前段时间尝试爬取了网易云音乐的歌曲,这次打算爬取QQ音乐的歌曲信息。网易云音乐歌曲列表是通过iframe展示的,可以借助Selenium获取到iframe的页面元素,
而QQ音乐采用的是异步加载的方式,套路不一样,这是主流的页面加载方式,爬取有点难度,不过也是对自己的一个挑战。
二、Python爬取QQ音乐单曲
之前看的慕课网的一个视频, 很好地讲解了一般编写爬虫的步骤,我们也按这个来。
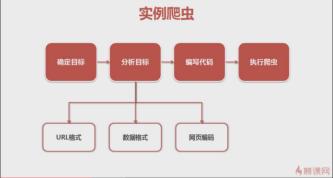
爬虫步骤
1.确定目标
首先我们要明确目标,本次爬取的是QQ音乐歌手刘德华的单曲。
(百度百科)->分析目标(策略:url格式(范围)、数据格式、网页编码)->编写代码->执行爬虫
2.分析目标
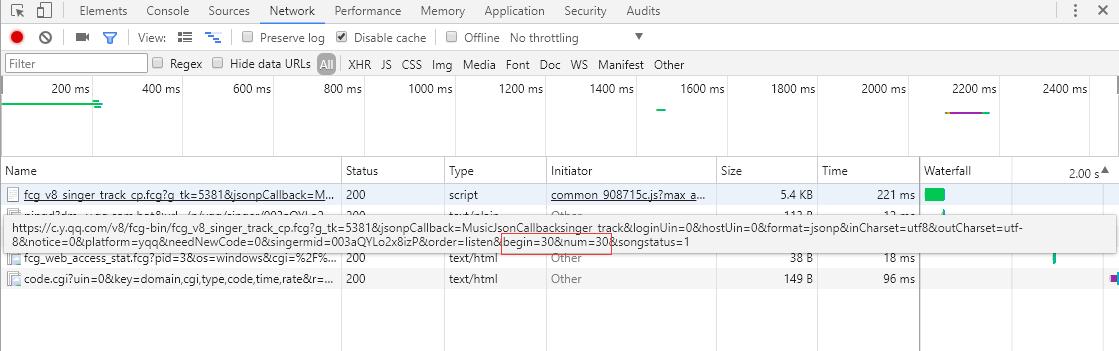
歌曲链接:https://y.qq.com/n/yqq/singer/003aQYLo2x8izP.html#tab=song&
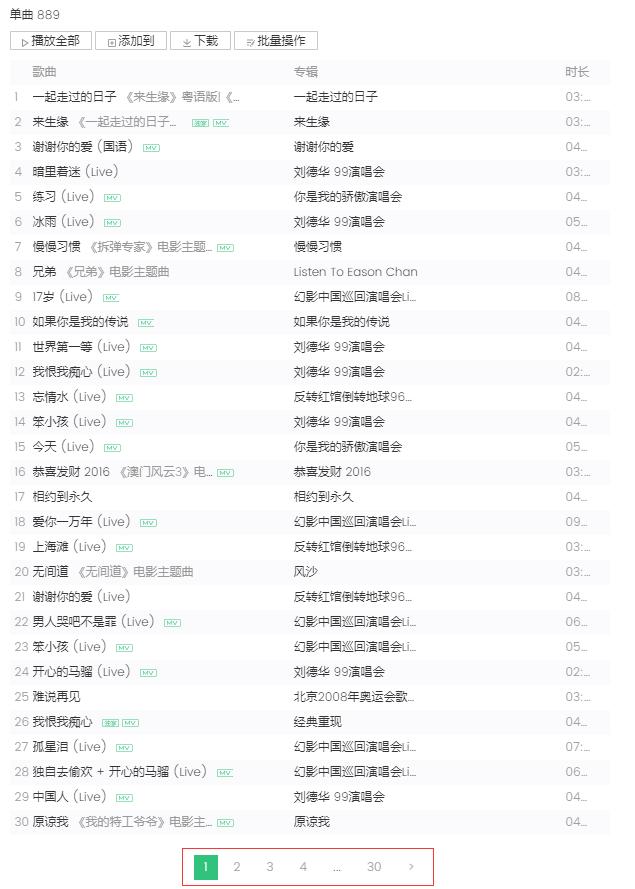
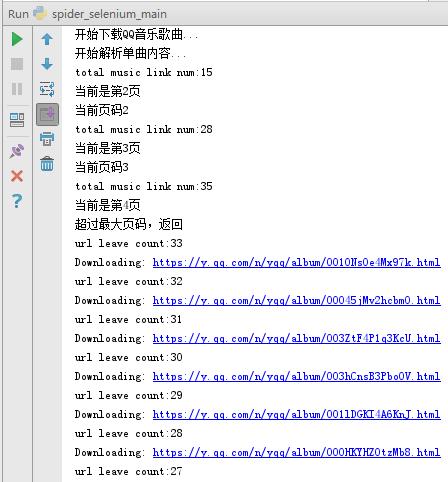
从左边的截图可以知道单曲采用分页的方式排列歌曲信息,每页显示30条,总共30页。点击页码或者最右边的">"会跳转到下一页,浏览器会向服务器发送ajax异步请求,从链接可以看到begin和num参数,分别代表起始歌曲下标(截图是第2页,起始下标是30)和一页返回30条,服务器响应返回json格式的歌曲信息(MusicJsonCallbacksinger_track({"code":0,"data":{"list":[{"Flisten_count1":......]})),如果只是单独想获取歌曲信息,可以直接拼接链接请求和解析返回的json格式的数据。这里不采用直接解析数据格式的方法,我采用的是Python Selenium方式,每获取和解析完一页的单曲信息,点击 ">" 跳转到下一页继续解析,直至解析并记录所有的单曲信息。最后请求每个单曲的链接,获取详细的单曲信息。
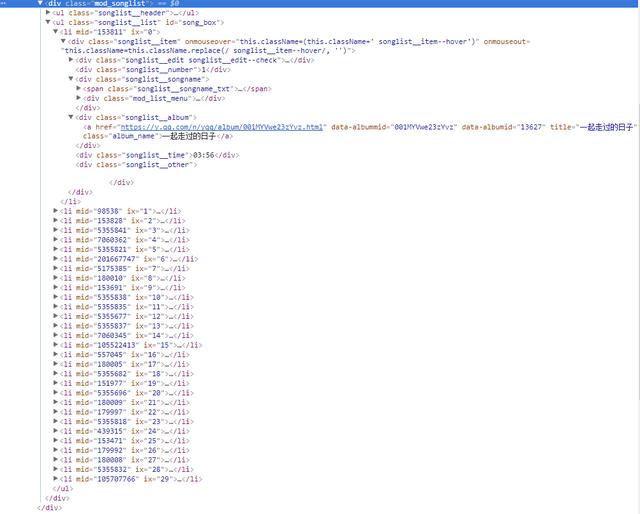
右边的截图是网页的源码,所有歌曲信息都在类名为mod_songlist的div浮层里面,类名为songlist_list的无序列表ul下,每个子元素li展示一个单曲,类名为songlist__album下的a标签,包含单曲的链接,名称和时长等。
3.编写代码
1)下载网页内容,这里使用Python 的Urllib标准库,自己封装了一个download方法:
