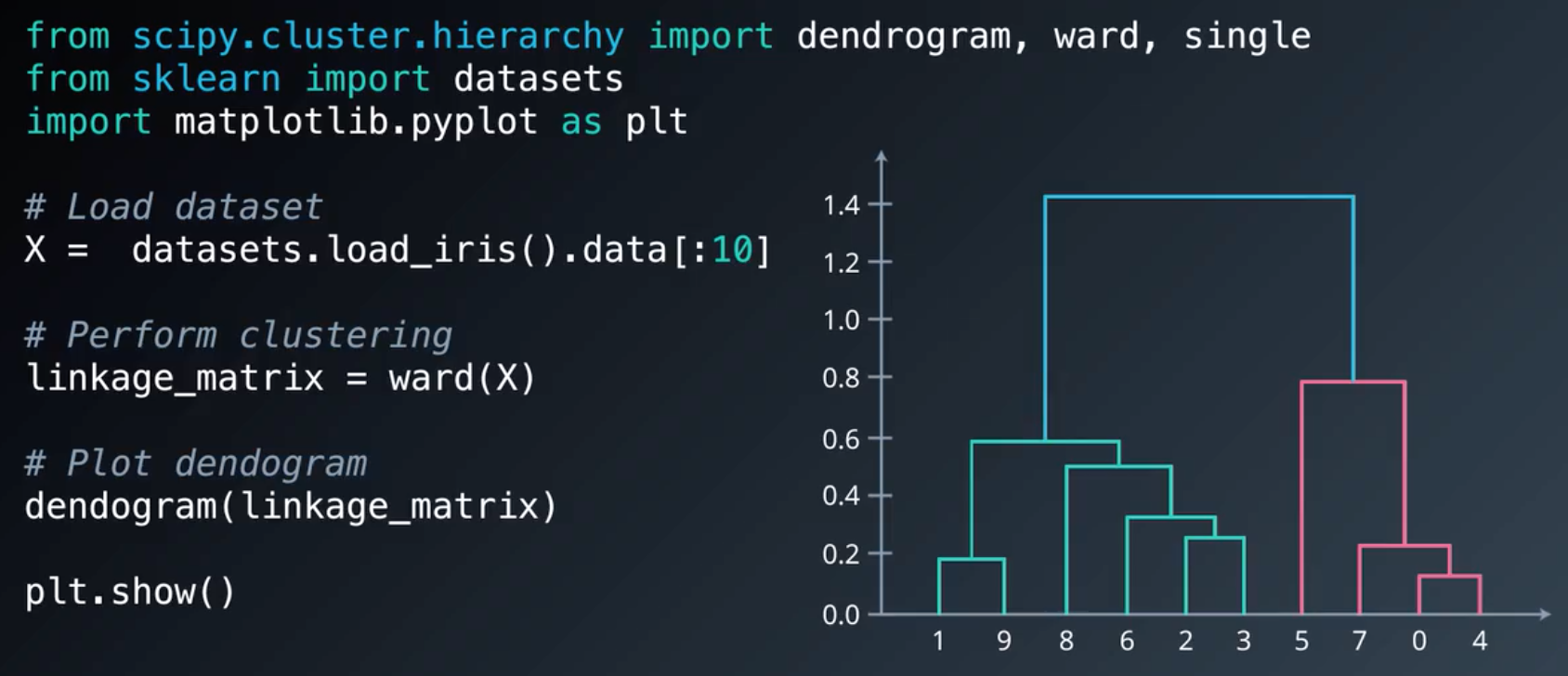
画系统树需要使用SciPy:
6.标准化对聚类的影响
如果某列的值比其他列要小,那么它的方差对聚类处理流程的影响更新(因为聚类是基于距离的)。我们需要对数据集进行标准化 ,使每个维度都位于 0 到 1 之间,以便在聚类流程中具有相等的权重。方法是让每列减去最小值,然后除以范围。sklearn 提供了一个叫做 preprocessing.normalize() 的实用工具,可以帮助我们完成这一步。
7.层次聚类优缺点及其应用
优点:
得到的层次表达信息丰富;
把数据集的聚类结构视觉化;
特别是当数据内部有层次关系的时候,例如进化生物学。
缺点:
对噪音和离群值很敏感(所以要提前清理数据集中的噪音和离群值);
计算量大。
应用:
采用组平均聚类把分泌蛋白聚类,并创建不同的类表示不同种类的真菌:Using Hierarchical Clustering of Secreted Protein Families to Classify and Rank Candidate Effectors of Rust Fungi.
采用全连接聚类法绘制人体微生物的图表:Association between composition of the human gastrointestinal microbiome and development of fatty liver with choline deficiency
8.DBSCAN

