这两天学习了Scrapy爬虫框架的基本使用,练习的例子爬取的都是传统的直接加载完网页的内容,就想试试爬取用Ajax技术加载的网页。
这里以简书里的优选连载网页为例分享一下我的爬取过程。
网址为:
https://www.jianshu.com/mobile/books?category_id=284
一、分析网页
进入之后,鼠标下拉发现内容会不断更新,网址信息也没有发生变化,于是就可以判断这个网页使用了异步加载技术。
 f
f
首先明确爬取的内容,本次我爬取的是作品名称、照片、作者、阅读量。然后将照片下载存储在文件夹中,然后将全部内容生成csv文件夹保存。
查看网页源代码发现代码里只有已加载的作品的内容,编写爬虫代码发现爬取不到收录的信息。
进入Network选项,勾选XHR选项,通过下滑网页发现Network选项卡会加载文件,如下图:
注:这里我用的是火狐浏览器

点击其中一个加载文件,可以在消息头看到请求网址:
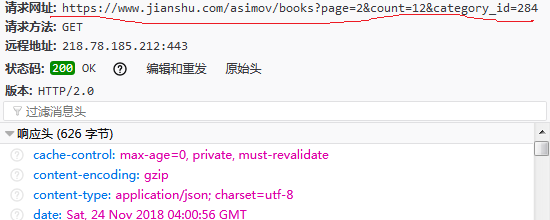
继续下滑,发现Headers部分请求的URL只是page后面的数字在改变,通过改变数字,我们就能在后面调用回调函数爬取多个网页了。
二、Scrapy爬取
1.在命令提示符输入:
cd Desktop #进入桌面
scrapy startproject jian #生成名为jian的Scrapy文件夹
cd jian
scrapy genspider lianzai jianshu.com #爬虫名为lianzai
这里我用的是pycharm,打开文件夹。

