“似然”用通俗的话来说就是可能性,极大似然就是最大的可能性。
似然函数是关于统计模型中的一组概率的函数(这些概率的真实值我们并不知道),似然函数的因变量值表示了模型中的概率参数的似然性(可能性)。
我们列出似然函数后,从真实事件中取得一批n个采样样本数据,最大似然估计会寻找基于我们的n个值的采样数据得到的关于的最可能的值(即,在所有可能的取值中,寻找一个值使这n个值的采样数据的“可能性”最大化)。
最大似然估计中采样需满足一个很重要的假设,就是所有的采样都是独立同分布的。
伯努利分布(Bernoulli distribution)又名两点分布或0-1分布,介绍伯努利分布前首先需要引入伯努利试验(Bernoulli trial)。
伯努利试验是只有两种可能结果的单次随机试验,即对于一个随机变量X而言:
P
(
X
=
1
)
=
p
P ( X = 1 ) = p
P ( X = 1 ) = p
P
(
X
=
0
)
=
1
−
p
P ( X = 0 ) = 1 - p
P ( X = 0 ) = 1 − p
伯努利试验可以表达为“是或否”的问题。
如果试验E是一个伯努利试验,将E独立重复地进行n次,则称这一串重复的独立试验为n重伯努利试验。
进行一次伯努利试验,成功(X=1)概率为p(0<=p<=1),失败(X=0)概率为1-p,则称随机变量X服从伯努利分布。
其概率质量函数为:
f
(
x
)
=
p
x
(
1
−
p
)
1
−
x
=
{
p
if
x
=
1
1
−
p
if
x
=
0
0
otherwise
f ( x ) = p ^ { x } ( 1 - p ) ^ { 1 - x } = \left\{ \begin{array} { l l } { p } & { \text { if } x = 1 } \\ { 1 - p } & { \text { if } x = 0 } \\ { 0 } & { \text { otherwise } } \end{array} \right.
f ( x ) = p x ( 1 − p ) 1 − x = ⎩ ⎨ ⎧ p 1 − p 0 if x = 1 if x = 0 otherwise
伯努利分布的
E
X
=
p
,
D
X
=
p
(
1
−
p
)
EX = p , DX = p ( 1 - p )
E X = p , D X = p ( 1 − p )
假设
P
(
X
=
1
)
=
p
,
P
(
X
=
0
)
=
1
−
p
P ( X = 1 ) = p , P ( X = 0 ) = 1 - p
P ( X = 1 ) = p , P ( X = 0 ) = 1 − p
P
(
X
)
=
p
X
(
1
−
p
)
1
−
X
P ( X ) = p ^ { X } ( 1 - p ) ^ { 1 - X }
P ( X ) = p X ( 1 − p ) 1 − X
假设我们现在有一组采样得到的数据D,则其对数似然函数为
max
p
log
P
(
D
)
=
max
p
log
∏
i
N
P
(
D
i
)
=
max
p
∑
i
log
P
(
D
i
)
=
max
p
∑
i
[
D
i
log
p
+
(
1
−
D
i
)
log
(
1
−
p
)
]
\begin{aligned} \max _ { p } \log P ( D ) & = \max _ { p } \log \prod _ { i } ^ { N } P \left( D _ { i } \right) \\ & = \max _ { p } \sum _ { i } \log P \left( D _ { i } \right) \\ & = \max _ { p } \sum _ { i } \left[ D _ { i } \log p + \left( 1 - D _ { i } \right) \log ( 1 - p ) \right] \end{aligned}
p max log P ( D ) = p max log i ∏ N P ( D i ) = p max i ∑ log P ( D i ) = p max i ∑ [ D i log p + ( 1 − D i ) log ( 1 − p ) ]
现在我们来求其极大似然估计,即求对数似然函数取极大值时函数的自变量的取值。
将上式对P求导可得:
∇
p
max
p
log
P
(
D
)
=
∑
i
N
[
D
i
1
p
+
(
1
−
D
i
)
1
p
−
1
]
\nabla _ { p } \max _ { p } \log P ( D ) = \sum _ { i } ^ { N } \left[ D _ { i } \frac { 1 } { p } + \left( 1 - D _ { i } \right) \frac { 1 } { p - 1 } \right]
∇ p max p log P ( D ) = ∑ i N [ D i p 1 + ( 1 − D i ) p − 1 1 ]
令导数为0,则有:
∑
i
N
[
D
i
1
p
+
(
1
−
D
i
)
1
p
−
1
]
=
0
\sum _ { i } ^ { N } \left[ D _ { i } \frac { 1 } { p } + \left( 1 - D _ { i } \right) \frac { 1 } { p - 1 } \right] = 0
∑ i N [ D i p 1 + ( 1 − D i ) p − 1 1 ] = 0
消去分母,得:
\sum _ { i } ^ { N } \left[ D _ { i } ( p - 1 ) + \left( 1 - D _ { i } \right) p \right] = 0
于是可得:
∑
i
N
(
p
−
D
i
)
=
0
\sum _ { i } ^ { N } \left( p - D _ { i } \right) = 0
∑ i N ( p − D i ) = 0
p
=
1
N
∑
i
D
i
p = \frac { 1 } { N } \sum _ { i } D _ { i }
p = N 1 ∑ i D i
这就是伯努利分布下最大似然估计求出的结果。
其实就是正态分布(Normal distribution),又叫高斯分布。
若随机变量X服从一个数学期望为
μ
\mu
μ
σ
2
\sigma ^ { 2 }
σ 2
X
∼
N
(
μ
,
σ
2
)
X \sim N \left( \mu , \sigma ^ { 2 } \right)
X ∼ N ( μ , σ 2 )
f
(
x
)
=
1
σ
2
π
e
−
(
x
−
μ
)
2
2
σ
2
f ( x ) = \frac { 1 } { \sigma \sqrt { 2 \pi } } e ^ { - \frac { ( x - \mu ) ^ { 2 } } { 2 \sigma ^ { 2 } } }
f ( x ) = σ 2 π
1 e − 2 σ 2 ( x − μ ) 2
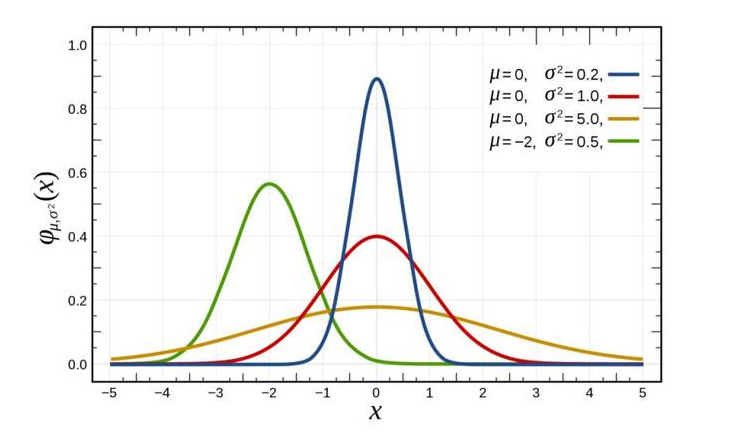
正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。下图中红色曲线就是标准正态分布。
