Udacity AI学习笔记
机器学习
logistics regression(LR)
回归问题:返回连续的值
分类问题:返回状态
基于最大似然估计的方法,最小化模型分布和经验分部之间的交叉熵。损失函数为
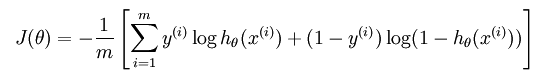
远离分界线的点,权值越低。
support vector machine(SVM)
SVM基于最大化分类间隔的原理,只考虑分界线附近的支持向量,在支持向量外添加任何样本点,其权值为0,对分类结果无任何影响。损失函数为
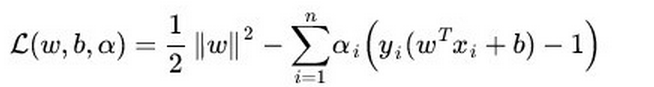
神经网络(neural network)
将数据基于标签划分区域
核方法
将低维空间的非线性可分问题转化成高维空间的线性可分问题
k均值聚类(k-means clustering)
适用于已知数据集有k个集群的情况。
- 随机选择k个点作为聚类中心;
- 对数据集中的每个点,计算其到每个聚类中心的距离,并将其划分到对应聚类中心所属的集合;
- 对新得到的集合进行重新计算聚类中心(均值);
- 若得到的聚类中心与之前的差值小于一定阈值或已收敛,则算法结束,否则重复2-3步骤。
分层聚类
已知数据集有N个点(即初始有N个集合),设定集合之间的相似度阈值为r。
- 计算每个点和其他点之间的距离,将距离最近的点划分为一个集合;
- 计算得到的新集合和其他集合之间的最近距离,将距离最近的两个集合划分为一个集合;
- 若两个集合之间的距离大于设定的阈值r,则算法结束,否则重复步骤2。
实战项目
- Titanic生存率分析
pandas:Python data analysis library,数据结构有series,与numpy中的array相似,只允许存储相同的数据类型;time-series,以时间为索引的series;dataframe,二维的表格型数据结构,可以看成是series组成的字典,
将df按性别分组求身高的平均值
df.groupby(‘性别’)[‘身高’].mean()
dates=pd.date_range('20180310',periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=['A','B','C','D'])#生成6行4列位置
print(df)#输出6行4列的表格
'''
A B C D
2018-03-10 -0.092889 -0.503172 0.692763 -1.261313
2018-03-11 -0.895628 -2.300249 -1.098069 0.468986
2018-03-12 0.084732 -1.275078 1.638007 -0.291145
2018-03-13 -0.561528 0.431088 0.430414 1.065939
2018-03-14 1.485434 -0.341404 0.267613 -1.493366
2018-03-15 -1.671474 0.110933 1.688264 -0.910599
'''
print(df['B'])
'''
2018-03-10 -0.927291
2018-03-11 -0.406842
2018-03-12 -0.088316
2018-03-13 -1.631055
2018-03-14 -0.929926
2018-03-15 -0.010904
Freq: D, Name: B, dtype: float64
'''
#创建特定数据的DataFrame
df_1=pd.DataFrame({'A' : 1.,
'B' : pd.Timestamp('20180310'),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["test","train","test","train"]),
'F' : 'foo'
})
print(df_1)
'''
A B C D E F
0 1.0 2018-03-10 1.0 3 test foo
1 1.0 2018-03-10 1.0 3 train foo
2 1.0 2018-03-10 1.0 3 test foo
3 1.0 2018-03-10 1.0 3 train foo
'''
print(df_1.dtypes)
'''
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
'''
print(df_1.index)#行的序号
#Int64Index([0, 1, 2, 3], dtype='int64')
print(df_1.columns)#列的序号名字
#Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')
print(df_1.values)#把每个值进行打印出来
'''
[[1.0 Timestamp('2018-03-10 00:00:00') 1.0 3 'test' 'foo']
[1.0 Timestamp('2018-03-10 00:00:00') 1.0 3 'train' 'foo']
[1.0 Timestamp('2018-03-10 00:00:00') 1.0 3 'test' 'foo']
[1.0 Timestamp('2018-03-10 00:00:00') 1.0 3 'train' 'foo']]
'''
print(df_1.describe())#数字总结
'''
A C D
count 4.0 4.0 4.0
mean 1.0 1.0 3.0
std 0.0 0.0 0.0
min 1.0 1.0 3.0
25% 1.0 1.0 3.0
50% 1.0 1.0 3.0
75% 1.0 1.0 3.0
max 1.0 1.0 3.0
'''
print(df_1.T)#翻转数据
'''
0 1 2 \
A 1 1 1
B 2018-03-10 00:00:00 2018-03-10 00:00:00 2018-03-10 00:00:00
C 1 1 1
D 3 3 3
E test train test
F foo foo foo
3
A 1
B 2018-03-10 00:00:00
C 1
D 3
E train
F foo
'''
print(df_1.sort_index(axis=1, ascending=False))#axis等于1按列进行排序 如ABCDEFG 然后ascending倒叙进行显示
'''
F E D C B A
0 foo test 3 1.0 2018-03-10 1.0
1 foo train 3 1.0 2018-03-10 1.0
2 foo test 3 1.0 2018-03-10 1.0
3 foo train 3 1.0 2018-03-10 1.0
'''
print(df_1.sort_values(by='E'))#按值进行排序
'''
A B C D E F
0 1.0 2018-03-10 1.0 3 test foo
2 1.0 2018-03-10 1.0 3 test foo
1 1.0 2018-03-10 1.0 3 train foo
3 1.0 2018-03-10 1.0 3 train foo
'''
display(data.head()) #默认展示数据的前五行
data.drop(‘Survived’,axis=1) #axis=1删除Survived这一列,axis=0,删除index即行
data.loc() #按照索引进行行列选择,包含索引的开头结尾,如[1:5],包含第五行
str.format() #格式化字符串
通过位置
In [1]: '{0},{1}'.format('kzc',18)
Out[1]: 'kzc,18'
In [2]: '{},{}'.format('kzc',18)
Out[2]: 'kzc,18'
In [3]: '{1},{0},{1}'.format('kzc',18)
Out[3]: '18,kzc,18'
通过参数
In [5]: '{name},{age}'.format(age=18,name='kzc')
Out[5]: 'kzc,18'
通过对象属性
class Person:
def __init__(self,name,age):
self.name,self.age = name,age
def __str__(self):
return 'This guy is {self.name},is {self.age} old'.format(self=self)
填充与对齐
填充常跟对齐一起使用
^、<、>分别是居中、左对齐、右对齐,后面带宽度
:号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充
In [15]: '{:>8}'.format('189')
Out[15]: ' 189'
In [16]: '{:0>8}'.format('189')
Out[16]: '00000189'
In [17]: '{:a>8}'.format('189')
Out[17]: 'aaaaa189'
指定精度和类型,其中.2表示长度为2的精度,f表示float类型
In [44]: '{:.2f}'.format(321.33345)
Out[44]: '321.33'
统计学知识
四分位距法:
四分位数是将数列等分成四个部分的数,一个数列有三个四分位数,设下四分位数、中位数和上四分位数分别为Q1、Q2、Q3,则:Q1、Q2、Q3的位置可由下述公式确定:
Q1的位置 1(n+1)/4
Q2的位置 2 (n+1) /4
Q3的位置 3(n+1)/4
例如:某车间某月份的工人生产某产品的数量分别为13、13.5、13.8、13.9、14、14.6、14.8、15、15.2、15.4公斤,则三个四分位数的位置分别为:
Q1的位置 (n+1)/4 =(10+1)/4=2.75
Q2的位置(n+1) /2=(10+1)/2=5.5
Q3的位置3(n+1)/4=3(10+1)/4=8.25
即变量数列中的第2.75项、第5.5项、第8.25项工人的某种产品产量分别为下四分位数、中位数和上四分位数。即:
Q1=0.25×第二项+0.75×第三项=0.25×13.5+0.75×13.8=13.73(公斤)
Q2=0.5×第五项+0.5×第六项=0.5×14+0.5×14.6=14.3(公斤)
Q3=0.75×第八项+0.25×第九项=0.75×15+0.25×15.2=15.05(公斤)
异常值(outlier):
常规判定法:异常值是指一组测定值中与平均值的偏差超过两倍标准差的测定值,与平均值的偏差超过三倍标准差的测定值,称为高度异常的异常值。
箱型判定法:上四分位和下四分位(Q1、Q3)的差值为IQR,上界U=Q1+1.5IQR,下界D=Q3-1.5IQR,超过上下界的为异常值。
贝塞尔修正
标准差,方差:分别是样本标准差,总体标准差,样本方差,总体方差

