本人正在攻读计算机博士学位,目前一直再学习各种模型啊算法之类的。所以一直想把自己的学习过程总结一下,所以就开通了这个博客。
这两天一直再看语音识别方面的知识,想把自己的理解总结一下,希望对其他学习的人有所帮助。
提前需要掌握的知识:
- 语音信号基础:语音信号的表示形式、分帧、特征(MFCC)、音素等等
- HMM模型:离散隐马尔科夫模型级3个问题的求解方法
- GMM:混合高斯模型,用于连续隐马尔科夫模型。
语音数据处理
语音信号计算机中是采用PCM编码按时间序列保存的一连串数据。计算机中最原始语音文件是wav,可以通过各种录音软件录制,录制是包括三个参数
- fs:采样率 8000Hz 115200Hz 等等,代表每1秒保存的语音数据点数
- bits:每个采样点用几个二进制保存
- 通道:很多音频都有左右2个通道,在语音识别中通常有一个通道的数据就够了。
下面是一个 apple.wav 文件在matlab中的例子:
[x fs bit]=wavread('apple.wave');
plot(x);
--------------
fs =8000
bits =16
--------------x读取到的声音文件数据,长度是2694个采样点数据,其中wavread已经把每个采样点的16bit二进制转换成了-1~+1之间的实数了。所以声音对于我们出来来说就是一个一位数组了。
刚才的apple.wave这个声音时间才是0.33675秒长语音,但数据量还是巨大的。所以语音信号做各种处理时不是把整个x去做运算,而是把他分割固定的一小段一小段的样子,叫做帧。帧应该多长呢?通常用20ms作为一个帧长。那20ms中包括多少个采样点呢,这个和采样速率fs有关。T=1/fs是采样间隔,那么一帧的数据长度 N=帧时间长度/T=帧时间长度(单位秒)*fs(单位Hz)
上例子中 N=(20ms/1000)*8000=160
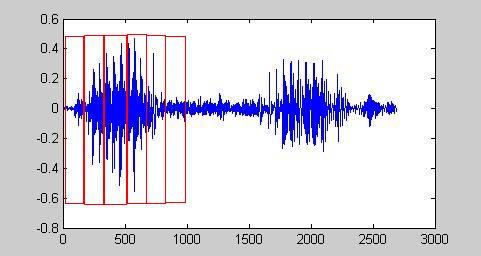
分帧后的效果
上图中帧和帧是挨着的,实际中通常让他们有一定的重贴,这样帧序列可以更好的反应语音信号特点。
接下来语音信号处理都是针对每个帧来处理了,而且帧长是固定,这样处理起来比较方面的 。上例子可以一帧数据包括160个点,
Fs = 8000;
framesize = 80;%真长
overlap = 20;%帧课重叠部分长度
frames = enframe(x, hamming(framesize), overlap);
>> size(frames)
131 80这样刚才的语音就分成了131个帧了,每帧包含80数据。
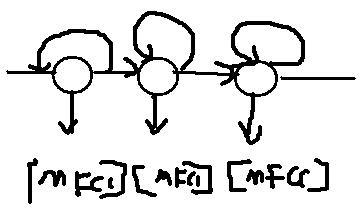
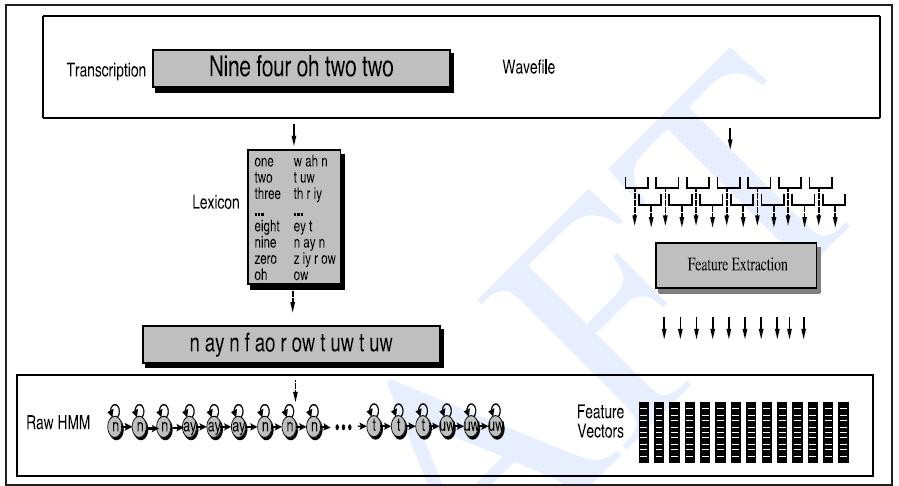
80个数据点对于我们来说也比较多的,能不能再进一步减少呢?当然可以这就是特征提取了。现在语音识别中常用的特征是MFCC(可以参照:http://blog.csdn.net/xiaoding133/article/details/8106672)。我们需要知道80个数据点最后提取了多长的特征呢?答案是12个点。
这样语音数据就被进一步缩小了变成131个帧,每帧12点数据了。这样有2个好处:(1)运算量降低 (2)特征比原始语音有更好的分辨能力。到此语音数据的处理部分就可以告一段落了。接下来的问题是这些语音数据和HMM模型怎么关联起来呢?
