文本学习的基本问题与输入特征相关,我们学习的每个文件、每封邮件或每个书名,它的长度都是不标准的,所以不能讲某个单独的词作为输入特征,因此在文本的机器学习中有个功能——词袋Bag of Words,基本理念选定一个文本,然后计算文本的频率
Nice Day与A Very Nice Day

Mr Day Loves a Nice Day
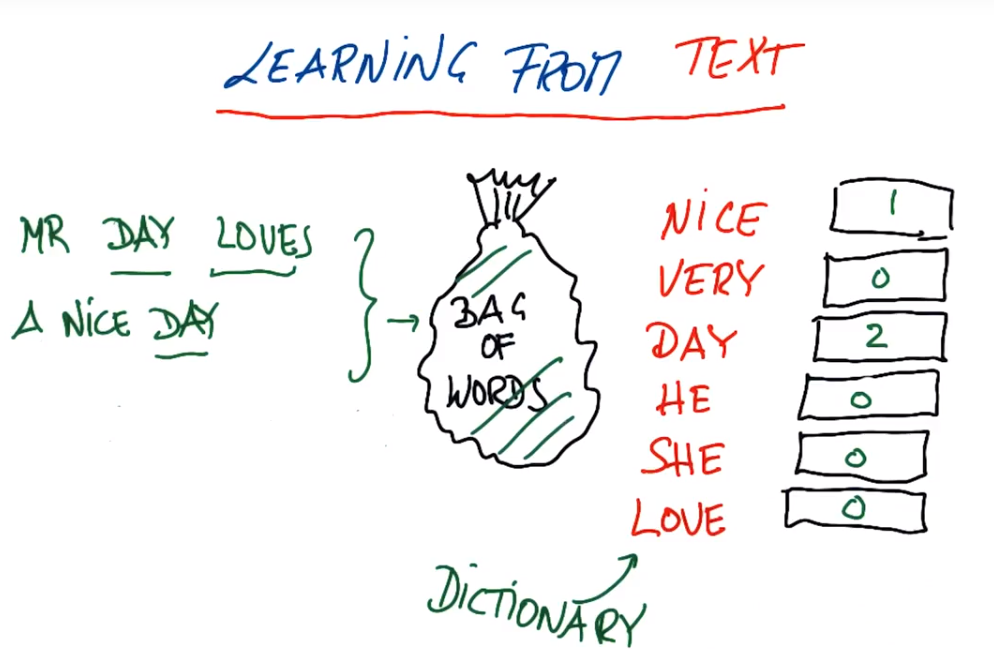
词袋属性:短语的单词顺序不会影响频率(Nice Day 和 Day Nice)、长文本或短语给出的输入向量完全不同(相同的邮件复制十次然后将十份内容放入同一个文本,得到的结果与一份完全不同)、不能处理多个单词组成的复合短语(芝加哥公牛分开和组合在一起意义不同,现在已经改变了字典,有复合短语芝加哥公牛)

在sklearn中词袋被称为CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() string1 = "hi Katie the self dirving car will be late Best Sebastian" string2 = "Hi Sebastian the machine learning class will be great great great Best Katie" string3 = "Hi Katie the machine learning class will be most excellent" email_list = [string1,string2,string3] bag_of_words = vectorizer.fit(email_list) bag_of_words = vectorizer.transform(email_list)


在进行文本分析时,在词汇表中,不是所有单词都是平等的,有些单词包含的信息更多,如上图低信息单词;
有些单词不包含信息,它们会成为数据集中噪音,因此要移除语料库,这个单词清单是停止词,一般是出现非常频繁的低信息单词,在文本分析中一个常见的预处理步骤就是在处理数据前去除停止词

NLTK是自然语言工具包,从NLTK中获取停止词清单,NLTK需要一个语料库(即文档)以获取停止词,第一次使用时需要下载
import nltk
nltk.donload()
from nltk.corpus import stopwords
sw = stopwords.words("english")
len(sw)<<<153
词干提取,可以在分类器或回归中使用的词根或词干
将下面的五维数输入空间转化为一维数,而且不会损失任何真正的信息
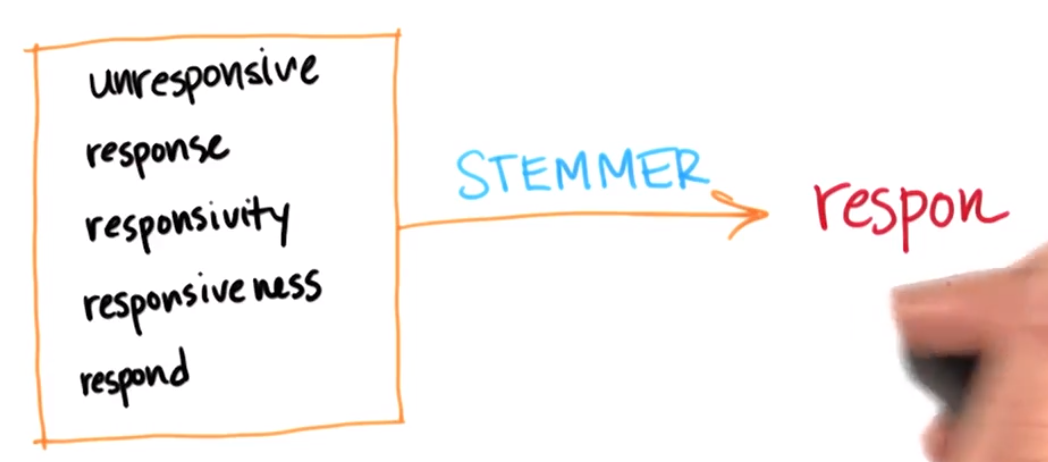
使用NLTK进行词干化
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer('english')
print stemmer.stem('responsiveness')
print stemmer.stem('responsivity')
print stemmer.stem('unresponsive')
<<<respons
<<<respons
<<<unrespons
总体来说,使用词干提取器之后能够很大程度地清理你的语料库的词汇表
文本处理中的运算符顺序:先词干提取(原因:如果先放入词袋,词袋内会得到重复多次的相同的词)