DBSCAN的参数只有邻域和点的最小数量。

9.sklearn中的DBSCAN

10.DBSCAN优缺点及其应用
优点:
不需要指明类的数量;
能灵活地找到并分离各种形状和大小的类;
能强有力地处理数据集中的噪声和离群值。
缺点:
从两个类可达的边界点被分配给了其中一个类,因为这个类先发现的这个边界点。由于各个点是被随机拜访的,如果出现这种情况的话DBSCAN不能保证传回相同的聚类。幸运的是,大多数数据集不会面临这个问题;
找到不同密度的类方面有一定的困难。对于这种情况,我们可以使用DBSCAN的变体HDBSCAN,即具有噪声的基于密度的高层次空间聚类算法。
应用:
研究网络流量,试图用聚类算法将其分类:Traffic Classification Using Clustering Algorithms.
对温度数据做异常检测Anomaly detection in temperature data using dbscan algorithm.
三、高斯混合模型(GMM)与聚类验证
1.高斯混合模型是一种温和的聚类,数据集中的每个样本,都属于现有的每个类,但是它们在每个类中的隶属度不一样:
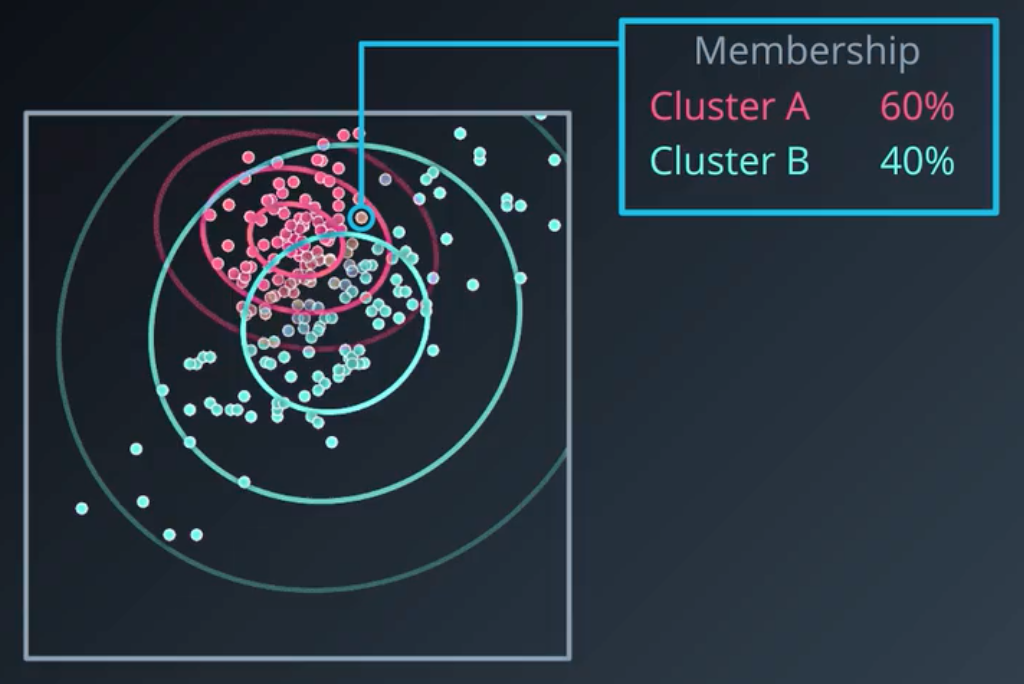
2.期望最大化算法
为了进行聚类,我们需要对高斯混合模型采用期望最大化算法。
第一步,初始化k个高斯分布。基本上,我们需要给它们均值和标准差。朴素的方法是将它们设置为数据集本身的平均值。但在实践中有一种更好的方法,是在数据集上使用k均值,然后使用有k均值生成的聚类初始化高斯分布。
第二步,将数据软聚类成初始化的k个高斯,称为期望步骤,或E步骤。

