一.拓扑排序
这里请结合参考博客学习(在后面)
拓扑排序(无环图的应用)
在一个表示工程的有向图中,有顶点表示活动,用弧表示活动之间的优先关系,这样的有向图为顶点表示活动的网,我们称为AOV(Activity On Vertex)网。
AOV网中的弧表示活动之间存在的某种制约关系。
所谓拓扑排序,其实就是对一个有向图构造拓扑序列的过程。

执行步骤
由AOV网构造拓扑序列的拓扑排序算法主要是循环执行以下两步,直到不存在入度为0的顶点为止。
(1) 选择一个入度为0的顶点并输出之;
(2) 从网中删除此顶点及所有出边。
循环结束后,若输出的顶点数小于网中的顶点数,则输出“有回路”信息,否则输出的顶点序列就是一种拓扑序列。 [2]
非计算机应用
拓扑排序常用来确定一个依赖关系集中,事物发生的顺序。例如,在日常工作中,可能会将项目拆分成A、B、C、D四个子部分来完成,但A依赖于B和D,C依赖于D。为了计算这个项目进行的顺序,可对这个关系集进行拓扑排序,得出一个线性的序列,则排在前面的任务就是需要先完成的任务。
注意:这里得到的排序并不是唯一的!
就好像你早上穿衣服可以先穿上衣也可以先穿裤子,只要里面的衣服在外面的衣服之前穿就行。
算法伪码:

这种算法的时间复杂度并不理想,有没有更好的办法呢?
当然是有的!!!
方法:随时将入度变为0的顶点放到一个容器里
提醒一下:这里的容器可以是很多,数组,链表,堆栈都成
这里我们用的是队列

其中DAG(Directed Acyclic Graph)为有向无环图
一个小补充:
分别用队列和堆栈作为容器,对计算机专业课程进行拓扑排序,得到的序列有什么区别?用哪种容器排课更合理?
答案:
用堆栈的结果类似于DFS,课程是按照学科分支被一个分支一个分支地列出,相当于建议学生先把一个分支由浅入深学完,再进入下一个分支。
用队列的结果类似于BFS,课程是按照深浅顺序,一层一层地列出。这种排列更符合我们实际的教学计划安排,即让学生先在低年级学完基础课程,再逐层深入。所以是用队列更合理。
注意:无论用堆栈还是用队列,都不影响拓扑序的正确性。堆栈或队列的影响只是在面对一堆都不需要前序课的课程时,先输出哪个的问题(结果可能会不同)。
算法实现:
/* 邻接表存储 - 拓扑排序算法 */
bool TopSort( LGraph Graph, Vertex TopOrder[] )
{ /* 对Graph进行拓扑排序, TopOrder[]顺序存储排序后的顶点下标 */
int Indegree[MaxVertexNum], cnt;
Vertex V;
PtrToAdjVNode W;
Queue Q = CreateQueue( Graph->Nv );
/* 初始化Indegree[] */
for (V=0; V<Graph->Nv; V++)
Indegree[V] = 0;
/* 遍历图,得到Indegree[] */
for (V=0; V<Graph->Nv; V++)
for (W=Graph->G[V].FirstEdge; W; W=W->Next)
Indegree[W->AdjV]++; /* 对有向边<V, W->AdjV>累计终点的入度 */
/* 将所有入度为0的顶点入列 */
for (V=0; V<Graph->Nv; V++)
if ( Indegree[V]==0 )
AddQ(Q, V);
/* 下面进入拓扑排序 */
cnt = 0;
while( !IsEmpty(Q) ){
V = DeleteQ(Q); /* 弹出一个入度为0的顶点 */
TopOrder[cnt++] = V; /* 将之存为结果序列的下一个元素 */
/* 对V的每个邻接点W->AdjV */
for ( W=Graph->G[V].FirstEdge; W; W=W->Next )
if ( --Indegree[W->AdjV] == 0 )/* 若删除V使得W->AdjV入度为0 */
AddQ(Q, W->AdjV); /* 则该顶点入列 */
} /* while结束*/
if ( cnt != Graph->Nv )
return false; /* 说明图中有回路, 返回不成功标志 */
else
return true;
}此外还有一个特别好的博客(大话里的知识讲的也很清楚):https://www.cnblogs.com/Braveliu/p/3460232.html
看完我的建议必看这篇,会更好的理解拓扑排序算法
二.关键路径
这里请结合参考博客学习(在后面)
介绍
关键路径通常(但并非总是)是决定项目工期的进度活动序列。它是项目中最长的路径,即使很小浮动也可能直接影响整个项目的最早完成时间。关键路径的工期决定了整个项目的工期,任何关键路径上的终端元素的延迟在浮动时间为零或负数时将直接影响项目的预期完成时间(例如在关键路径上没有浮动时间)。 [2] 但特殊情况下,如果总浮动时间大于零,则有可能不会影响项目整体进度。
一个项目可以有多个、并行的关键路径。另一个总工期比关键路径的总工期略少的一条并行路径被称为次关键路径。最初,关键路径方法只考虑终端元素之间的逻辑依赖关系。关键链方法中增加了资源约束。关键路径方法是由杜邦公司发明的。
步骤
A、从开始顶点 v1 出发,令 ve(1)=0,按拓扑有序序列求其余各顶点的可能最早发生时间。 [3]
Ve(k)=max{ve(j)+dut(<j,k>)} , j ∈ T 。其中T是以顶点vk为尾的所有弧的头顶点的集合(2 ≤ k ≤ n)。
如果得到的拓朴有序序列中顶点的个数小于网中顶点个数n,则说明网中有环,不能求出关键路径,算法结束。
B、从完成顶点
![]()
出发,令
![]()
,按逆拓扑有序求其余各顶点的允许的最晚发生时间:
vl(j)=min{vl(k)-dut(<j,k>)} ,k ∈ S 。其中 S 是以顶点vj是头的所有弧的尾顶点集合(1 ≤ j ≤ n-1)。
C、求每一项活动ai(1 ≤ i ≤ m)的最早开始时间e(i)=ve(j),最晚开始时间l(i)=vl(k)-dut(<j,k>) 。
若某条弧满足 e(i)=l(i) ,则它是关键活动。
相关术语
(1)AOE网
用顶点表示事件,弧表示活动,弧上的权值表示活动持续的时间的有向图叫AOE(Activity On Edge Network)网。在建筑学中也称为关键路线。AOE网常用于估算工程完成时间。例如:
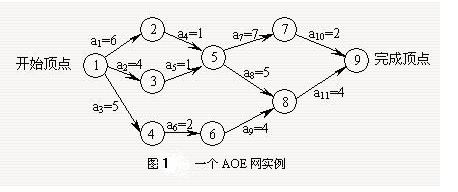 图1.有向网络
图1.有向网络
图1 是一个网。其中有9个事件v1,v2,…,v9;11项活动a1,a2,…,a11。每个事件表示在它之前的活动已经完成,在它之后的活动可以开始。如 v1表示整个工程开始,v9 表示整个工程结束。V5表示活动a2和a3已经完成,活动a7和a8可以开始。与每个活动相联系的权表示完成该活动所需的时间。如活动a1需要6个时间单位可以完成。