我们已经知道高斯分布的概率密度函数为:
f
(
x
)
=
1
2
π
σ
2
e
−
(
x
−
μ
)
2
2
σ
2
f ( x ) = \frac { 1 } { \sqrt { 2 \pi \sigma ^ { 2 } } } e ^ { - \frac { ( x - \mu ) ^ { 2 } } { 2 \sigma ^ { 2 } } }
f ( x ) = 2 π σ 2
1 e − 2 σ 2 ( x − μ ) 2
那么其对数似然函数为:
max
log
P
(
D
)
=
max
p
log
∏
i
P
(
D
i
)
=
max
∑
i
N
log
P
(
D
i
)
=
max
∑
i
N
[
−
1
2
log
(
2
π
σ
2
)
−
(
D
i
−
μ
)
2
2
σ
2
]
=
max
[
−
N
2
log
(
2
π
σ
2
)
−
1
2
σ
2
∑
i
N
(
D
i
−
μ
)
2
]
\begin{aligned} \max \log P ( D ) & = \max _ { p } \log \prod _ { i } P \left( D _ { i } \right) \\ & = \max \sum _ { i } ^ { N } \log P \left( D _ { i } \right) \\ & = \max \sum _ { i } ^ { N } \left[ - \frac { 1 } { 2 } \log \left( 2 \pi \sigma ^ { 2 } \right) - \frac { \left( D _ { i } - \mu \right) ^ { 2 } } { 2 \sigma ^ { 2 } } \right] \\ & = \max \left[ - \frac { N } { 2 } \log \left( 2 \pi \sigma ^ { 2 } \right) - \frac { 1 } { 2 \sigma ^ { 2 } } \sum _ { i } ^ { N } \left( D _ { i } - \mu \right) ^ { 2 } \right] \end{aligned}
max log P ( D ) = p max log i ∏ P ( D i ) = max i ∑ N log P ( D i ) = max i ∑ N [ − 2 1 log ( 2 π σ 2 ) − 2 σ 2 ( D i − μ ) 2 ] = max [ − 2 N log ( 2 π σ 2 ) − 2 σ 2 1 i ∑ N ( D i − μ ) 2 ]
现在我们来求其极大似然估计,即求对数似然函数取极大值时函数的自变量的取值。
将上式对
μ
\mu
μ
∂
max
μ
log
P
(
D
)
∂
μ
=
−
1
σ
2
∑
i
N
(
μ
−
D
i
)
=
0
\frac { \partial \max _ { \mu } \log P ( D ) } { \partial \mu } = - \frac { 1 } { \sigma ^ { 2 } } \sum _ { i } ^ { N } \left( \mu - D _ { i } \right) = 0
∂ μ ∂ max μ log P ( D ) = − σ 2 1 ∑ i N ( μ − D i ) = 0
于是我们可得:
μ
=
1
N
∑
i
N
D
i
\mu = \frac { 1 } { N } \sum _ { i } ^ { N } D _ { i }
μ = N 1 ∑ i N D i
上式再对
σ
2
\sigma ^ { 2 }
σ 2
∂
max
σ
2
log
P
(
D
)
∂
σ
2
=
−
N
2
σ
2
+
1
2
σ
4
∑
i
N
(
D
i
−
μ
)
2
=
0
\frac { \partial \max _ { \sigma ^ { 2 } } \log P ( D ) } { \partial \sigma ^ { 2 } } = - \frac { N } { 2 \sigma ^ { 2 } } + \frac { 1 } { 2 \sigma ^ { 4 } } \sum _ { i } ^ { N } \left( D _ { i } - \mu \right) ^ { 2 } = 0
∂ σ 2 ∂ max σ 2 log P ( D ) = − 2 σ 2 N + 2 σ 4 1 ∑ i N ( D i − μ ) 2 = 0
于是我们可得:
σ
2
=
1
N
∑
i
N
(
D
i
−
μ
)
2
\sigma ^ { 2 } = \frac { 1 } { N } \sum _ { i } ^ { N } \left( D _ { i } - \mu \right) ^ { 2 }
σ 2 = N 1 ∑ i N ( D i − μ ) 2
假设X是一个离散型随机变量,其取值集合为X,概率分布函数为
p
(
x
)
=
Pr
(
X
=
x
)
,
x
∈
X
p ( x ) = \operatorname { Pr } ( X = x ) , x \in X
p ( x ) = P r ( X = x ) , x ∈ X
X
=
x
0
X = x_{0}
X = x 0
I
(
x
0
)
=
−
log
(
p
(
x
0
)
)
I \left( x _ { 0 } \right) = - \log \left( p \left( x _ { 0 } \right) \right)
I ( x 0 ) = − log ( p ( x 0 ) )
一个事件发生的概率越大,则它所携带的信息量就越小,而当
p
(
x
0
)
=
1
p ( x_{0} ) = 1
p ( x 0 ) = 1
如:
小明平时不爱学习,考试经常不及格,而小王是个勤奋学习的好学生,经常得满分,所以我们可以做如下假设:
事件A:小明考试及格,对应的概率
P
(
x
A
)
=
0.1
P ( x_{A} ) = 0.1
P ( x A ) = 0 . 1
I
(
x
A
)
=
−
log
(
0.1
)
=
3.3219
I ( x_{A} ) = - \log ( 0.1 ) = 3.3219
I ( x A ) = − log ( 0 . 1 ) = 3 . 3 2 1 9
P
(
x
A
)
=
0.999
P ( x_{A} ) = 0.999
P ( x A ) = 0 . 9 9 9
I
(
x
B
)
=
−
log
(
0.999
)
=
0.0014
I ( x_{B} ) = - \log ( 0.999 ) = 0.0014
I ( x B ) = − log ( 0 . 9 9 9 ) = 0 . 0 0 1 4
上面的结果可以看出,小明及格的可能性很低(十次考试只有一次及格),因此如果某次考试及格了,必然会引入较大的信息量,对应的I值也较高。而对于小王而言,考试及格是大概率事件,在事件B发生前,大家普遍认为事件B的发生几乎是确定的,因此当某次考试小王及格这个事件发生时并不会引入太多的信息量,相应的I值也非常的低。
还是通过上边的例子来说明,假设小明的考试结果是一个0-1分布
X
A
X_{A}
X A
在某次考试结果公布前,小明的考试结果有多大的不确定度呢?