图中的N(...)基本上是正态分布的概率密度函数。
第三步,基于软聚类重新估计高斯,称为最大化步骤,或M步骤。
计算新的均值:

计算新的方差:
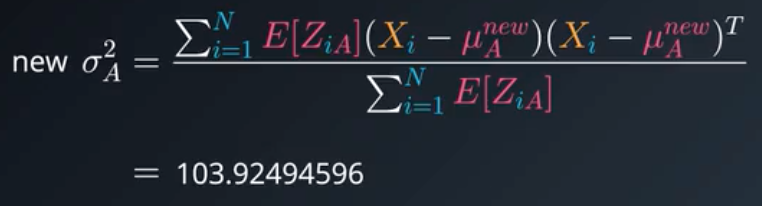
第四步,评估对数似然来检查收敛。如果不收敛,回到第二步,反复进行。
对数似然计算公式:
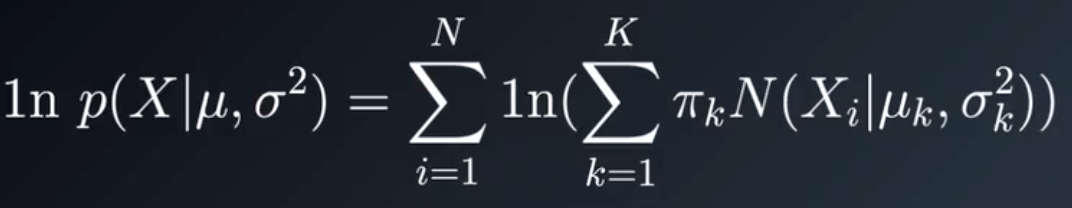
3.sklearn中的GMM实现

4.GMM优缺点及其应用
优点:
提供软聚类(软聚类是多个聚类的示例性隶属度)。例如文档分类,你希望每个文档都是多个主题,GMM就很有帮助;
在聚类外观方面很具灵活性。它可以允许一个聚类中包含另一个聚类。
缺点:
对初始值敏感;
有可能收敛到局部最优;
收敛速度慢。
应用:
读懂大量的传感器读数。所使用的一个数据集就是加速度计读数,GMM在创建不同活动的外观方面非常有用,通过GMM读取装在人们口袋中的加速度计读数,可以估计此人是在通勤,还是在办公室:Nonparametric discovery of human routines from sensor data.
分类天文学中的脉冲星:Application of the Gaussian mixture model in pulsar astronomy.
生物识别。例如说话人确认,签名识别,指纹和其他类型的生物识别:Speaker Verification Using Adapted Gaussian Mixture Models.
目前为止,GMM最酷的应用还是计算机视觉。把图片提供给这个模型,同时也把这个图片所在的流式视频提供给模型,它就可以检测背景,并从最初的图像中移除它。实际上是给每个像素一个高斯混合模型,然后用流式视频学习一个模型,一个实际发生在多个帧的像素中的高斯混合,使用它可以检测背景:Adaptive background mixture models for real-time tracking.视频。