HMM模型
HMM模型的基本知识一定要读A tutorial on Hidden Markov Models and selected applications in speech recognition, L. Rabiner, 1989, Proc. IEEE 77(2):257–286. 相信我这个英文写的HMM说明比很多中文网站里写的要好懂很多。这里假设大家都懂了HMM模型是什么,我主要说一下,HMM模型怎么用到语音识别的吧。
先从最简单的少词汇量的识别情况说起。
少词汇量语音识别
假设我们要识别的词汇只有 ‘apple’ ‘banana’ ‘kiwi’ ‘lime’ ‘orange’ ‘peach’ ‘pineapple’ 这7个单词。那假设找了15个人,每人说一遍这8个单词然后录音,分别保存成apple01.wav apple02.wav等。这样就得到了每次词15个录音,总共105个wav文件。这就是原始数据。这些数据需要按前面所说分辨成MFCC特征文件。
在少词汇量识别中可以为每个词汇建立一个HMM模型。这个例子中可以建立7个HMM。HMM模型描述包括:
- 状态个数N:整数
- 转移概率A:N×N矩阵
- 初始概率π:N×1矩阵
- 观察序列概率B:N×T矩阵 T是观察符号集个数
- 观察符号:模型输出的东西,可以是数值也可以是向量
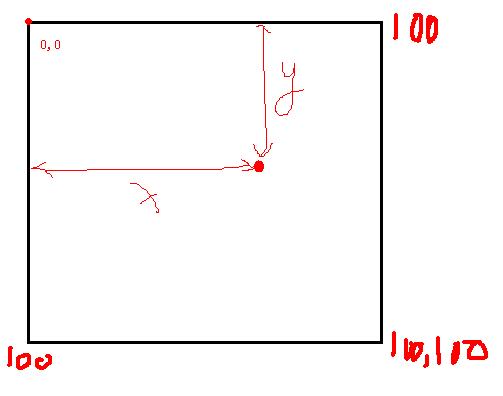
其中模型参数B有很多讲究。如果是离散HMM那么B就是个每个状态下可能产生观察符号的概率,对于连续HMM就不能用离散概率来描述输出符号了。举一个例子,论文中有掷骰子的例子,这个HMM的观察符号是离散的1、2、3、4、5、6中的一个。他们观察的情况可以用概率来描述。现在我举一个连续HMM的例子,我有2个小球,一个红色,一个绿色,他们的重量不一样。有一个盒子长度和宽度分别是100cm。最开始我随机取一个球扔进盒子里,等球最后停止运动时记录下它在盒子中的坐标(如下图所示)。然后投掷一个硬币若是正面继续使用刚才的球重复试验,否则换另一个球重复试验。
为这个过程建立一个HMM模型来描述。其中
N=2分别代表目前用的是红球还是绿球
π=[0.5 0.5] 试验开始我随机取了一个球因此取到红球或绿球的概率一样
A=[
0.8 0.2
0.2 0.8
] 假设我用的硬币质量不均匀,出正面的概率是0.8 背面是0.2
O={x,y} 把球落入盒子的坐标作为观察序列。
假设第一个试验得到的坐标是 {10.5 38.8},第二次{76.5 18.3}依此类推。现在的问题是HMM中的B矩阵怎么描述?显然我的观察序列可能出现的坐标有无穷多种(假设是实数坐标),所以离散HMM无法试用了,因为无法穷举我所有的可能的输出。那怎么办呢?可以把观察符号集可以看做是服从连续分布的二维随机变量。连续变量只能用概率密度函数去描述了,而直接说取某个值的概率是无意义的(因为都是无穷小)。我们最熟知分布有:均匀分布、高斯分布等等。那刚才的例子中观察符号的出现服从什么分布?显然我们不知道具体分布。那有没有近似的方法呢?有,那就是混合高斯模型GMM(参照http://blog.pluskid.org/?p=39)。先简化一个,假设观察序列符合高斯分布,那问题是这个假设的高斯分布的均值和方差是多少呢?只要知道这2个参数我们就知道了这个实验的观察符号的服从规律了。那我们假设是不是合理呢?通常情况下自然界很多事情都服从高斯分布,如果这例子本来就不是高斯分布这时我们无法用某个我们已知的概率分布去描述,这时可以用多个高斯分布的线性叠加来描述,这既是GMM。
