题记:
整理【NLP篇】,主要为记录工作中使用到的NLP相关的东西。第一篇,总体的概括,主要针对词向量表示,当然word2vec必不可少了。后面的章节计划从每个细节部分出发,从原理公式的推导到实际的案例(只是demo啊,可能无法在实际场景中使用)
1.NLP的基本问题
传统的NLP的处理方式基于规则,现阶段基于统计机器学习(规则隐藏在明显模型的参数里)
NLP的应用方向很广,但实际落地的产品的效果并没有像图像处理那样可以达到很高的精度。以下大方面的说主要有:
- 自动分词、句法分析、语法纠错、关键词提取;文本分类/聚类,文本自动摘要;信息检索 (ES,Solr),机器翻译,提问和回答,人机对话,考试机器人,机器写作;语言生成、语音识别,语音合成,信息抽取;知识工程、知识图谱,阅读理解,文字识别,推荐系统,情感分析
下面抽部分讨论:
-
1.分词
- 分词的应用很基础,也是分析的第一步处理。中文分词除了一些开源的NLP包外,这里推荐“遗忘算法 by:gzdmcaoyc”)。开源项目固然是方便,但是从实际的场景来看,效率上并不是很好,此外由于领域的不同,通用的方式未必是最好的。至于遗忘算法,可根据原作者的提供的思路结合公司的业务需求,写一套分词算法。
-
2.词性标注
//TODO: -
3.依存句法
//TODO: -
4.自动摘要
自动摘要技术,目前主要有2种,一种是抽取式(extractive),另一种是生成式(abstractive),前者抽取关键词拼成句子,常用的有textRank,后者使用深度学习技术,理解并生成。前者过于呆板,后者有待继续深入研究。
参见(by:灬莫伊灬):https://blog.csdn.net/lu839684437/article/details/71600410 -
5.文本分类
文本分类算法很多,传统机器学习朴素贝叶斯/SVM等,深度学习有CNN等。…
2.词向量表示方式
-
1.索引下标
-
2.Bag of words
-
3.one-hot
-
4.词权重
最简单版本是binary weighting (权衡短文本相似度) -
5.语言模型n-gram
-
6.Cocurrence matrix
同现矩阵的方式是把一句话横纵方向排列后,两两组合后看文本中是否有,累计即可。缺点是,维度不可控。存储需要空间很大。
在处理文本分类时,会出现很多地方为0。太稀疏了。
其应用方向为,发现主题,用于主题模型,如:LSA
针对稀疏问题,直接想到的办法就是SVD对其进行降维。至于SVD,这里不做过多的介绍,numpy里有实现。 -
7.NNLM
一句话 (词组合) 出现的概率:
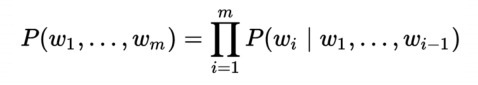
说明:窗口长度为n-1;滑动窗口遍历整个预料库求和,计算量随着预料库增大而变大;所有文字的概率和为1。
神经网络语言模型结构(目的就是用前n-1个词预测第n个词):
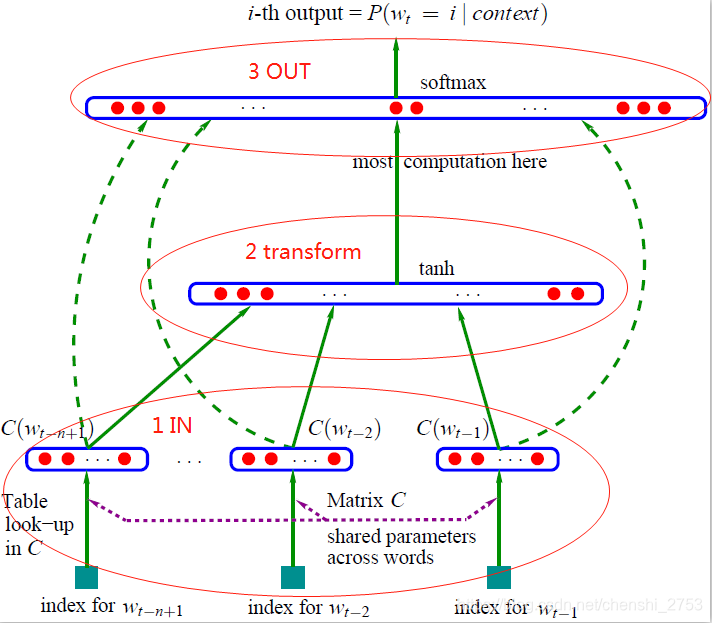
解释:1部分为投影层输入,会把每个词做index作为稀疏的向量表示(one-hot),作为输入,传入到transform中,进行单隐层的激励。最后是结果归一化后取出 最大的,既softmax的输出。
备:1部分输入是计算出来的,有index * vec = vec(IN)
各层权重最优化:BP+SGD
NNLM的计算量是其比较大的限制。
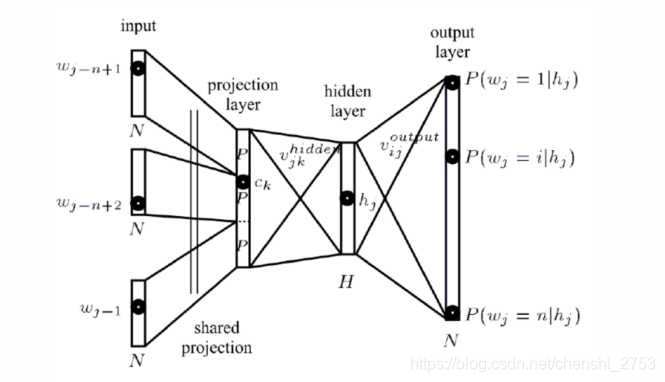
每个训练样本的计算复杂度:N * D + N * D * H + H * V
(比较重量级的模型,实际上,轻量级+大量数据 > 重量级 + 少量数据)
- 8.word2vec
- CBOW
第一种编码方式:层次softmax
较NNLM,它去除了隐层,使用了双向的上下文窗口,输入层使用的是低纬的稠密向量表示。NNLM的投影层直接简化为求和/平均。
整体结构如下图所示:
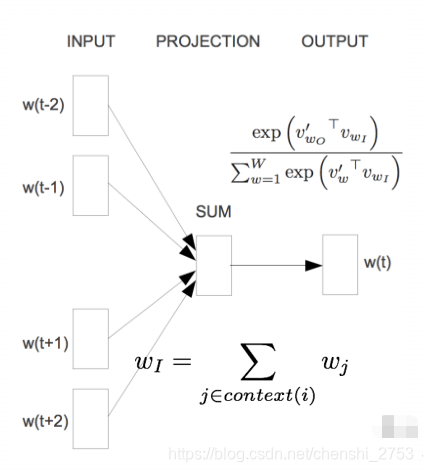
说明:输入为低维向量,经过sum中间层的处理,最后一层为层次softmax。所谓层次softmax和softmax的区别就是:多个二分类与多分类
而实现层次softmax的方式是采用Huffman编码。Huffman树是二叉树,类似二分类,把原来的一排的多叉树拉深成多个二叉树了。
如下图所示:
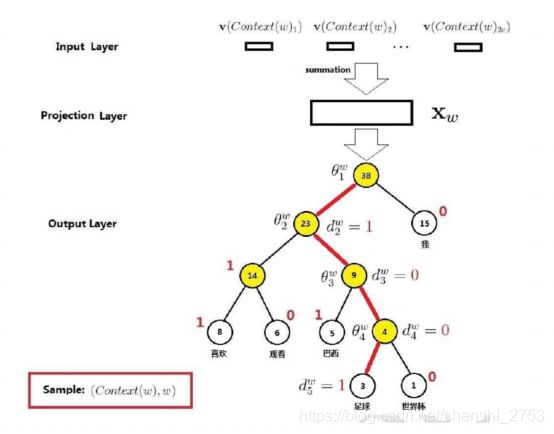
具体的实现方式及公式可大致描述为:
最终目标:求带θ的表达式的最大值,表示最大的概率选出结果。
优化:沿着梯度的方向做优化。
直观的理解:上图要找到足球这个叶节点。首先从大量的语料丢进去,看最后落在足球节点时边的权重是共享的,下次直接用。如果走左边就是p,右边则是1-p。以此类推,最后得到路径上的表达式。去求最优解。
优点:计算量降为树的深度 V => log_2(V)
公式:

第二种方式:负例采样
一个正样本,n-1个负样本。对负样本进行采样。目的是减少运算量。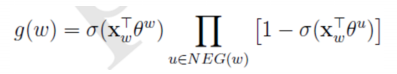
参数说明:
1.Xw是context(w)中词向量的和
2.θw是词u对应的一个(辅助)向量
3.NEG(w)是w的负样本采样子集
损失函数:对语料库中所有词w求和

负例 采样的采样过程:
词典里的所有的词组成一个[0,1]之间分割的所有的线段。
会根据词频对线段的长度划分。
- Skip-Gram模型:
首先看图,和CBOW是反过来的。相对于NNLM,无隐层,投影层亦可省。
概率密度由Softmax给出

备:word2vec的一个改进是sense2vec可处理一词多义的问题,使用词性标注的方式即可实现。(用Spacy和word2vec结合,完成sense2vec
https://github.com/explosion/sense2vec)
3.不同方式的比较
目前用的最舒服的应该归word2vec了。其他的有的过于死板,受算力的限制等。
4.相关库的推荐
-
1.word2vec工具
google开源的版本用起来速度会快很多。
地址:https://code.google.com/archive/p/word2vec/
如果无法翻墙。可看:https://github.com/dav/word2vec
安装步骤:
git clone https://github.com/dav/word2vec
cd word2vec/src
Make
亦可尝试:./demo-word.sh 和./demo-phrases.sh -
2.工具gensim
使用gensim中文处理的案例,
by:HXY
https://www.zybuluo.com/hanxiaoyang/note/472184 -
Word2vec+CNN做文本分类
论文详见《Convolutional Neural Networks for Sentence Classification》
http://arxiv.org/abs/1408.5882
Theano完成的代码版本:
https://github.com/yoonkim/CNN_sentence
TensorFlow改写的代码版本:
https://github.com/dennybritz/cnn-text-classification-tf