一、离散表示
1、词离散表示:One-hot 表示
语料库:
李杏 喜欢 喝 奶茶
诗雅 也 喜欢 喝 奶茶
李杏 同样 喜欢 喝 果汁
词典:
{“李杏”:1,”喜欢”:2,”喝”:3,”奶茶”:4,”诗雅”:5,”也”:6,”同样”:7,”果汁”:8}
One-hot 表示:
李杏:[1,0,0,0,0,0,0,0]
喜欢:[0,1,0,0,0,0,0,0]
…
果汁:[0,0,0,0,0,0,0,1]
注意:
词典包含8个单词,每个单词有唯一索引
在词典中的顺序和在句子中的顺序没有关联
2、句子离散表示:Bag of Words
1)文档的向量表示可以直接将各词的词向量表示加和
李杏 喜欢 喝 奶茶 →[1,1,1,1,0,0,0,0]
诗雅 也 喜欢 喝 奶茶→[0,1,1,1,1,1,0,0]
李杏 同样 喜欢 喝 果汁→[1,1,1,0,0,0,1,1]
from IPython.display import Image
Image(filename=r"C:\Users\Administrator.DESKTOP-36E16C6\Desktop\课程\结果截图\tfidf.png")2)TF-IDF (Term Frequency-Inverse Document Frequency)
