练习:一个新的安然特征练习
poi_flag_emal.py
if from_emails:
ctr=0
while not from_poi and ctr < len(from_emails):
if from_emails[ctr] in poi_email_list:
from_poi = True
ctr += 1
练习:可视化新特征
studentCode.py
### you fill in this code, so that it returns either
### the fraction of all messages to this person that come from POIs
### or
### the fraction of all messages from this person that are sent to POIs
### the same code can be used to compute either quantity
### beware of "NaN" when there is no known email address (and so
### no filled email features), and integer division!
### in case of poi_messages or all_messages having "NaN" value, return 0.
if poi_messages !='NaN' and all_messages != 'NaN':
fraction = float(poi_messages)/all_messages
else:
fraction =0.
return fraction
警惕特征漏洞:
任何人都有可能犯错—要对你得到的结果持怀疑态度!你应该时刻警惕 100% 准确率。不寻常的主张要有不寻常的证据来支持。如果有特征过度追踪你的标签,那么它很可能就是一个漏洞!如果你确定它不是漏洞,那么你很大程度上就不需要机器学习了——你可以只用该特征来分配标签。去除特征:
什么情况下回忽略一种特征:


特征≠信息,特征是特定的试图获取信息的数据点的实际数量或特点
例如:如果你有大量的特征,你可能拥有大量的数据,而这些特征的质量就是信息的内容。我们需要的是尽量多信息的数量尽量少的特征,如果你认为特征没有能给予你信息,你就要删除它。
在 sklearn 中自动选择特征有多种辅助方法。多数方法都属于单变量特征选择的范畴,即独立对待每个特征并询问其在分类或回归中的能力。
sklearn 中有两大单变量特征选择工具:SelectPercentile 和 SelectKBest。 两者之间的区别从名字就可以看出:SelectPercentile 选择最强大的 X% 特征(X 是参数),而 SelectKBest 选择 K 个最强大的特征(K 是参数)。
经典的高偏差情形:使用少量特征引发高偏差

经典的高方差情形:过多的特征、过于调整参数

平衡点:使用很少几个特征来拟合某种算法,但是同时就回归而言,想要得到较大的R方或较低的残余误差平方和
过多特征造成高方差,泛化能力弱
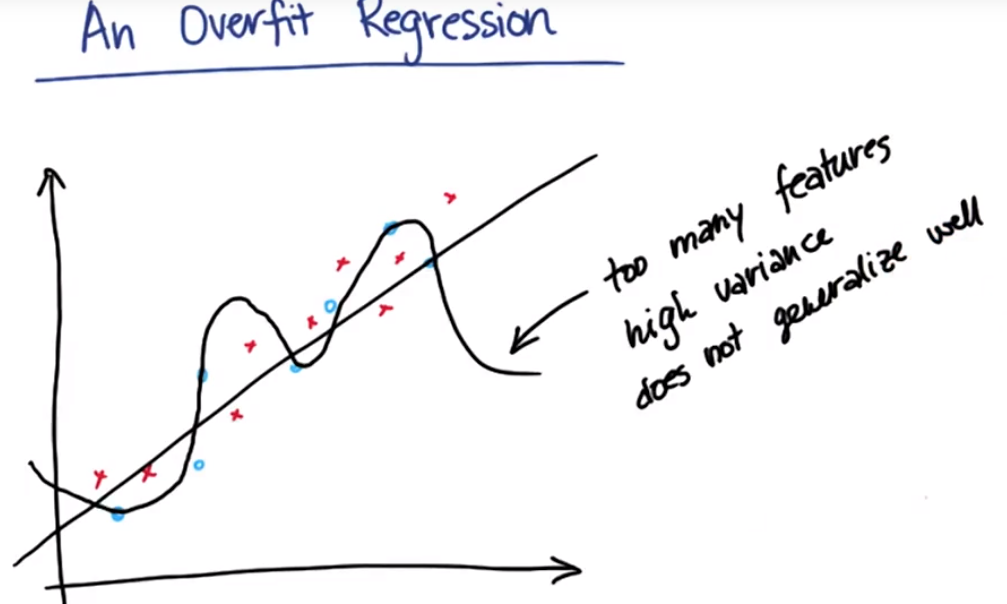
一种正则化回归:Lasso回归
一般的线性回归是要最大程度地降低拟合中的平方误差(即缩短拟合与任何指定数据点之间的距离或距离的平方),Lasso回归也要减小平方误差,但是除了最大化减小平方误差以外,它还要最大化减小使用的特征数量,lambda惩罚参数,β描述的是使用的特征数量,公式原理:使用更多的特征会有更小的平方误差,能更精确的拟合这些点,但是会有额外的惩罚,因此需要使用多特征得到的好处要比形成的损失大。这个公式规定了更少的误差与使用更少特征的更简单的拟合之间的平衡