你肯定会说:十有八九不及格!因为根据先验知识,小明及格的概率仅有0.1,90%的可能都是不及格的。
怎么来度量这个不确定度?
我们对所有可能结果带来的额外信息量求取均值(期望),其结果就能够衡量出小明考试成绩的不确定度。
即:
H
A
(
x
)
=
−
[
p
(
x
A
)
log
(
p
(
x
A
)
)
+
(
1
−
p
(
x
A
)
)
log
(
1
−
p
(
x
A
)
)
]
=
0.4690
\mathrm { H_{A} } ( \mathrm { x } ) = - [ \mathrm { p } ( \mathrm { x_{A} } ) \log ( \mathrm { p } ( \mathrm { x_{A} } ) ) + ( 1 - \mathrm { p } ( \mathrm x_{A} ) ) \log ( 1 - \mathrm { p } ( \mathrm { x_{A} } ) ) ] = 0.4690
H A ( x ) = − [ p ( x A ) log ( p ( x A ) ) + ( 1 − p ( x A ) ) log ( 1 − p ( x A ) ) ] = 0 . 4 6 9 0
小王的熵为:
H
B
(
x
)
=
−
[
p
(
x
B
)
log
(
p
(
x
B
)
)
+
(
1
−
p
(
x
B
)
)
log
(
1
−
p
(
x
B
)
)
]
=
0.0114
\mathrm { H_{B} } ( \mathrm { x } ) = - [ p ( x_{B}) \log ( p (x_{B}) ) + ( 1 - p ( x_{B}) ) \log ( 1 - p ( x_{B}) ) ] = 0.0114
H B ( x ) = − [ p ( x B ) log ( p ( x B ) ) + ( 1 − p ( x B ) ) log ( 1 − p ( x B ) ) ] = 0 . 0 1 1 4
虽然小明考试结果的不确定性较低,毕竟十次有9次都不及格,但是也比不上小王(1000次考试只有一次才可能不及格,结果相当的确定) 。
我们再假设一个成绩相对普通的学生小东,他及格的概率是P(xC)=0.5,即及格与否的概率是一样的,则他的熵为:
H
C
(
x
)
=
−
[
p
(
x
C
)
log
(
p
(
x
C
)
)
+
(
1
−
p
(
x
C
)
)
log
(
1
−
p
(
x
C
)
)
]
=
1
\mathrm { H_{C} } ( \mathrm { x } )= - [ p ( x_{C} ) \log ( p ( x_{C} ) ) + ( 1 - p ( x_{C} ) ) \log ( 1 - p ( x_{C} ) ) ] = 1
H C ( x ) = − [ p ( x C ) log ( p ( x C ) ) + ( 1 − p ( x C ) ) log ( 1 − p ( x C ) ) ] = 1
其熵为1,也就是说他的不确定性比前边两位同学要高很多,在成绩公布之前,很难准确猜测出他的考试结果。
从上面可以看出,熵其实是信息量的期望值,它是一个随机变量的确定性的度量。熵越大,变量的取值越不确定,反之就越确定。
对于一个随机变量X而言,它的所有可能取值的信息量的期望
E
[
I
(
x
)
]
E [I( x ) ]
E [ I ( x ) ]
X的熵定义为:
H
(
X
)
=
E
p
log
1
p
(
x
)
=
−
∑
x
∈
X
p
(
x
)
log
p
(
x
)
H ( X ) = E _ { p } \log \frac { 1 } { p ( x ) } = - \sum _ { x \in X } p ( x ) \log p ( x )
H ( X ) = E p log p ( x ) 1 = − ∑ x ∈ X p ( x ) log p ( x )
如果p(x)是连续型随机变量,则熵定义为:
H
(
X
)
=
−
∫
x
∈
X
p
(
x
)
log
p
(
x
)
d
x
H ( X ) = - \int _ { x \in X } p ( x ) \log p ( x ) d x
H ( X ) = − ∫ x ∈ X p ( x ) log p ( x ) d x
为保证有效性,这里约定当p(x)→0时,有p(x)logp(x)→0
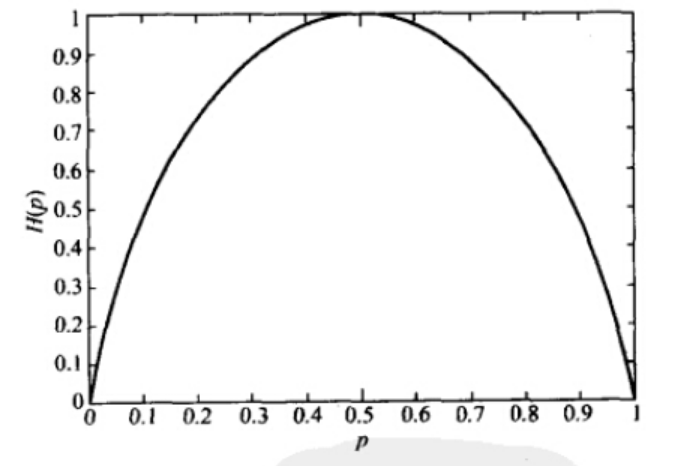
当X为0-1分布时,熵与概率p的关系如下图:
可以看出,当两种取值的可能性相等时,不确定度最大(此时没有任何先验知识),这个结论可以推广到多种取值的情况。
在图中也可以看出,当p=0或1时,熵为0,即此时X完全确定。
熵的单位随着公式中log运算的底数而变化,当底数为2时,单位为“比特”(bit),底数为e时,单位为“奈特”。
相对熵(relative entropy)又称为KL散度(Kullback-Leibler divergence),它是描述两个概率分布P和Q差异的一种方法。记为
D
K
L
(
p
∥
q
)
D _ { K L } ( p \| q )
D K L ( p ∥ q )
它度量当真实分布为p时,假设分布q的无效性。
两个分布越接近,那么KL散度越小;如果越远,散度就会越大。当两个随机分布相同时,它们的相对熵为零。KL散度的结果一定是非负的。
D
K
L
(
p
∥
q
)
=
E
p
[
log
p
(
x
)
q
(
x
)
]
=
∑
x
∈
X
p
(
x
)
log
p
(
x
)
q
(
x
)
D _ { K L } ( p \| q ) = E _ { p } \left[ \log \frac { p ( x ) } { q ( x ) } \right] = \sum _ { x \in \mathcal { X } } p ( x ) \log \frac { p ( x ) } { q ( x ) }
D K L ( p ∥ q ) = E p [ log q ( x ) p ( x ) ] = ∑ x ∈ X p ( x ) log q ( x ) p ( x )
=
∑
x
∈
X
[
p
(
x
)
log
p
(