读取数据集(csv文件)
data = pandas.read_csv(‘file_name.csv’) #读取的格式为dataframe
转化为数组
x = np.array(data[[‘x1’,‘x2’]]) #存储为特征x,若希望获得多列,则需要输入列表
y = np.array(data[‘y’]) #存储为标签y
sklearn中训练模型
定义分类器,然后使分类器和数据拟合。classifier.fit(X,y)
以下是常用的分类器,以及必须导入的文件包
逻辑回归
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
神经网络
from sklearn.neural_network import MLPClassifier
classifier = MLPClassifier()
决策树
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier()
SVM
from sklearn.svm import SVC
classifier = SVC()
核函数
K(x, y):表示样本 x 和 y,添加多项式特征得到新的样本 x’、y’,K(x, y) 就是返回新的样本经过计算得到的值;在 SVM 类型的算法 SVC() 中,K(x, y) 返回点乘:x’ . y’ 得到的值;
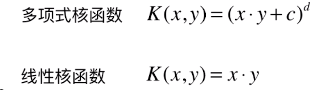
多项式特征的基本原理:依靠升维使得原本线性不可分的数据线性可分;
升维的意义:使得原本线性不可分的数据线性可分
高斯核:唯一超参数γ,手动调参的关键
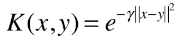
目的是对样本数量少,特征多的数据集进行降维,找到更利于线性分类的空间
高斯核函数,也称为 RBF 核(Radial Basis Function Kernel),也称为径向基函数;
高斯核函数的本质:将每一个样本点映射到一个无穷维的特征空间;
无穷维:将 mn 的数据集,映射为 mm 的数据集,m 表示样本个数,n 表示原始样本特征种类,样本个数是无穷的,因此,得到的新的数据集的样本也是无穷维的;
高斯核升维的本质,使得线性不可分的数据线性可分;
训练模型
训练集测试集的划分
scikit-learn
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X ,y, test_size = 0.25,stratify=y)
stratify:使训练集和测试集中y的比例与原数据集相同如y取0,1=2:8
# Import statements
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
from sklearn.cross_validation import train_test_split
#Import the train test split
# http://scikit-learn.org/0.16/modules/generated/sklearn.cross_validation.train_test_split.html
# Read in the data.
data = np.asarray(pd.read_csv('data.csv', header=None))
# Assign the features to the variable X, and the labels to the variable y.
X = data[:,0:2]
y = data[:,2]
# Use train test split to split your data
# Use a test size of 25% and a random state of 42
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.25,random_state =42)
# Instantiate your decision tree model
model = DecisionTreeClassifier()
# TODO: Fit the model to the training data.
model.fit(X_train,y_train)
# TODO: Make predictions on the test data
y_pred = model.predict(X_test)
# TODO: Calculate the accuracy and assign it to the variable acc on the test data.
acc = accuracy_score(y_test,y_pred)
- 读取csv文件
- 添加到特征和标签变量。转化为数组
- 划分训练集和测试集
- 选择训练模型 #model
- 用训练模型拟合训练集 #model.fit(X_train,y_train)
- 预测测试集的输出 #model.predict(X_test)
- 验证预测输出的准确性 accuracy_score(y_test,y_pred)
评估指标
混淆矩阵
真阳性:true positive
真阴性:true negative
假阳性:false positive
假阴性:false negative
准确率
accuracy = true / all
精度