例如:
假设正在讨论“responsibility is responsive to responsible people”这一段文字(这句话不合语法)
如果你直接将这段文字放入词袋,你得到的就是:
[is:1
people: 1
responsibility: 1
responsive: 1
responsible:1]
然后再运用词干化,你会得到
[is:1
people:1
respon:1
respon:1
respon:1]
(如果你可以找到方法在 sklearn 中词干化计数向量器的对象,这种尝试最有可能的结果就是你的代码会崩溃……)
那样,你就需要再进行一次后处理来得到以下词袋,如果你一开始就进行词干化,你就会直接获得这个词袋了:
[is:1
people:1
respon:3]
显然,第二个词袋很可能是你想要的,所以在此处先进行词干化可使你获得正确的答案。
Tf Idf表达——更注重罕见的单词,帮助分辨信息
Tf——term frequency 术语频率——更像词袋,每个术语或单词会根据其在一个文件中出现的次数加重权重(一个词出现十次其权重比出现一次的词重十倍)
Idf——inverse document frequency逆向文件频率——单词会根据其在整个语料库、所有文件中出现的频率得到加权

文本学习迷你项目
练习:parseOutText()热身
- 把代码运行一遍就好了
- answer: Hi Everyone If you can read this message youre properly using parseOutText Please proceed to the next part of the project
练习:部署词干化
- answer:hi everyon if you can read this messag your proper use parseouttext pleas proceed to the next part of the project
- 这里要注意filter的使用,要过滤掉空白字符
text_list = filter(None,text_string.split(' '))
stemmer = SnowballStemmer("english")
text_list = [stemmer.stem(item) for item in text_list]
words = ' '.join(text_list)
练习:清楚签名文字
answer:tjonesnsf stephani and sam need nymex calendar
### use parseOutText to extract the text from the opened email
words = parseOutText(email)
### use str.replace() to remove any instances of the words
### ["sara", "shackleton", "chris", "germani"]
stopwords = ["sara", "shackleton", "chris", "germani", "sshacklensf", "cgermannsf"]
for word in stopwords:
words = words.replace(word, "")
words = ' '.join(words.split())
### append the text to word_data
word_data.append(words)
### append a 0 to from_data if email is from Sara, and 1 if email is from Chris
if name == "sara":
from_data.append(0)
elif name == "chris":
from_data.append(1)
练习:进行TfIdf
使用 sklearn TfIdf 转换将 word_data 转换为 tf-idf 矩阵。删除英文停止词。
使用 get_feature_names() 访问单词和特征数字之间的映射,返回一个包含词汇表所有单词的列表。有多少不同的单词?
练习:访问TfIdf特征
你 TfId 中的单词编号 34597 是什么?
我得到的答案:42282和reqs,且stephaniethank序列为37645
- 正确答案:38757和stephaniethank
for name, from_person in [("sara", from_sara), ("chris", from_chris)]:
for path in from_person:
### only look at first 200 emails when developing
### once everything is working, remove this line to run over full dataset
#temp_counter += 1
#if temp_counter < 200:
path = os.path.join('..', path[:-1])
print path
email = open(path, "r")
### use parseOutText to extract the text from the opened email
words = parseOutText(email)
### use str.replace() to remove any instances of the words
### ["sara", "shackleton", "chris", "germani"]
stopwords = ["sara", "shackleton", "chris", "germani", "sshacklensf", "cgermannsf"]
for word in stopwords:
words = words.replace(word, "")
words = ' '.join(words.split())
### append the text to word_data
word_data.append(words)
### append a 0 to from_data if email is from Sara, and 1 if email is from Chris
if name == "sara":
from_data.append(0)
elif name == "chris":
from_data.append(1)
email.close()
print word_data[152]
print "emails processed"
from_sara.close()
from_chris.close()
pickle.dump( word_data, open("your_word_data.pkl", "w") )
pickle.dump( from_data, open("your_email_authors.pkl", "w") )
### in Part 4, do TfIdf vectorization here
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
vectorizer.fit_transform(word_data)
feature_names = vectorizer.get_feature_names()
print len(feature_names)
print feature_names[34597]