x
)
−
p
(
x
)
log
q
(
x
)
]
= \sum _ { x \in \mathcal { X } } [ p ( x ) \log p ( x ) - p ( x ) \log q ( x ) ]
= ∑ x ∈ X [ p ( x ) log p ( x ) − p ( x ) log q ( x ) ]
=
∑
x
∈
X
p
(
x
)
log
p
(
x
)
−
∑
x
∈
X
p
(
x
)
log
q
(
x
)
= \sum _ { x \in \mathcal { X } } p ( x ) \log p ( x ) - \sum _ { x \in \mathcal { X } } p ( x ) \log q ( x )
= ∑ x ∈ X p ( x ) log p ( x ) − ∑ x ∈ X p ( x ) log q ( x )
=
−
H
(
p
)
−
∑
x
∈
X
p
(
x
)
log
q
(
x
)
= - H ( p ) - \sum _ { x \in \mathcal { X } } p ( x ) \log q ( x )
= − H ( p ) − ∑ x ∈ X p ( x ) log q ( x )
=
−
H
(
p
)
+
E
p
[
−
log
q
(
x
)
]
= - H ( p ) + E _ { p } [ - \log q ( x ) ]
= − H ( p ) + E p [ − log q ( x ) ]
=
H
p
(
q
)
−
H
(
p
)
= H _ { p } ( q ) - H ( p )
= H p ( q ) − H ( p )
为了保证连续性,做如下约定:
0
log
0
0
=
0
,
0
log
0
q
=
0
,
p
log
p
0
=
∞
0 \log \frac { 0 } { 0 } = 0 , \quad 0 \log \frac { 0 } { q } = 0 , p \log \frac { p } { 0 } = \infty
0 log 0 0 = 0 , 0 log q 0 = 0 , p log 0 p = ∞
显然,当p=q时,两者之间的相对熵
D
K
L
(
p
∥
q
)
=
0
D _ { K L } ( p \| q ) = 0
D K L ( p ∥ q ) = 0
H
p
(
q
)
H _ { p } ( q )
H p ( q )
相对熵的含义为:
D
K
L
(
p
∥
q
)
D _ { K L } ( p \| q )
D K L ( p ∥ q )
KL散度的结果是非负的,证明如下:
K
L
(
p
∥
q
)
=
∑
x
p
(
x
)
log
p
(
x
)
q
(
x
)
=
−
∑
x
p
(
x
)
log
q
(
x
)
p
(
x
)
\begin{aligned} \mathrm { KL } ( p \| q ) & = \sum _ { x } p ( x ) \log \frac { p ( x ) } { q ( x ) } \\ & = - \sum _ { x } p ( x ) \log \frac { q ( x ) } { p ( x ) } \end{aligned}
K L ( p ∥ q ) = x ∑ p ( x ) log q ( x ) p ( x ) = − x ∑ p ( x ) log p ( x ) q ( x )
对数函数是一个上凸函数,故上式:
⩾
−
log
[
∑
x
p
(
x
)
q
(
x
)
p
(
x
)
]
\geqslant - \log \left[ \sum _ { x } p ( x ) \frac { q ( x ) } { p ( x ) } \right]
⩾ − log [ ∑ x p ( x ) p ( x ) q ( x ) ]
=
−
log
[
∑
x
q
(
x
)
]
= - \log \left[ \sum _ { x } q ( x ) \right]
= − log [ ∑ x q ( x ) ]
=
−
log
1
=
0
= - \log 1 = 0
= − log 1 = 0
举例:
假设有两个随机变量X1和x2,各自服从一个高斯分布
N
1
(
μ
1
,
σ
1
2
)
N _ { 1 } \left( \mu _ { 1 } , \sigma _ { 1 } ^ { 2 } \right)
N 1 ( μ 1 , σ 1 2 )
N
2
(
μ
2
,
σ
2
2
)
N _ { 2 } \left( \mu _ { 2 } , \sigma _ { 2 } ^ { 2 } \right)
N 2 ( μ 2 , σ 2 2 )
已知高斯分布的概率密度函数为:
N
(
μ
,
σ
)
=
1
2
π
σ
2
e
(
x
−
μ
)
2
2
σ
2
N ( \mu , \sigma ) = \frac { 1 } { \sqrt { 2 \pi \sigma ^ { 2 } } } e ^ { \frac { ( x - \mu ) ^ { 2 } } { 2 \sigma ^ { 2 } } }
N ( μ , σ ) = 2 π σ 2
1 e 2 σ 2 ( x − μ ) 2
故
K
L
(
p
1
∥
p
2
)
\mathrm { KL } ( p 1 \| p 2 )
K L ( p 1 ∥ p 2 )
∫
p
1
(
x
)
log
p
1
(
x
)
p
2
(
x
)
d
x
=
∫
p
1
(
x
)
(
log
p
1
(
x
)
−
log
p
2
(
x
)
)
d
x
=
∫
p
1
(
x
)
(
log
1
2
π
σ
1
2
e
(
x
−
μ
)
2
2
σ
1
2
−
log
1
2
π
σ
2
2
e
(
x
−
μ
2
)
2
2
σ
2
2
)
d
x