2.在items.py定义爬虫字段
1 class JianItem(scrapy.Item): 2 # define the fields for your item here like: 3 # name = scrapy.Field() 4 book_name=scrapy.Field() 5 img=scrapy.Field() 6 author=scrapy.Field() 7 readers=scrapy.Field() 8 pass
3.在lianzai.py编写爬虫代码,爬取数据
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from jian.items import JianItem 4 import json 5 import requests 6 7 class LianzaiSpider(scrapy.Spider): 8 name = 'lianzai' 9 allowed_domains = ['jianshu.com'] 10 start_urls = ['https://www.jianshu.com/asimov/books?page=1&count=12&category_id=284'] #第一页的url 11 def parse(self, response): 12 data=json.loads(response.body) #str转为json对象 13 try: 14 for i in range(0, 12): 15 item = JianItem() 16 img=data['books'][i]['image_url'] 17 book_name=data['books'][i]['name'] 18 author=data['books'][i]['user']['nickname'] 19 readers=data['books'][i]['views_count'] 20 21 item['img']=img 22 item['book_name']=book_name 23 item['author']=author 24 item['readers']=readers 25 yield item #返回数据 26 except IndexError: 27 pass 28 urls=['https://www.jianshu.com/asimov/books?page={}&count=12&category_id=284'.format(str(i))for i in range(2, 11)] # 29 for url in urls: 30 yield scrapy.Request(url,callback=self.parse) #回调函数
这里特别要注意的是要爬取内容的所在位置。
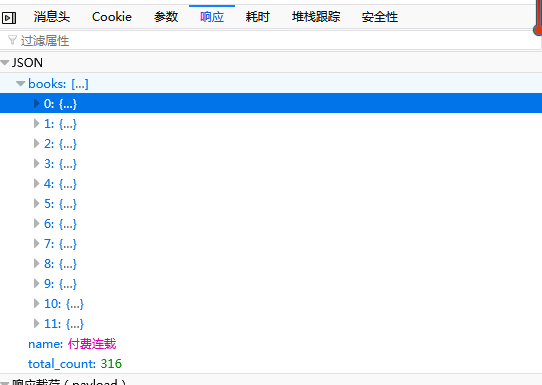
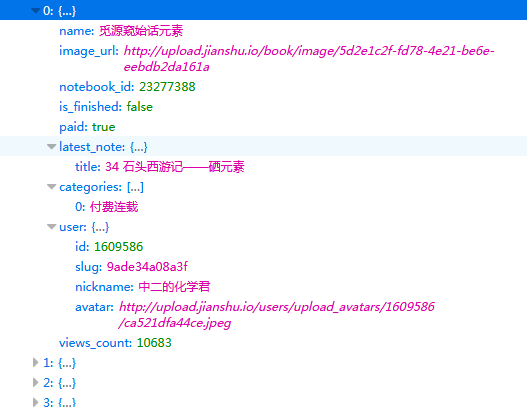
上图中左图可以看出爬取的内容的位置在response里的['books']里面,且一个网页有12个作品,因此上面循环出为(0,12)。
打开后如上右图,可以看到我们要爬取的作品名、图片地址、作者、阅读量都在里面,爬取就相对容易了。
4.在setting.py设置爬虫配置
1 USER_AGENT='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36' #请求头 2 DOWNLOAD_DELAY=0.5 #延时0.5 3 FEED_URI='file:C:/Users/lenovo/Desktop/jianshulianzai.csv' #在桌面生成CSV文件 4 FEED_FORMAT='csv' #存入 5 ITEM_PIPELINES={'jian.pipelines.JianPipeline':300}
5.在pipelines.py处理照片数据
1 # -*- coding: utf-8 -*- 2 3 # Define your item pipelines here 4 # 5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 7 import os 8 import urllib.request 9 10 class JianPipeline(object): 11 def process_item(self, item, spider): 12 headers = { 13 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36' 14 } 15 try: 16 if item['img'] != None: 17 req=urllib.request.Request(url=item['img'],headers=headers) 18 res=urllib.request.urlopen(req) 19 file_name = os.path.join(r'C:\Users\lenovo\Desktop\my_pic', item['book_name'] + '.jpg') 20 with open(file_name,'wb')as f: 21 f.write(res.read()) 22 except urllib.request.URLError: 23 pass 24 return item
6.全部保存后,在命令行终端输入:
scrapy crawl lianzai
就将结果爬取下来并保存啦。
三、结果
.csv文件的内容:
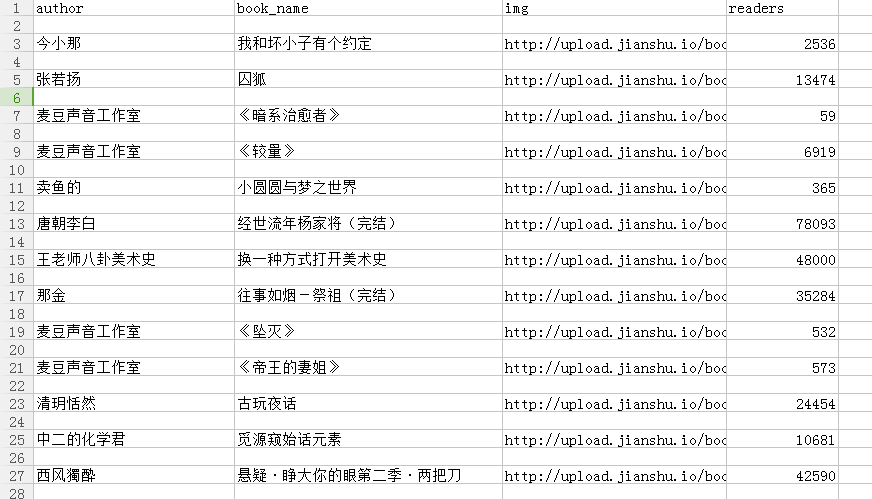
下载的照片:

初入爬虫,还有很多不足需要改正,还有很多知识需要学习,希望有疑问或建议的朋友多多指正或留言。谢谢。