一个AOE网的关键路径可以不止一条。
只有在某顶点所代表的事件发生后,从该顶点出发的各有向边所代表的活动才能开始。只有在进入某一顶点的各有向边所代表的活动都已经结束,该顶点所代表的事件才能发生。表示实际工程计划的AOE网应该是无环的,并且存在唯一的入度过为0的开始顶点和唯一的出度为0的完成顶点。
(2) 活动开始的最早时间e(i);
(3) 活动开始的最晚时间l(i) 定义e(i)=l(i)的活动叫关键活动;
(4) 事件开始的最早时间ve(i);
(5) 事件开始的最晚时间vl(i)。
应用
(1) 完成整个工程至少需要多少时间;
(2) 哪些活动是影响工程的关键。

两个问题:
a.整个工期有多长?

b.哪几个组有机动时间

算法
(1) 输入e条弧<j,k>,建立AOE网的存储结构;
(2) 从源点v1出发,令ve(1)=0,求 ve(j) ,2<=j<=n;
(3) 从汇点vn出发,令vl(n)=ve(n),求 vl(i), 1<=i<=n-1;
(4) 根据各顶点的ve和vl值,求每条弧s(活动)的最早开始时间e(s)和最晚开始时间l(s),其中e(s)=l(s)的为关键活动。
求关键路径是在拓扑排序的前提下进行的,不能进行拓扑排序,自然也不能求关键路径。
算法分析
(1) 求关键路径必须在拓扑排序的前提下进行,有环图不能求关键路径;
(2) 只有缩短关键活动的工期才有可能缩短工期;
(3) 若一个关键活动不在所有的关键路径上,减少它并不能减少工期;
(4) 只有在不改变关键路径的前提下,缩短关键活动才能缩短整个工期。
算法实现:
过程略复杂,参考百度百科的代码
后面也有很好的参考博客
#include <iostream>
#include <cstdio>
#include<string.h>
using namespace std;
int n,m,w[1001][1001],prev[1001],queue[1001],Time[1001],l=0,r=0,Pos[1001],path[1001];
void init()
{
int i,a,b,c;
scanf("%d%d",&n,&m);
for (i=1; i<=m; i++)
{
scanf("%d%d%d",&a,&b,&c);
w[a][b]=c;
prev[b]++;
}
}
inline void Newq(int v)
{
r++;
queue[r]=v;
}
inline void Del(int v)
{
int i;
for (i=1; i<=n; i++)
if (w[v][i])
{
prev[i]--;
if (!prev[i])
Newq(i);
}
}
void topo()
{
for (int i=1; i<=n; i++)
if (!prev[i])
Newq(i);
while (r<n)
{
l++;
Del(queue[l]);
}
}
void crucialpath()
{
int i,j;
memset(Time,0,sizeof(Time));
for (i=1; i<=n; i++)
for (j=1; j<=n; j++)
if ((w[j][queue[i]]) && (Time[j]+w[j][queue[i]]>Time[queue[i]]))
{
Time[queue[i]]=Time[j]+w[j][queue[i]];
Pos[queue[i]]=j;
}
}
void print()
{
printf("%d\n",Time[n]);
int i=n,k=0;
while (i!=1)
{
k++;
path[k]=i;
}
for (i=k; i>1; i--)
printf("%d ",path[i]);
printf("%d\n",path[1]);
}
int main()
{
init();
topo();
crucialpath();
print();
return 0;
}此外还有一个特别好的博客(大话里的知识讲的也很清楚):https://www.cnblogs.com/Braveliu/p/3461649.html