文档总数n=3
含某关键词w的文档数df(w)
idf=log(1+n)/(1+df(w))+1
| 词 | df(w) | idf |
|---|---|---|
| 李杏 | 2 | log(1+3)/(1+2)+1 |
| 喜欢 | 3 | log(1+3)/(1+3)+1 |
| 喝 | 3 | log(1+3)/(1+3)+1 |
| 奶茶 | 2 | log(1+3)/(1+2)+1 |
| 诗雅 | 1 | log(1+3)/(1+1)+1 |
| 也 | 1 | log(1+3)/(1+1)+1 |
bag of words的缺点:丢失了词语在句子中的前后顺序信息。
3、离散表示的问题
无法衡量词向量之间的关系
太稀疏,很难捕捉文本的含义
词表维度随着语料库增长膨胀
二、定义人启发→定义词启发
人类定义 :
在我们一群人种区分出诗雅和李杏:
| 人名 | 是否是男生 | 是否是长头发 | 是否喜欢喝奶茶 | 是否戴眼镜 |
|---|---|---|---|---|
| 诗雅 | 0 | 0 | 1 | 1 |
| 李杏 | 0 | 1 | 1 | 0 |
诗雅-李杏→是否长头发、是否戴眼镜的区别
↑随着词库的增加,人为定义特征难度增大,准确度下降。
那某个词是否可以由其上下文来表示该词呢?即如果两个词的上下文相似,那么这两个词也是相似的↓
三、分布式表示(Distributed representation)
Distributional Representation是从分布式假设(即如果两个词的上下文相似,那么这两个词也是相似的)的角度, 利用共生矩阵来获取词的语义表示,可以看成是一类获取词表示的方法
一段文本的语义分散在一个低维空间的不同维度上,相当于将不同的文本分散到空间中不用的区域。
bag of word→(上下文表示)→N-gram→(降维)→NNLM(RNNLM)→(减少模型复杂度)→word2vec
NNLM
NNLM(Neural Network Language model)
直接从语言模型出发,将模型最优化过程转化为求词向量表示的过程。
要点
根据**前 n-1** 个单词,预测第t个位置单词的概率。
使用了非对称的前向窗函数,窗长度为 n-1
