面试题1:描述一下Spark 在yarn上的工作原理?
答:
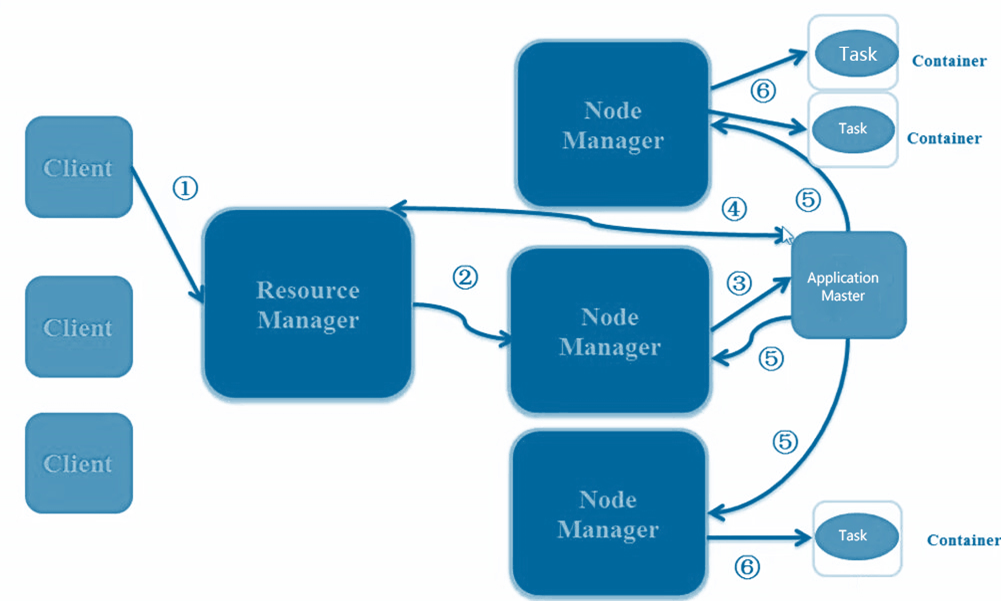
客户端要提交一个yarn的作业,首先要通过Resource manager去分配一个container给node mananger,用来跑application master,然后application master到resource manager申请所需要的资源,ApplicationMaster通知NodeManager在获得的Container中启动excutor进程,在container里面启动executor,executor返回相应的运行状态。如果是map-reduce,task换成map task和reduce task,若果是spark换成spark作业就好,所以很多作业都能跑到yarn上面的。
面试题2:说一下Spark-client和Spark-cluster的区别?
答: 广义上来说就是Cluster模式适用于生产,Client适用于调试模式。
底层来说:
(1)Client的Driver进程就运行在Client模式之上,application master仅仅向yarn请求executor,client会和请求的容器通信来调度他们的工作,也就是client 不能离开。Cluster模式的Driver负责向yarn申请资源,并监督作业的运行情况,当用户运行之后可以关闭client,作业仍然会运行在yarn上面。,客户端是可以关闭的。
(2)总结来说就是Driver的位置不一样和Application master的工作不一样。
面试题3:简述Spark中transformation和action的区别?
答:
(1)定义上区别
transformation:transformation是得到一个新的RDD,方式很多,比如从数据源生成一个新的RDD,从RDD生成一个新的RDD。
action:action是得到一个值,或者一个结果(直接将RDDcache到内存中)
(2)底层执行的区别
transformation:它的执行采用的是懒策略,就是一不触发action他是不会执行的。
action:它是直接触发执行的。