\begin{aligned} & \int p _ { 1 } ( x ) \log \frac { p _ { 1 } ( x ) } { p _ { 2 } ( x ) } \mathrm { d } x \\ = & \int p _ { 1 } ( x ) \left( \log p _ { 1 } ( x ) - \log p _ { 2 } ( x ) \right) \mathrm { d } x \\ = & \int p _ { 1 } ( x ) \left( \log \frac { 1 } { \sqrt { 2 \pi \sigma _ { 1 } ^ { 2 } } } e ^ { \frac { ( x - \mu ) ^ { 2 } } { 2 \sigma _ { 1 } ^ { 2 } } } - \log \frac { 1 } { \sqrt { 2 \pi \sigma _ { 2 } ^ { 2 } } } e ^ { \frac { \left( x - \mu _ { 2 } \right) ^ { 2 } } { 2 \sigma _ { 2 } ^ { 2 } } ) } \mathrm { d } x \right. \end{aligned}
= = ∫ p 1 ( x ) log p 2 ( x ) p 1 ( x ) d x ∫ p 1 ( x ) ( log p 1 ( x ) − log p 2 ( x ) ) d x ∫ p 1 ( x ) ( log 2 π σ 1 2
1 e 2 σ 1 2 ( x − μ ) 2 − log 2 π σ 2 2
1 e 2 σ 2 2 ( x − μ 2 ) 2 ) d x
=
∫
p
1
(
x
)
(
−
1
2
log
2
π
−
log
σ
1
−
(
x
−
μ
1
)
2
2
σ
1
2
+
1
2
log
2
π
+
log
σ
2
+
(
x
−
μ
2
)
2
2
σ
2
2
)
d
x
= \int p _ { 1 } ( x ) \left( - \frac { 1 } { 2 } \log 2 \pi - \log \sigma _ { 1 } - \frac { \left( x - \mu _ { 1 } \right) ^ { 2 } } { 2 \sigma _ { 1 } ^ { 2 } } + \frac { 1 } { 2 } \log 2 \pi + \log \sigma _ { 2 } + \frac { \left( x - \mu _ { 2 } \right) ^ { 2 } } { 2 \sigma _ { 2 } ^ { 2 } } \right) \mathrm { d } x
= ∫ p 1 ( x ) ( − 2 1 log 2 π − log σ 1 − 2 σ 1 2 ( x − μ 1 ) 2 + 2 1 log 2 π + log σ 2 + 2 σ 2 2 ( x − μ 2 ) 2 ) d x
=
∫
p
1
(
x
)
(
log
σ
2
σ
1
+
[
(
x
−
μ
2
)
2
2
σ
2
2
−
(
x
−
μ
1
)
2
2
σ
1
2
]
)
d
x
= \int p _ { 1 } ( x ) \left( \log \frac { \sigma _ { 2 } } { \sigma _ { 1 } } + \left[ \frac { \left( x - \mu _ { 2 } \right) ^ { 2 } } { 2 \sigma _ { 2 } ^ { 2 } } - \frac { \left( x - \mu _ { 1 } \right) ^ { 2 } } { 2 \sigma _ { 1 } ^ { 2 } } \right] \right) \mathrm { d } x
= ∫ p 1 ( x ) ( log σ 1 σ 2 + [ 2 σ 2 2 ( x − μ 2 ) 2 − 2 σ 1 2 ( x − μ 1 ) 2 ] ) d x
=
∫
(
log
σ
2
σ
1
)
p
1
(
x
)
d
x
+
∫
(
(
x
−
μ
2
)
2
2
σ
2
2
)
p
1
(
x
)
d
x
−
∫
(
(
x
−
μ
1
)
2
2
σ
1
2
)
p
1
(
x
)
d
x
= \int \left( \log \frac { \sigma _ { 2 } } { \sigma _ { 1 } } \right) p _ { 1 } ( x ) \mathrm { d } x + \int \left( \frac { \left( x - \mu _ { 2 } \right) ^ { 2 } } { 2 \sigma _ { 2 } ^ { 2 } } \right) p _ { 1 } ( x ) \mathrm { d } x - \int \left( \frac { \left( x - \mu _ { 1 } \right) ^ { 2 } } { 2 \sigma _ { 1 } ^ { 2 } } \right) p _ { 1 } ( x ) \mathrm { d } x
= ∫ ( log σ 1 σ 2 ) p 1 ( x ) d x + ∫ ( 2 σ 2 2 ( x − μ 2 ) 2 ) p 1 ( x ) d x − ∫ ( 2 σ 1 2 ( x − μ 1 ) 2 ) p 1 ( x ) d x
=
log
σ
2
σ
1
+
1
2
σ
2
2
∫
(
(
x
−
μ
2
)
2
)
p
1
(
x
)
d
x
−
1
2
σ
1
2
∫
(
(
x
−
μ
1
)
2
)
p
1
(
x
)
d
x
= \log \frac { \sigma _ { 2 } } { \sigma _ { 1 } } + \frac { 1 } { 2 \sigma _ { 2 } ^ { 2 } } \int \left( \left( x - \mu _ { 2 } \right) ^ { 2 } \right) p _ { 1 } ( x ) \mathrm { d } x - \frac { 1 } { 2 \sigma _ { 1 } ^ { 2 } } \int \left( \left( x - \mu _ { 1 } \right) ^ { 2 } \right) p _ { 1 } ( x ) \mathrm { d } x