套索回归练习
.coef_ 打印系数
.predict([[2,4]]) 预测
.fit(特征,标签) 拟合

特征选择迷你项目:
决策树作为传统算法非常容易过拟合,获得过拟合决策树最简单的一种方式就是使用小型训练集和大量特征。
1.如果决策树被过拟合,你期望测试集的准确率是非常高还是相当低? low
2.如果决策树被过拟合,你期望训练集的准确率是高还是低?high
过拟合算法的一种传统方式是使用大量特征和少量训练数据。你可以在 feature_selection/find_signature.py 中找到初始代码。准备好决策树,开始在训练数据上进行训练,打印出准确率。
根据初始代码,有多少训练点?150
### a classic way to overfit is to use a small number ### of data points and a large number of features; ### train on only 150 events to put ourselves in this regime features_train = features_train[:150].toarray() labels_train = labels_train[:150]
4.
你刚才创建的决策树的准确率是多少?0.950511945392
(记住,我们设置决策树用于过拟合——理想情况下,我们希望看到的是相对较低的测试准确率。)
5.
选择(过拟合)决策树并使用 feature_importances_ 属性来获得一个列表, 其中列出了所有用到的特征的相对重要性(由于是文本数据,因此列表会很长)。 我们建议迭代此列表并且仅在超过阈值(比如 0.2——记住,所有单词都同等重要,每个单词的重要性都低于 0.01)的情况下将特征重要性打印出来。
最重要特征的重要性是什么? 0.764705882353 该特征的数字是多少? 36584
(由于文本学习的迷你项目的安然数据集可能不同,没得到正确答案,因此此处的特征的数字的答案也只是我自己的答案)
6.
为了确定是什么单词导致了问题的发生,你需要返回至 TfIdf,使用你从迷你项目的上一部分中获得的特征数量来获取关联词。 你可以在 TfIdf 中调用 get_feature_names() 来返回包含所有单词的列表; 抽出造成大多数决策树歧视的单词。
这个单词是什么?类似于签名这种与 Chris Germany 或 Sara Shackleton 唯一关联的单词是否讲得通?
sshacklensf7.
从某种意义上说,这一单词看起来像是一个异常值,所以让我们在删除它之后重新拟合。 返回至 text_learning/vectorize_text.py,使用我们删除“sara”、“chris”等的方法,从邮件中删除此单词。 重新运行 vectorize_text.py,完成以后立即重新运行 find_signature.py。
有跳出其他任何的异常值吗?是什么单词?像是一个签名类型的单词?(跟之前一样,将异常值定义为重要性大于 0.2 的特征)。cgermannsf
8.
再次更新 vectorize_test.py 后重新运行。然后,再次运行 find_signature.py。
是否出现其他任何的重要特征(重要性大于 0.2)?有多少?它们看起来像“签名文字”,还是更像来自邮件正文的“邮件内容文字”?
是,还有一个新的重要词
9.现在决策树的准确率是多少?0.811149032992
find_signature.py
#!/usr/bin/python
import pickle
import numpy
numpy.random.seed(42)
### The words (features) and authors (labels), already largely processed.
### These files should have been created from the previous (Lesson 10)
### mini-project.
words_file = "../text_learning/your_word_data.pkl"
authors_file = "../text_learning/your_email_authors.pkl"
word_data = pickle.load( open(words_file, "r"))
authors = pickle.load( open(authors_file, "r") )
### test_size is the percentage of events assigned to the test set (the
### remainder go into training)
### feature matrices changed to dense representations for compatibility with
### classifier functions in versions 0.15.2 and earlier
from sklearn import cross_validation
features_train, features_test, labels_train, labels_test = cross_validation.train_test_split(word_data, authors, test_size=0.1, random_state=42)
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5,
stop_words='english')
features_train = vectorizer.fit_transform(features_train)
features_test = vectorizer.transform(features_test).toarray()
words = vectorizer.get_feature_names()
### a classic way to overfit is to use a small number
### of data points and a large number of features;
### train on only 150 events to put ourselves in this regime
features_train = features_train[:150].toarray()
labels_train = labels_train[:150]
### your code goes here
from sklearn import tree
from sklearn.metrics import accuracy_score
clf = tree.DecisionTreeClassifier()
clf.fit(features_train,labels_train)
#accuracy_score method 1
acc = clf.score(features_test,labels_test)
print acc
#accuracy_score method 2
pred = clf.predict(features_test)
print "Accuracy:", accuracy_score(labels_test, pred)
fi=clf.feature_importances_
print "Important features:"
for index, feature in enumerate(clf.feature_importances_):
if feature>0.2:
print "feature no", index
print "importance", feature
print "word", words[index]
vectorize_text.py
stopwords = ["sara", "shackleton", "chris", "germani", "sshacklensf", "cgermannsf"]
for word in stopwords:
words = words.replace(word, ' ')
words = ' '.join(words.split())