前段时间公司发布新需求,要求用户点击按钮可以导出pdf或者html到本地,pdf中要包含可点击跳转的目录,要分页记录页码,还有页眉和页脚,和后台的小哥哥配合试了好多方法,最终完成的效果还不错,在这里做个记录。
需求
- 点击导出html报告,则导出html文件到本地
- 点击导出pdf报告,则导出pdf到本地
言归正传
因为设计也比较给力,直接把pdf样式设计成模板了,
所以前端的工作就是按照样式生成html页面扔给后台。
我之前也看了很多博客,查找了很多工具和插件,下面先做个简单介绍。
1.jspdf与html2Canvas
- 优点在于使用简单,前端就可以实现,完全不需要后端配合。
- 因为要把html页面写进canvas里,利用canvas生成图片写进pdf,所以生成的pdf不是很清晰
- 另外因为是利用canvas生成图片,所以分页效果也超级差的
- 如果页面引用了图片的话,那么必须是在服务器环境下导出的pdf才能正确显示图片
- 感兴趣的小伙伴可以去这里点击查看详情学习,有现成的demo,代码简单。
2.pdfmake
- 优点和上边一样,并且支持自适应布局
- 缺点是需要引入字体,而且字体文件不仅大,而且生成过程很繁琐
- 感兴趣的小伙伴去这里点击查看详情
3.我选择的这种
- 后台用的python3,安装的工具是 weasyprint ,这个比较成熟,可以用来把html生成pdf,参考网址点击查看详情
- 前端的静态页面不需要ajax 获取数据,放到后端直接用jinja2 模板或者框架自带的模板替换数据就可以,比如下面这段代码中,title 是后台返回的文章标题,那么数据在后台可以这样引用由Mustache语法进行解析:
<h1>{{ title }}</h1>- 这个 weasyprint 支持自动分页,而且分页效果比较好
- 下面是重点了,为了满足产品需求,查阅了很多文档才发觉的,就是如何让生成的pdf带有目录跳转,如何配置页眉页脚以及页码等。
- 首先要了解css的一个打印选项模块,叫做@page点击查看详情
- 下面这段代码 print.css 是用来生成页眉页脚及页码的
@page {
size: A4;/*设置导出的pdf的大小*/
border-bottom: 0.25pt solid #666;/*页脚处的横线*/
border-top: 0.25pt solid #666;/*页眉处的横线*/
@top-left {
content: "我是左侧的页眉内容";
vertical-align: bottom;
color: #333;
font-size: 9pt;
margin: 30pt 0 10pt 0;
}
@top-center {
content: "我是居中的页眉";
vertical-align: bottom;
color: #333;
margin: 30pt 0 10pt 0;
}
@top-right {
content: "我是右侧的页眉内容";
vertical-align: bottom;
color: #333;
font-size: 9pt;
margin: 30pt 0 10pt 0;
}
@bottom-right {/*在页面的右下角生成页码*/
content: counter(page)
" / " counter(pages);
vertical-align: top;
margin: 10pt 0 30pt 0;
color: #333;
font-size: 9pt;
}
@bottom-left {
content: "我是左侧页脚";
color: #333;
font-size: 9pt;
vertical-align: top;
margin: 10pt 0 30pt 0;
}
@bottom-center {
content: "我是居中的页脚";
color: #333;
font-size: 9pt;
vertical-align: top;
margin: 10pt 0 30pt 0;
}
}
@page:first { /*设置封面*/
margin: 0pt;/*让封面的背景图占满整页*/
padding: 0pt;/*让封面的背景图占满整页*/
@top-left {/*设置首页的页眉页脚内容为空*/
content: "";
}
@top-right {/*设置首页的页眉页脚内容为空*/
content: "";
display:none;
}
@bottom-right {/*设置首页的页眉页脚内容为空*/
content:"";
}
@bottom-left {/*设置首页的页眉页脚内容为空*/
content: "";
}
}
}- 后端控制html生成pdf的代码如下
from weasyprint import HTML
# 生成pdf的文件名称,数组中的print.css是打印样式,index.css是pdf文件的样式
HTML(string='<p>这是一个测试</p>').write_pdf("test_11_22_test12.pdf", stylesheets=['pdf/print.css','pdf/index.css'])