= log σ 1 σ 2 + 2 σ 2 2 1 ∫ ( ( x − μ 2 ) 2 ) p 1 ( x ) d x − 2 σ 1 2 1 ∫ ( ( x − μ 1 ) 2 ) p 1 ( x ) d x
最后一步的右边最后一项就是连续型随机变量的方差计算公式。
连续型随机变量的方差计算公式为:
D
(
X
)
=
σ
2
=
∫
−
∞
∞
(
x
−
μ
)
2
f
(
x
)
d
x
D ( X ) = \sigma ^ { 2 } = \int _ { - \infty } ^ { \infty } ( x - \mu ) ^ { 2 } f ( x ) d x
D ( X ) = σ 2 = ∫ − ∞ ∞ ( x − μ ) 2 f ( x ) d x
可化简为:
D
(
X
)
=
∫
x
2
f
(
x
)
d
x
−
μ
2
=
E
(
X
2
)
−
[
E
(
X
)
]
2
D ( X ) = \int x ^ { 2 } f ( x ) d x - \mu ^ { 2 } = E \left( X ^ { 2 } \right) - [ E ( X ) ] ^ { 2 }
D ( X ) = ∫ x 2 f ( x ) d x − μ 2 = E ( X 2 ) − [ E ( X ) ] 2
证明:
由数学期望的性质得
D
(
X
)
=
E
{
[
X
−
E
(
X
)
]
2
}
=
E
{
X
2
−
2
X
E
(
X
)
+
[
E
(
X
)
]
2
}
D ( X ) = E \left\{ [ X - E ( X ) ] ^ { 2 } \right\} = E \left\{ X ^ { 2 } - 2 X E ( X ) + [ E ( X ) ] ^ { 2 } \right\}
D ( X ) = E { [ X − E ( X ) ] 2 } = E { X 2 − 2 X E ( X ) + [ E ( X ) ] 2 }
=
E
(
X
2
)
−
2
E
(
X
)
E
(
X
)
+
[
E
(
X
)
]
2
=
E
(
X
2
)
−
[
E
(
X
)
]
2
= E \left( X ^ { 2 } \right) - 2 E ( X ) E ( X ) + [ E ( X ) ] ^ { 2 } = E \left( X ^ { 2 } \right) - [ E ( X ) ] ^ { 2 }
= E ( X 2 ) − 2 E ( X ) E ( X ) + [ E ( X ) ] 2 = E ( X 2 ) − [ E ( X ) ] 2
所以例子中最后一步的右边最后一项可计算出值为1/2。
故上式等于:
=
log
σ
2
σ
1
+
1
2
σ
2
2
∫
(
(
x
−
μ
2
)
2
)
p
1
(
x
)
d
x
−
1
2
= \log \frac { \sigma _ { 2 } } { \sigma _ { 1 } } + \frac { 1 } { 2 \sigma _ { 2 } ^ { 2 } } \int \left( \left( x - \mu _ { 2 } \right) ^ { 2 } \right) p _ { 1 } ( x ) \mathrm { d } x - \frac { 1 } { 2 }
= log σ 1 σ 2 + 2 σ 2 2 1 ∫ ( ( x − μ 2 ) 2 ) p 1 ( x ) d x − 2 1
=
log
σ
2
σ
1
+
1
2
σ
2
2
∫
(
(
x
−
μ
1
+
μ
1
−
μ
2
)
2
)
p
1
(
x
)
d
x
−
1
2
= \log \frac { \sigma _ { 2 } } { \sigma _ { 1 } } + \frac { 1 } { 2 \sigma _ { 2 } ^ { 2 } } \int \left( \left( x - \mu _ { 1 } + \mu _ { 1 } - \mu _ { 2 } \right) ^ { 2 } \right) p _ { 1 } ( x ) \mathrm { d } x - \frac { 1 } { 2 }
= log σ 1 σ 2 + 2 σ 2 2 1 ∫ ( ( x − μ 1 + μ 1 − μ 2 ) 2 ) p 1 ( x ) d x − 2 1
=
log
σ
2
σ
1
+
1
2
σ
2
2
[
∫
(
x
−
μ
1
)
2
p
1
(
x
)
d
x
+
∫
(
μ
1
−
μ
2
)
2
p
1
(
x
)
d
x
+
2
∫
(
x
−
μ
1
)
(
μ
1
−
μ
2
)
p
1
(
x
)
d
x
]
−
1
2
= \log \frac { \sigma _ { 2 } } { \sigma _ { 1 } } + \frac { 1 } { 2 \sigma _ { 2 } ^ { 2 } } \left[ \int \left( x - \mu _ { 1 } \right) ^ { 2 } p _ { 1 } ( x ) \mathrm { d } x + \int \left( \mu _ { 1 } - \mu _ { 2 } \right) ^ { 2 } p _ { 1 } ( x ) \mathrm { d } x \right.+ 2 \int \left( x - \mu _ { 1 } \right) \left( \mu _ { 1 } - \mu _ { 2 } \right) p _ { 1 } ( x ) \mathrm { d } x ] - \frac { 1 } { 2 }
= log σ 1 σ 2 + 2 σ 2 2 1 [ ∫ ( x − μ 1 ) 2 p 1 ( x ) d x + ∫ ( μ 1 − μ 2 ) 2 p 1 ( x ) d x + 2 ∫ ( x − μ 1 ) ( μ 1 − μ 2 ) p 1 ( x ) d x ] − 2 1
=
log
σ
2
σ
1
+
1
2
σ
2
2
[
∫
(
x
−
μ
1
)
2
p
1
(
x
)
d
x
+
(
μ
1
−
μ
2
)
2
]
−
1
2