即预测为正确的样本中实际正确的样本所占比例。
召回率
recall = true positives / true positives + false negatives
即实际正确的样本中你预测为正确的样本所占比例。
F1分数(harmonic mean)
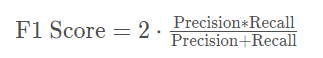
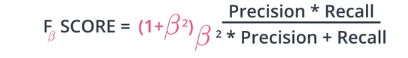

ROC曲线

横坐标为FPR,纵坐标为TPR,与x轴围成的面积AUC为判定标准
评估回归模型的指标
- 平均绝对误差(mean absolute error):各点到拟合曲线的绝对距离(y的差值)的平均值
- 均方误差(mean squared error):各点到拟合曲线的距离平方的平均值
- R2 score:(0,1),越接近1,model越好,即模型与直接预测每个值为平均值的模型的差距越大,说明模型效果越好。
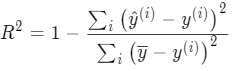
模型选择
错误类型
- underfitting:we get errors due to high bias,过度简化问题,
- overfitting:we get errors due to high variance,过度复杂化问题
交叉验证集
cross validation set: 用来决定模型,例如多项式的次数

k-fold cross validation:将交叉验证集数据划分成k份,训练模型k次,每次轮流取不同的几份数据作为测试集,剩余数据作为训练集,然后对得到的结果取平均,得到最终模型
from sklearn.model_selection import KFold
kf = KFold(data_size,teseting data_size,shuffle = true)
学习曲线
 high bias:欠拟合,训练误差和验证误差收敛在误差较大的地方;
high bias:欠拟合,训练误差和验证误差收敛在误差较大的地方;
high variance:过拟合,训练误差和验证误差相差较大
网格搜索(grid search)
目的:给网络选择最佳参数,例如SVM中 kernal和C,以sklearn为例
- 导入GridSearchCV
from sklearn.model_selection import GridSearchCV
- 选择参数,形成一个列表
parameters = {'kernals':['poly',rbf'], 'c':[0.1, 1, 10]}
- 选择一个评分机制(scorer)为候选模型打分
from sklearn.metrics import make_scorer
from sklearn.metrics import f1_score
scorer = make_scorer(f1_score)
- 使用参数和评分机制创建一个GridSearch对象。使用此对象fit the data。
grid_obj = GridSearchCV(clf, parameters, scoring = scorer)
grid_fit = grid_obj.fit(X,y)
- 获得最佳估算器
best_clf = grid_fit.best_estimator_