1.前言
在过去计算机处理词义采用分类资源处理词义,比如wordNet,它告诉这一类东西的上位词,比如熊猫的上位词是哺乳动物。但是这类分类关系的层面上会遗漏大量细微差别,因此很难获得更多价值。几乎所有的NLP研究(除了现代深度学习以及NLP神经网络),所有的NLP都采用了原子符号来表示单词,从神经网络角度考虑,使用原子符号就是使用独热编码(one-hot),但是因为独热编码中一个位置为1,其余为0,这样的话他没有给出任何词汇之间的内在关系(两个向量的点积表相似度,但独热编码的点积为0),因此我们得不到相近词汇或短语。因此因为它们是基于符号表示的, 所以就不能得出词汇和模型之间的关联,每个词汇都是独立存在而已。
NLP idea:分布相似性(distributional similarity) : 通过观察大量某个词出现的上下文得出大量表示这个词汇含义的值。 分布相似性是一种关于词汇语义的理论。
两个重要词汇的含义:
distributed:通过distributional similarity来构建。
2.Word2vec
2.1 通用
通用方法是定义一个模型,利用概率方法计算中心词汇的上下文单词出现概率,用损失函数代表预测准确性,并最小化损失函数。
2.2 word2vec介绍
word2vec:如果我们只想要得到好的单词表示,甚至都不需要构建一个可以预测的概率语言模型,我们只需要找到一种学习单词表示的方法,这就是word2vec模型。
word2vec模型的核心是构建一个很简单的可扩展、快速训练的模型。可以处理数十亿单词的本文,生成单词表示。
word2vec尝试做的最基本的是就是利用语言的意义理论才预测每个单词和他上下文词汇。
word2vec是一个软件,有俩个生成词向量的算法和两套效率中等的训练方法
2.3 skip-gram方法(包含了word2vec算法的基本概念)
思想:在每一个估算步都取一个词汇作为中心词汇。对于一个词汇只有一个概率分布(就是不区分这个词汇的左侧概率分布和右侧概率分布)。
m是距离中心词汇的长度,及计算中心词汇前m个以及后m个窗口大小的单词。
J`是损失函数或目标函数或代价函数(这门课里是一个意思)。
θ是参数,是词汇向量的表示。
J等号右边的-1/T仅仅是做归一化处理,让数小一点,J的出现就是为了让运算简单,加负号是因为习惯求最小化。

如何利用单词向量最小化负的对数似然函数:根据由单词向量构造而成的中心词汇来得出其上下文单词的概率分布。概率分布形式如下:

图示:
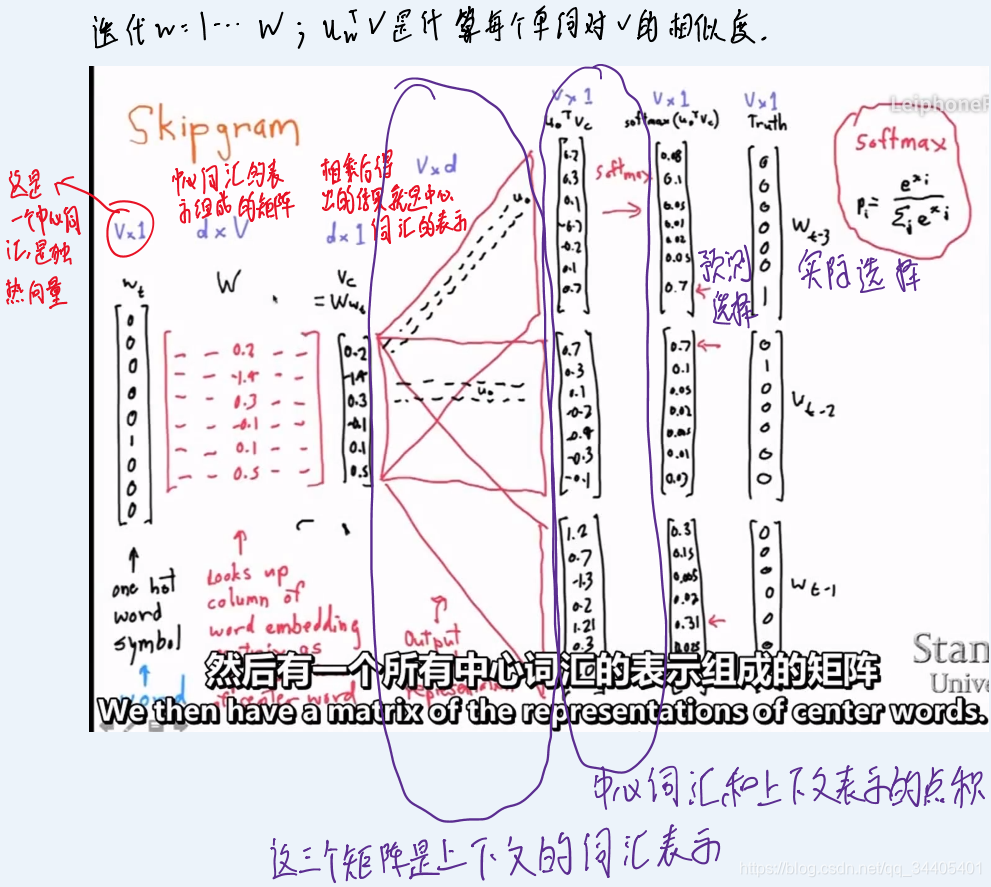
怎样最小化损失/代价/目标函数手推:

通过什么方式让目标函数一步步最优??
梯度下降法!