= \log \frac { \sigma _ { 2 } } { \sigma _ { 1 } } + \frac { 1 } { 2 \sigma _ { 2 } ^ { 2 } } \left[ \int \left( x - \mu _ { 1 } \right) ^ { 2 } p _ { 1 } ( x ) \mathrm { d } x + \left( \mu _ { 1 } - \mu _ { 2 } \right) ^ { 2 } \right] - \frac { 1 } { 2 }
= log σ 1 σ 2 + 2 σ 2 2 1 [ ∫ ( x − μ 1 ) 2 p 1 ( x ) d x + ( μ 1 − μ 2 ) 2 ] − 2 1
=
log
σ
2
σ
1
+
σ
1
2
+
(
μ
1
−
μ
2
)
2
2
σ
2
2
−
1
2
= \log \frac { \sigma _ { 2 } } { \sigma _ { 1 } } + \frac { \sigma _ { 1 } ^ { 2 } + \left( \mu _ { 1 } - \mu _ { 2 } \right) ^ { 2 } } { 2 \sigma _ { 2 } ^ { 2 } } - \frac { 1 } { 2 }
= log σ 1 σ 2 + 2 σ 2 2 σ 1 2 + ( μ 1 − μ 2 ) 2 − 2 1
如果假设N2是一个
μ
2
=
0
,
σ
2
2
=
1
\mu _ { 2 } = 0 , \sigma _ { 2 } ^ { 2 } = 1
μ 2 = 0 , σ 2 2 = 1
μ
2
=
0
,
σ
2
2
=
1
\mu _ { 2 } = 0 , \sigma _ { 2 } ^ { 2 } = 1
μ 2 = 0 , σ 2 2 = 1
K
L
(
μ
1
,
σ
1
)
=
−
log
σ
1
+
σ
1
2
+
μ
1
2
2
−
1
2
\mathrm { KL } \left( \mu _ { 1 } , \sigma _ { 1 } \right) = - \log \sigma _ { 1 } + \frac { \sigma _ { 1 } ^ { 2 } + \mu _ { 1 } ^ { 2 } } { 2 } - \frac { 1 } { 2 }
K L ( μ 1 , σ 1 ) = − log σ 1 + 2 σ 1 2 + μ 1 2 − 2 1
显然,当
μ
1
=
0
,
σ
1
=
1
\mu _ { 1 } = 0 , \sigma _ { 1 } = 1
μ 1 = 0 , σ 1 = 1
交叉熵容易跟相对熵搞混,二者联系紧密,但又有所区别。
假设有两个分布p,q,则它们在给定样本集上的交叉熵定义如下:
C
E
H
(
p
,
q
)
=
E
p
[
−
log
q
]
=
−
∑
x
∈
X
p
(
x
)
log
q
(
x
)
=
H
(
p
)
+
D
K
L
(
p
∥
q
)
C E H ( p , q ) = E _ { p } [ - \log q ] = - \sum _ { x \in \mathcal { X } } p ( x ) \log q ( x ) = H ( p ) + D _ { K L } ( p \| q )
C E H ( p , q ) = E p [ − log q ] = − ∑ x ∈ X p ( x ) log q ( x ) = H ( p ) + D K L ( p ∥ q )
可以看出,交叉熵与上一节定义的相对熵仅相差了
H
(
p
)
\mathrm { H } ( \mathrm { p } )
H ( p )
当p已知时,可以把
H
(
p
)
\mathrm { H } ( \mathrm { p } )
H ( p )
特别的,在logistic regression中:
p:真实样本分布,服从参数为p的0-1分布,即
X
∼
B
(
1
,
p
)
X \sim B ( 1 , p )
X ∼ B ( 1 , p )
X
∼
B
(
1
,
q
)
X \sim B ( 1 , q )
X ∼ B ( 1 , q )
则两者的交叉熵为:
C
E
H
(
p
,
q
)
C E H ( p , q )
C E H ( p , q )
=
−
∑
x
∈
X
p
(
x
)
log
q
(
x
)
= - \sum _ { x \in \mathcal { X } } \mathbf { p } ( \mathbf { x } ) \log \mathbf { q } ( \mathbf { x } )
= − ∑ x ∈ X p ( x ) log q ( x )
=
−
[
P
p
(
x
=
1
)
log
P
q
(
x
=
1
)
+
P
p
(
x
=
0
)
log
P
q
(
x
=
0
)
]
= - \left[ P _ { p } ( x = 1 ) \log P _ { q } ( x = 1 ) + P _ { p } ( x = 0 ) \log P _ { q } ( x = 0 ) \right]
= − [ P p ( x = 1 ) log P q ( x = 1 ) + P p ( x = 0 ) log P q ( x = 0 ) ]
=
−
[
p
log
q
+
(
1
−
p
)
log
(
1
−
q
)
]
= - [ p \log q + ( 1 - p ) \log ( 1 - q ) ]
= − [ p log q + ( 1 − p ) log ( 1 − q ) ]
=
−
[
y
log
h
θ
(
x
)
+
(
1
−
y
)
log
(
1
−
h
θ
(
x
)
)
]
= - \left[ \mathbf { y } \log \mathbf { h } _ { \theta } ( x ) + ( 1 - \mathbf { y } ) \log \left( 1 - \mathbf { h } _ { \theta } ( x ) \right) \right]
= − [ y log h θ ( x ) + ( 1 − y ) log ( 1 − h θ ( x ) ) ]
对所有训练样本取均值得:
−
1
m
∑
i
=
1
m
[
y
(
i
)
log
h
θ