滑动窗口遍历整个语料库求和,计算量正比于语料库大小
概率P满足归一化条件,这样不同位置t处的概率才能相加,即
word2vec
要点
1)学习一个从高维稀疏离散向量到低维稠密连续向量的映射。
2)该映射的特点是,近义词向量的欧氏距离比较小,词向量之间的加减法有实际物理意义。
3)Word2Vec由两部分组成:CBoW和Skip-Gram。
4)CBoW的结构很简单,在NNLM的基础上去掉隐层,Embedding层直接连接到Softmax,CBoW的输入是某个Word的上下文(例如前两个词和后两个词),
Softmax的输出是关于当前词的某个概率,即CBoW是从上下文到当前词的某种映射或者预测。Skip-Gram则是反过来,从当前词预测上下文,至于
为什么叫Skip-Gram这个名字,原因是在处理过程中会对词做采样。
过程:
输入上下文单词ont-hot→“随机压缩成n维”→求和,求平均→w词向量
下面使用一个类似word2vec的构思的例子,注意不是word2vec原理阐述
语料:
李杏 喜欢 喝 奶茶
诗雅 喜欢 喝 果汁
窗口:
取前三个词
简易版计算:
w=奶茶
w的前三个词: 李杏、喜欢、喝
李杏:[1,0,0,0,0,0,0,0]