def download(url, user_agent='wswp', num_retries=2):
2)解析网页内容,这里使用第三方插件BeautifulSoup,具体可以参考BeautifulSoup API 。
def music_scrapter(html, page_num=0):
def get_music():
4.执行爬虫
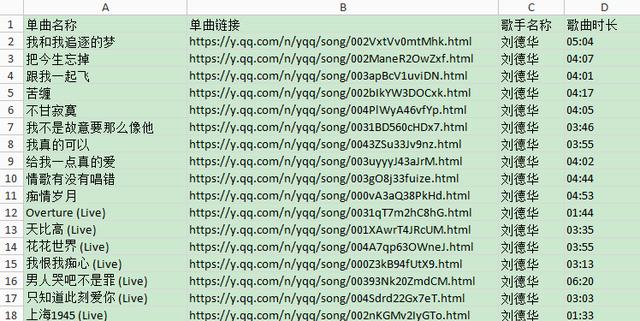
爬虫跑起来了,一页一页地去爬取专辑的链接,并保存到集合中,最后通过get_music()方法获取单曲的名称,链接,歌手名称和时长并保存到Excel文件中。
源码 群 960410445
三、Python爬取QQ音乐单曲总结
1.单曲采用的是分页方式,切换下一页是通过异步ajax请求从服务器获取json格式的数据并渲染到页面,浏览器地址栏链接是不变的,不能通过拼接链接来请求。一开始想过都通过Python Urllib库来模拟ajax请求,后来想想还是用Selenium。Selenium能够很好地模拟浏览器真实的操作,页面元素定位也很方便,模拟单击下一页,不断地切换单曲分页,再通过BeautifulSoup解析网页源码,获取单曲信息。
2.url链接管理器,采用集合数据结构来保存单曲链接,为什么要使用集合?因为多个单曲可能来自同一专辑(专辑网址一样),这样可以减少请求次数。
class UrlManager(object):
def add_new_url(self, url):
3.通过Python第三方插件openpyxl读写Excel十分方便,把单曲信息通过Excel文件可以很好地保存起来。
def write_to_excel(self, content):
四、后语
最后还是要庆祝下,毕竟成功把QQ音乐的单曲信息爬取下来了。本次能够成功爬取单曲,Selenium功不可没,这次只是用到了selenium一些简单的功能,后续会更加深入学习Selenium,不仅在爬虫方面还有UI自动化。
后续还需要优化的点:
1.下载的链接比较多,一个一个下载起来比较慢,后面打算用多线程并发下载。
2.下载速度过快,为了避免服务器禁用IP,后面还要对于同一域名访问过于频繁的问题,有个等待机制,每个请求之间有个等待间隔。
3. 解析网页是一个重要的过程,可以采用正则表达式,BeautifulSoup和lxml,目前采用的是BeautifulSoup库, 在效率方面,BeautifulSoup没lxml效率高,后面会尝试采用lxml。