(
x
(
i
)
)
+
(
1
−
y
(
i
)
)
log
(
1
−
h
θ
(
x
(
i
)
)
)
]
- \frac { 1 } { m } \sum _ { i = 1 } ^ { m } \left[ y ^ { ( i ) } \log h _ { \theta } \left( x ^ { ( i ) } \right) + \left( 1 - y ^ { ( i ) } \right) \log \left( 1 - h _ { \theta } \left( x ^ { ( i ) } \right) \right) \right]
− m 1 ∑ i = 1 m [ y ( i ) log h θ ( x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ]
这个结果与通过最大似然估计方法(求对数似然函数的极值)求出来的结果一致。
二分类问题的loss函数(输入数据是softmax或sigmoid函数的输出):
loss
=
−
1
n
∑
[
y
ln
a
+
(
1
−
y
)
ln
(
1
−
a
)
]
\operatorname { loss } = - \frac { 1 } { n } \sum [ y \ln a + ( 1 - y ) \ln ( 1 - a ) ]
l o s s = − n 1 ∑ [ y ln a + ( 1 − y ) ln ( 1 − a ) ]
多分类问题使用的loss函数(输入数据是softmax或sigmoid函数的输出):
l
o
s
s
=
−
∑
i
y
i
ln
a
i
loss = - \sum _ { i } y _ { i } \ln a _ { i }
l o s s = − ∑ i y i ln a i
如果是在tensorflow中,loss函数往往写成下面这两种形式之一:
loss = tf.reduce_mean(- tf.reduce_sum(y * tf.log(pred), 1))
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=output, labels=Y))
举例:
假如我们的数据集是mnist,这是一个0-9的手写体数字的数据集,如果我们从其中抽出一个图片,总共只有10种可能,即数字0-9。
一般情况下我们每一次训练都是取一个批样本(batch_size)。
我们现在假设batch_size为1,即每次训练只取一个样本。我们将这个批样本输入神经网络中进行计算,最后经过softmax函数或sigmoid函数后得到一个输出数据,这个输出数据是我们预测的这batchsize个图片的标签向量,它代表了我们的神经网络预测的这输入的batchsize个样本的每个图片分别是哪一类图片(具体到mnist数据集里,就是图片是数字0-9中的哪一个)。
预测的标签向量的形式为:
[
a
0
,
a
1
,
a
2
,
a
3
,
a
4
,
a
5
,
a
6
,
a
7
,
a
8
,
a
9
]
[ a 0 , a 1 , a 2 , a 3 , a 4 , a 5 , a 6 , a 7 , a 8 , a 9 ]
[ a 0 , a 1 , a 2 , a 3 , a 4 , a 5 , a 6 , a 7 , a 8 , a 9 ]
我们的真实标签也是一个有着同样元素数量的向量,一般写作:
[
y
0
,
y
1
,
y
2
,
y
3
,
y
4
,
y
5
,
y
6
,
y
7
,
y
8
,
y
9
]
[ y 0 , y 1 , y 2 , y 3 , y 4 , y 5 , y 6 , y 7 , y 8 , y 9 ]
[ y 0 , y 1 , y 2 , y 3 , y 4 , y 5 , y 6 , y 7 , y 8 , y 9 ]
真实标签中除了代表自己是哪个数字的那个下标的元素是1,其他都是0,如[0,0,0,0,0,1,0,0,0,0]代表数字5。
如果我们把一个图片属于数字0-9中的一个看成10个独立事件,其实这个标签向量代表的就是10个独立事件的概率。
而真实标签代表的就是我们抽取的一个样本。这一个样本中必然会发生一个事件,而其他9个事件都不发生。
现在再看看多分类的loss函数:
l
o
s
s
=
−
∑
i
y
i
ln
a
i
loss = - \sum _ { i } y _ { i } \ln a _ { i }
l o s s = − ∑ i y i ln a i
显然对于mnist问题,我们的loss函数就是i=10时的情况。
为什么有一个负号?
因为ai总是在0到1之间,而yi值不是0就是1,这就导致每一项要么为0,要么是负数。而tensorflow的优化器是向着loss值降低的方向优化的,并且最终目标是loss值尽可能接近0,所以要求loss函数是一个大于0的值。因此我们加一个负号。
在机器学习中,我们通过tensorflow使用梯度下降或其他的优化方法,不断地更新权重参数,最终使得loss函数从一个正值减小到接近0(也就是似然函数从原来的负值逐渐接近0,在这个mnist的例子中显然0是似然函数的极大值)求出一个接近似然函数极大值的点,这就是我们求出的一个接近极大似然估计值的一组ai值。
也就是说,loss函数值越小,求得的ai值代表的概率越有可能是真实概率。
二分类的loss函数也与上面的原理类似。
假如batch_size为100(或大于1的其他数),我们的loss函数又是如何处理的呢?
看看我们在tensorflow中的loss函数变量的定义就知道了:
loss = tf.reduce_mean(- tf.reduce_sum(y * tf.log(pred), 1))
这个loss函数的意思是,yi与对应的ln(ai)相乘后,使用tf.reduce_sum函数将相乘后的这个向量(相乘后的向量形式是shape=(batch_size、10)的张量)按行求和(其实就是求出了每一个样本的loss值),然后按列求和后求平均值。
也就是说,当输入一批样本时,我们使用tensorflow优化器更新权重的依据是这一批样本的loss值的平均值。然后通过求loss对各个权重的梯度(链式求导法则),再用梯度更新各个权重。