5.聚类分析过程
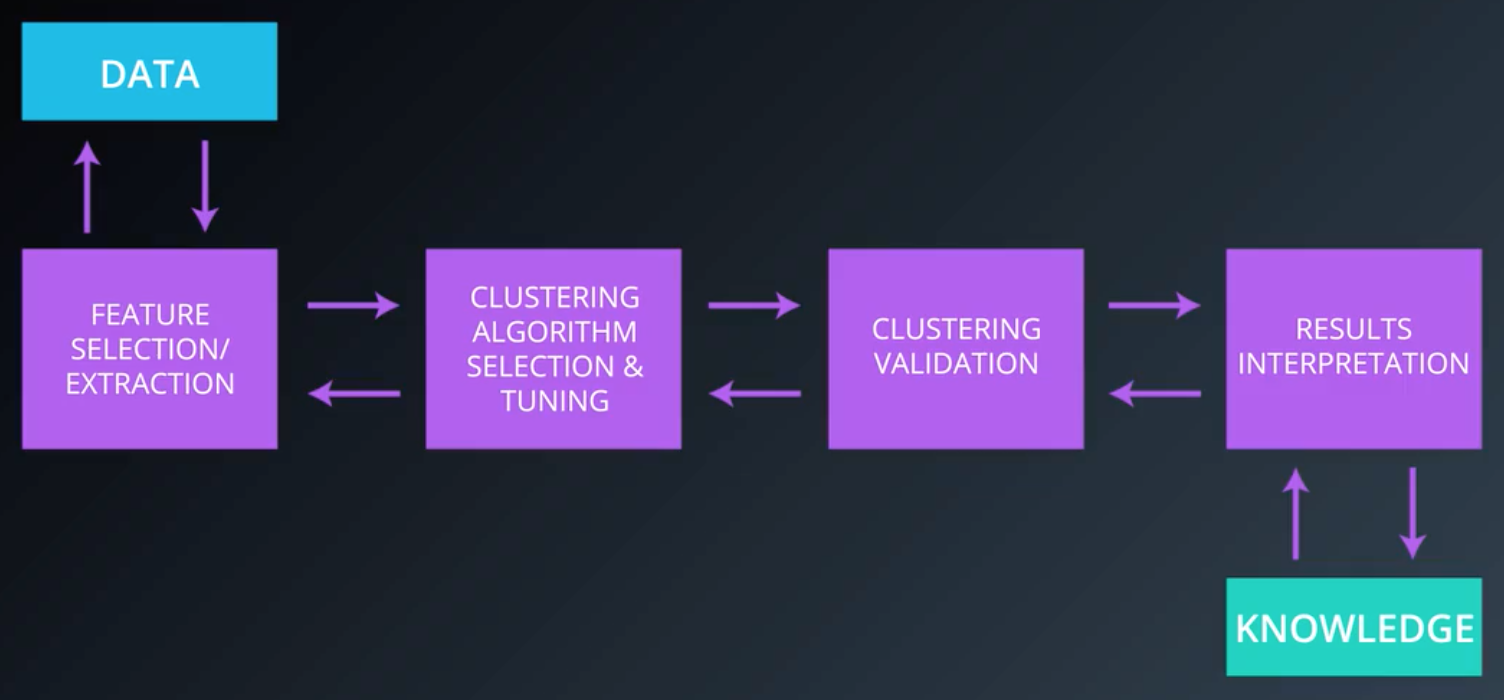
第一步,特征选择和特征提取。特征选择是从一组特征中选择特征,我们不必对所有的数据集,即数据集的每一列都使用聚类方法。有时我们的数据集有数以千计的维度,进行聚类需要很多资源,我们可以使用一些方法和工具来减少特征,并选取结果最好的特征;特征提取是对数据进行转换,以生成新的有用特征,最好的例子是主成分分析(PCA);
第二步,选择一个聚类算法。根据你需要做什么和数据的外观,你必须试验哪一个算法可以给你最好的结果,没有任何算法可以普遍地适用于我们可能面临的问题。在这一步,我们必须选择一个邻近度度量,一般情况下会使用欧氏距离来衡量两点间的几何距离,但如果你的数据是文档或词嵌入,邻近度度量将是余弦距离。如果你的数据更多的是基因表达类型数据,那么你将使用Pearson相关系数;
第三步,聚类评价。除了在可能的情况下对聚类结果进行可视化以外,我们还可以使用一些评分方法来评估基于特定标准的聚类结构的质量,这些评分方法被称为指数。每一个指数称为聚类有效性指标;
第四步,聚类结果解释。结果解释决定了我们可以从最终的聚类结构中学习到什么样的见解。这一步需要领域专业知识为集群提供标签,并试图从中推断出一些见解。
6.聚类验证
聚类评价指数有三种:
外部指标:处理有标签数据时使用的评分;
内部指标:处理没有标签数据时使用的评分,仅使用数据来衡量数据和结构之间的吻合度;
相对指标:基本上,所有外部指标都能作为相对指标。
大多数指标是通过紧凑性和可分性来定义的。紧凑性基本上是衡量一个聚类中的元素彼此之间的距离,而可分性表示不同聚类之间的距离。
7.外部评价指标
可用的评分方法的一个子集:
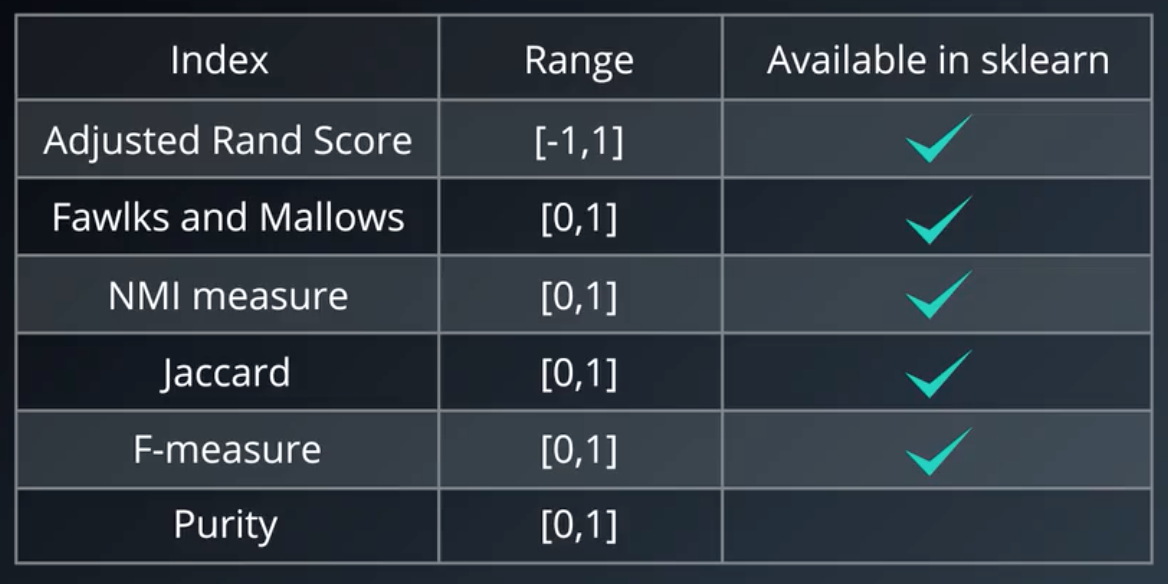
调整兰德系数:

8.内部评价指标
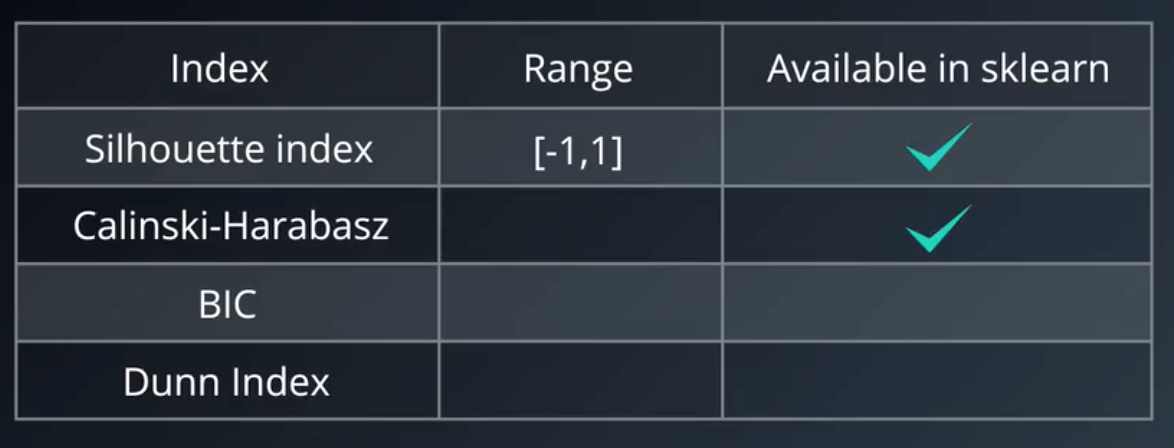
轮廓系数:

我们也可以利用轮廓系数来比较聚类算法。
注意:当我们使用DBSCAN时,不应该使用轮廓系数,因为轮廓系数没有噪音的概念;同时,轮廓系数不会奖励双环形分割,它想找到从其他类分割开的那些紧凑,密集的环形类。基于密度的聚类验证(DBCV)在处理DBSCAN时的效果更好。