# 将百度首页导出为pdf
HTML('http://www.baidu.com').write_pdf("baidu.pdf", stylesheets=['pdf/print.css'])- 想要在pdf中生成目录也很简单,只需要给目录设置为a链接,然后在href属性中设置相应的id就可以了,本质也就是锚点跳转
<div id="header" style="width:100%;height:80px;text-align:center;line-height:80px;background:skyblue">我是页面的头部</div>
<div class="section" style="width:100%;height:2048px;;background:red">
<a href="#header">点击我页面将返回id为header的元素所在的位置</a>
<a href="#footer">点击我页面将返回id为footer的元素所在的位置</a></div>
<div id="footer" style="width:100%;height:80px;text-align:center;line-height:80px;background:skyblue">我是页面的尾部</div>- 需要注意的是,pdf阅读器也可以读取页面中所有的标题(h1-h6),然后生成树形结构图,也具有目录的作用。但是通常一个页面只有一个h1标签,如果不想要h1作为目录,可以在css中设置
h1{
bookmark-level:none;
}关于bookmark,这是css中的书签,网上的资料不多,感兴趣的小伙伴可以参考点击查看详情
好了,以上内容如果理解了,就可以顺利生成pdf了,下面来看看如何点击按钮进行下载,先上代码
var opt = {
type: 'HEAD',//设置请求方式
url:'/api/html_pdf?format=json',//请求路径
headers:{'Authorization':token},
data:{work_name:work_name,flag:flag},
complete:function(xhr, data) {
var dis = xhr.getResponseHeader("Content-Disposition")
download(dis)
}
}
$('.downPdf').bind('click',function(){
$.ajax(opt);
})
function getFileName(headers) { //获取responseHeaders中的文件名称
return headers.replace('attachment;filename=', '');
}
function download(res) {
var a = document.createElement('a'); //创建一个a链接
var filename = getFileName(res); //pdf文件的名称
var url = '/media/down_pdf/' + filename; //服务器中的pdf文件存储位置
a.href = url; //将文件地址付给a链接
a.setAttribute('download','report.pdf');//设置a链接的download属性,并命名下载的pdf文件为report.pdf
a.click(); //触发a链接的下载动作
}看看后端是如何返回数据的
服务端向浏览器发送文件时,如果是浏览器支持的文件类型,一般会默认被浏览器打开,比如txt、jpg、视频以及音频等,但如果需要提示用户保存,就要利用 Content-Disposition 进行处理:
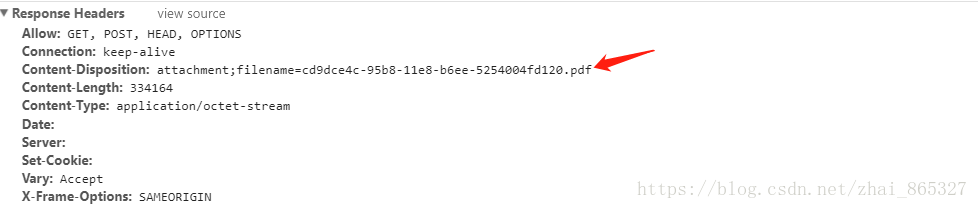
Response.AppendHeader("Content-Disposition","attachment;filename=FileName.pdf");- Content-disposition 是 MIME 协议的扩展,MIME 协议指示 MIME 用户代理如何显示附加文件。所以Content-disposition可以控制用户请求所得的内容直接在浏览器上显示还是在访问时弹出文件下载对话框进行下载。
- 上面的代码是赋值语句,类似ResponseHeaders.contentDisposition = “Content-Disposition” “:” disposition-type *( “;” disposition-parm )
- Content-Disposition为属性名
disposition-type是以什么方式下载,如attachment为以附件方式下载
disposition-parm为保存时的默认文件名 - 小伙伴可能注意到还有个字段与平时的请求不同,就是Content-Type 这个字段。它相当于告诉浏览器后台返回的数据类型是哪种类型:
Response.AppendHeader("Content-Type","application/actet-stream");- actet-stream指定类型为未知类型,或者后端也可以指定为pdf类型
Response.AppendHeader("Content-Type","application/pdf");- 我们还要通过这个接口导出html页面,因此指定为未知类型