In summary, word embeddings are a representation of the *semantics* of a word, efficiently encoding semantic information that might be relevant to the task at hand.
1. word embedding在干什么?
word embedding 主要解决怎么把词传递给计算机的问题。
把词的字母的ASCAII码做输入?
用one-hot编码输入?
都不行,不仅因为这样会把数据变得很大,更重要的是这样完全舍弃了词之间的联系。例如:数学家,物理学家,他们都是一种身份,而且通常做主语。
word embedding就是解决这个问题
“It is a technique to combat the sparsity of linguistic data, by connecting the dots between what we have seen and what we haven’t. This example of course relies on a fundamental linguistic assumption: that words appearing in similar contexts are related to each other semantically. This is called the distributional hypothesis.”
把词转换成一个个向量,并且这个向量要满足一定的条件:
相似的词对应的向量也要相似
2. word embedding怎么实现的?
以数学家和物理学家为例,他们有一定的相似性。比如我们看三条性质:可以跑,喜欢咖啡,主修物理。然后每个性质给一定的值,像下面的图:

他们在可以跑,喜欢咖啡,数值接近,但是主修物理差异大。
那如果我们定义两个词的相似度为: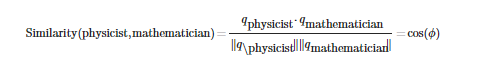
这个值如果两个向量一样的话,值为1,如果相反,值为-1.
可是,除了这三条性质,我们还可以想到很多条其他性质来描述一个词,那这些性质到底赋值多少呢?
让人去给每个词每个性质打分是很难的。于是求助于深度学习。
我们用深度学习模型的权重来代替人的打分。
这个权重在深度学习模型训练的过程中会迭代更新。
“Central to the idea of deep learning is that the neural network learns representations of the features, rather than requiring the programmer to design them herself. So why not just let the word embeddings be parameters in our model, and then be updated during training? This is exactly what we will do. We will have some latent semantic attributes that the network can, in principle, learn. Note that the word embeddings will probably not be interpretable.”