喜欢:[0,1,0,0,0,0,0,0]
喝:[0,0,1,0,0,0,0,0]
w的表示为: 李杏、喜欢、喝这三个词的的向量相加,即:
[1,1,1,0,0,0,0]
w=果汁
w的前三个词: 诗雅、喜欢、喝
诗雅:[0,0,0,0,1,0,0,0]
喜欢:[0,1,0,0,0,0,0,0]
喝:[0,0,1,0,0,0,0,0]
w的表示为: 诗雅、喜欢、喝这三个词的的向量相加,即:
[0,1,1,0,1,0,0,0]
结论:
由上可得:果汁和奶茶的相似度较高,即即如果两个词的上下文相似,那么这两个词也是相似的
word2vec学习过程举例:
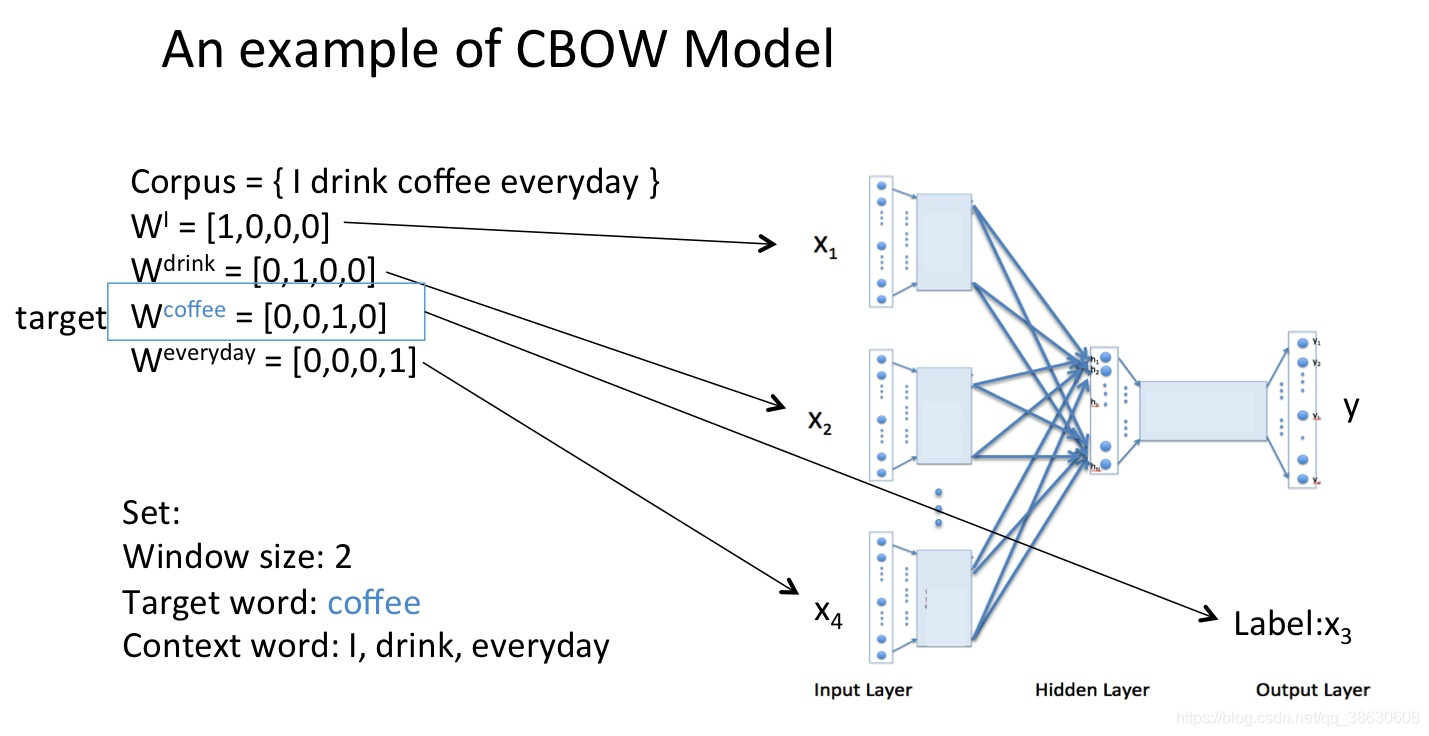
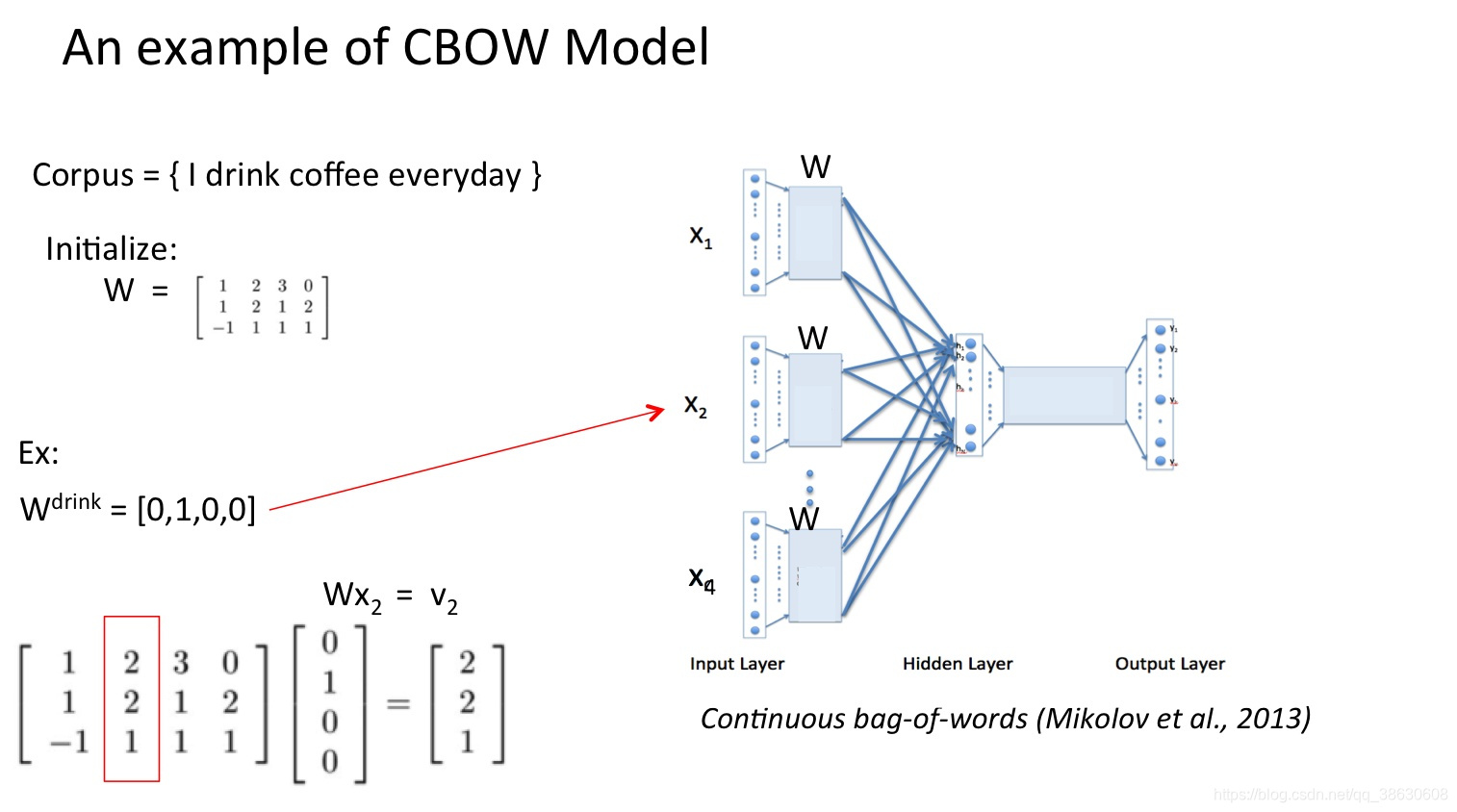
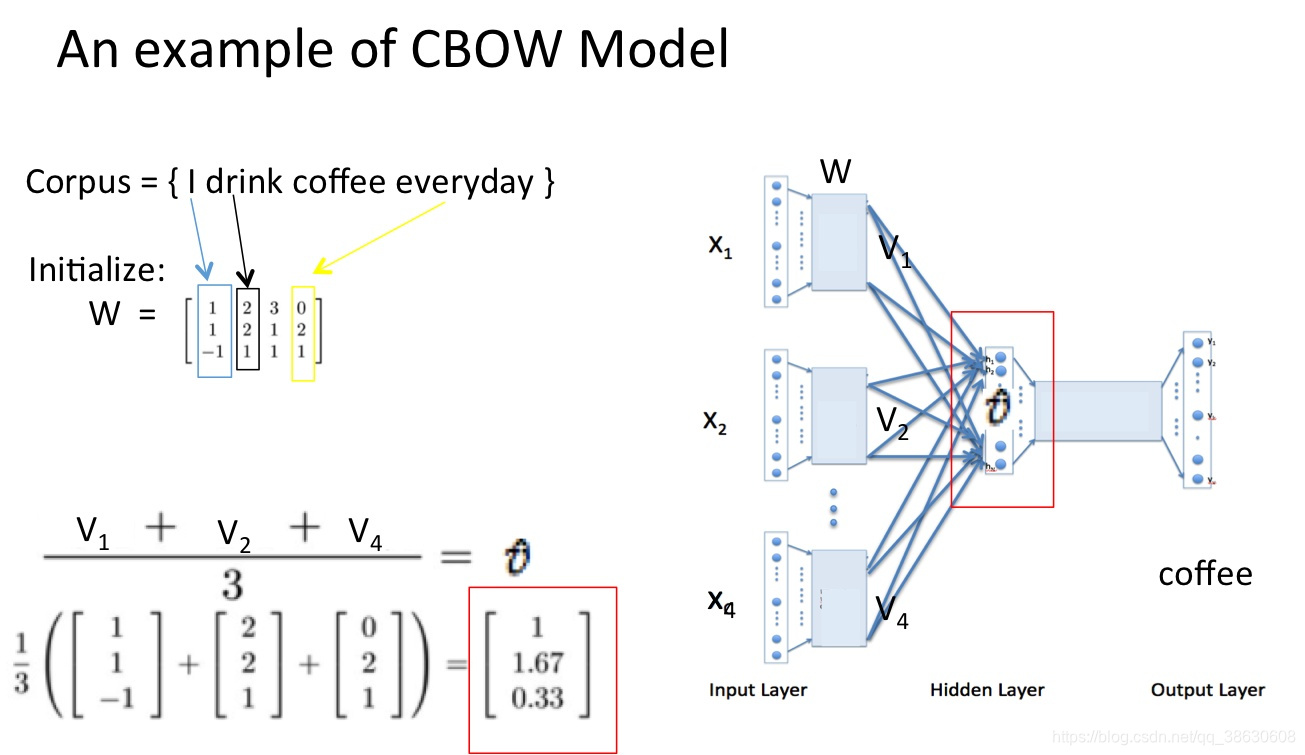
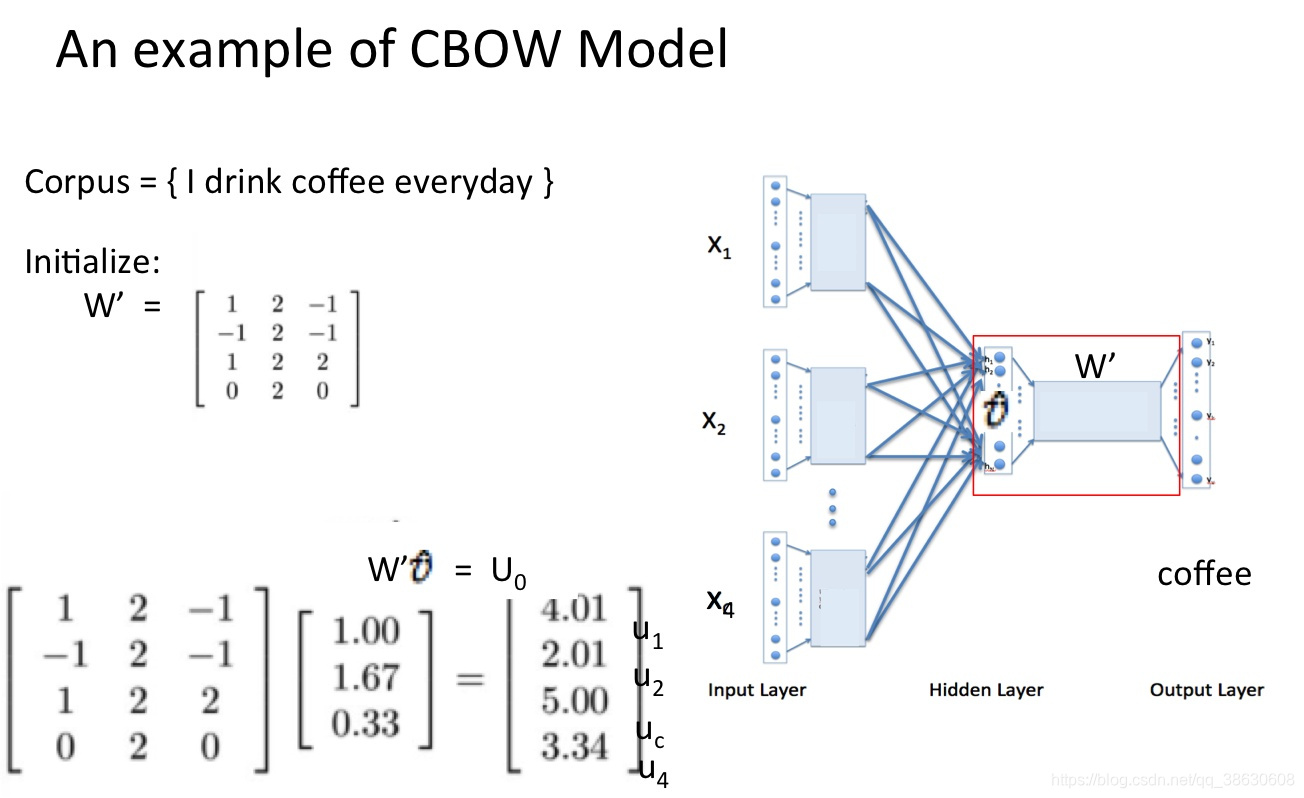

CBOW(连续词袋)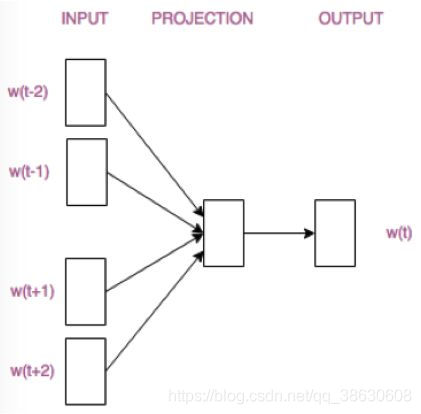
Skip-Gram模型