连接数据
1、组合数据行(Combining rows of data)
此处使用的数据集与NYC Uber数据相关。 原始数据集包含所有原始Uber拾取位置的时间和经度。 使用实际数据的一小部分。已预先加载了三个DataFrame:uber1,其中包含2014年4月的数据,uber2(包含2014年5月的数据)和uber3(包含2014年6月的数据)。将这些DataFrame连接在一起,以便 生成的DataFrame包含所有三个月的数据。
urber1 [99 rows x 4 columns]

# Concatenate uber1, uber2, and uber3: row_concat
row_concat = pd.concat([uber1.head(),uber2.head(),uber3.head()])
# Print the shape of row_concat
print(row_concat.shape)
# Print the row_concat
print(row_concat)

成功连接了三个数据框架! row_concat的头部与uber1的头部相同,而row_concat的尾部与uber3的尾部相同。
2、组合数据列
将数据的逐列连接想象为从侧面而不是顶部和底部拼接数据。 要执行此操作,请使用相同的pd.concat()函数,但这次使用关键字参数axis = 1。 默认值axis = 0,用于行式连接。
使用之前简要介绍过的埃博拉数据集。 它已预先加载到名为ebola_melt的DataFrame中。 在此DataFrame中,患者的状态和国家/地区包含在一个列中。 此列已解析为新的DataFrame status_country,其中有单独的状态和国家/地区列。
ebola_melt和status_country DataFrame如下, 我们要做的是逐列连接它们以获得最终的干净DataFrame。

# Concatenate ebola_melt and status_country column-wise: ebola_tidy
ebola_tidy = pd.concat([ebola_melt,status_country],axis = 1)
# Print the shape of ebola_tidy
print(ebola_tidy.shape)
# Print the head of ebola_tidy
print(ebola_tidy.head())

3、查找和连接数据(Finding and concatenating data)
查找与模式匹配的文件
使用glob模块查找工作区中的所有csv文件。并以编程方式将它们加载到DataFrame中。
glob模块有一个名为glob的函数,它接受一个模式并返回工作目录中与该模式匹配的文件列表。
例如,如果你知道模式是part_单位数.csv,你可以将模式写为'part _?.csv'(它将匹配part_1.csv,part_2.csv,part_3.csv等)
同样,也可以找到所有带有'* .csv'的.csv文件,或带有'part_ *'的所有部分 。
? 通配符表示任意1个字符,*通配符表示任意数量的字符。
# Import necessary modules
import glob
import pandas as pd
# Write the pattern: pattern
pattern = '*.csv'
# Save all file matches: csv_files
csv_files = glob.glob(pattern)
# Print the file names
print(csv_files)
# Load the second file into a DataFrame: csv2
csv2 = pd.read_csv(csv_files[1])
# Print the head of csv2
print(csv2.head())
下一步是遍历此文件名列表,将其加载到DataFrame中,然后将其添加到DataFrames列表中,然后可以将它们连接在一起。
# Create an empty list: frames
frames = []
# Iterate over csv_files
for csv in csv_files:
# Read csv into a DataFrame: df
df = pd.read_csv(csv)
# Append df to frames
frames.append(df)
# Concatenate frames into a single DataFrame: uber
uber = pd.concat(frames)
# Print the shape of uber
print(uber.shape)
# Print the head of uber
print(uber.head())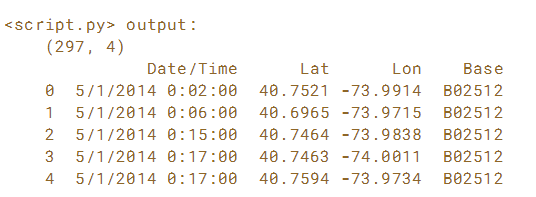
可以以编程方式将分解为多个较小部分的数据集组合在一起。 将发现野外的许多数据集将以这种方式存储,特别是以递增方式收集的数据。
4、合并数据(Merge data)
连接数据可以看做是同一个数据集进行连接,合并数据是多个数据集进行连接。
4.1 1对1数据合并
合并数据允许将不同的数据集组合到单个数据集中,以执行更复杂的分析。
使用调查数据,其中包含William Dyer,Frank Pabodie和Valentina Roerich在1920年末和1930年期间在南极洲探险时所采取的读数。 该数据集来自Software Carpentry SQL课程的sqlite数据库。已预先加载了两个DataFrame:site和visited。 如下为它们的结构和列名。 我们要做的是使用site的“name”列和visited的“site”列执行这两个DataFrame的一对一合并。

# Merge the DataFrames: o2o
o2o = pd.merge(left=site, right=visited, left_on='name', right_on='site')
# Print o2o
print(o2o)
请注意site DataFrame的'name'列与visited DataFrame的'site'列之间的一对一对应关系。 这使得1对1合并成为可能。
4.2 多对一数据合并
在多对一(或一对多)合并中,其中一个值将在输出中重复并循环使用。 也就是说,合并中的一个键不是唯一的。
在这里,已经预先加载了两个DataFrames site 和visited。 请注意,这次visited 'site'列有多个条目。
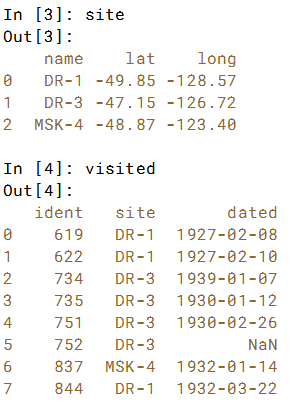
.merge()方法调用与上一练习中的1对1合并相同,但数据和输出将不同。
#Merge the DataFrames: m2o
m2o = pd.merge(left=site,right=visited,left_on='name',right_on='site')
#Merge the DataFrames: m2o
m2o = pd.merge(left=site,right=visited,left_on='name',right_on='site')
# Print m2o
print(m2o)

请注意在多对一合并期间'site数据是如何重复的!
4.3 多对多数据合并
当两个DataFrame没有用于合并的唯一键时,会发生最终合并方案。 使用之前的site visited DataFrame, 还有一个新的 survey DataFrame. 。 我们要做的是合并site和visited,就像之前的练习中所做的那样。然后将其结果与survey再合并。

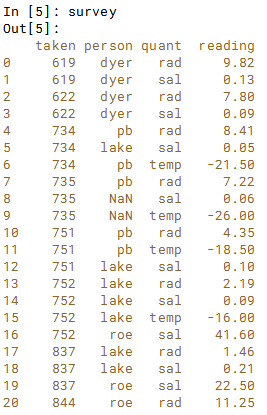
# Merge site and visited: m2m
m2m = pd.merge(left=site, right=visited, left_on='name', right_on='site')
# Merge m2m and survey: m2m
m2m = pd.merge(left=m2m, right=survey, left_on='ident', right_on='taken')
# Print the first 20 lines of m2m
print(m2m.head(20))