接下来说一下HMM的隐含性。刚才的例子我已经告诉了N,A,π这些参数,但如果我不告诉你这些参数,而我再幕布后做了这个实验(当然我自己知道,你现在不知道)做了10000次,得到了10000个观察符号,就是观察序列O。然后我把这个O给你,你能不能把我用的N,A,π,观察符号概率分布参数 预测出来?这就是HMM的训练问题。当然这实验是我设计的,所以我是已经知道了各个参数的,你不知道。但很多自然界中的情况我们是提前不能知道参数,而只能看到输出序列,所以我们需要找到系参数让他最能符合这个输出序列(EM算法)。上面的例子如果我不知道参数,只知道观察序列,那么可以这么做,先假设系统的各个参数,然后不停的改变参数让P(O|λ)最大。其中λ={π A μ Σ} 其中{μ Σ}值假设输出时连续单高斯分布时的均值和协方差(多为输出时对应均值向量和协方差矩阵)。
说了很多,再回到语音识别的问题上。要识别7个单词,那就建立7个HMM,那第一个问题HMM的状态用几个?这个需要根据情况来定,看看状态代表什么含义。在整词建模中我们可以认为每个状态代表一个音素,比如apple(ae p l)就是有3个音素构成,那么给apple的HMM定义3个状态。banana(b ax n aa n ax)由6个音素构成,可以用6个状态HMM建模。为了简单也可以为每个词都建立相同状态数的HMM模型,这时就不能说状态精确代表是音素了,可能对应的半音素或几个音素。第二个HMM的观察序列是什么?用语音数据每一帧的MFCC数据作为一个观察符号,一个语音文件的全部MFCC就是观察序列。显然上例子中我的观察符号是2维向量,语音识别例子里就变成12维向量了,而且是连续形式的。第三个问题状态转移有什么限制?用left-right形式的HMM
这种HMM的A=[
0.2 0.8 0
0 0.2 0.8
0 0 1
] (其中数值时假设的)
这时由语音信号的特点决定的这个类型的HMM。因为如果每个状态代表一个音素,语音一般是一个音素接一个音素这样说,很少出现跳过中间音素,自循环的跳转主要对应发音时声音可能拉长或缩短对应这种情况。
第四个问题每个状态下的观察符号的概率用什么描述?假设单高斯分布(或混合高斯分布,更精确)。
这样一个这个HMM 的定义就有了 λ={N π A μ Σ}
接下来就用各自的观察序列训练各自的模型(就是找到最优的π A μ Σ的问题)。
接下来说一下识别方法。假设有了一段语音那他们到底是哪个单词的发音呢?先把语音分帧变成MFCC序列O,然后分别计算
P(O|λ_apple)
P(O|λ_banana)
P(O|λ_kiwi)
P(O|λ_lime)
P(O|λ_orange)
P(O|λ_peach)
P(O|λ_pineapple)
取最大值作为识别结果输出。这个计算时HMM的第一个问题,可以用前向后项算法计算。
致词希望我把有限词汇量的问题说清楚了,具体算法层面的细节需要仔细阅读上面给出的参考论文。
连续大词汇量语音识别
HMM模型
给每个词单独建立一个HMM的思路在连续大词汇量语音识别中显然不再试用了(词语太多了,而且连续说话时词语的发音会有不同)。那怎么办呢?使识别单元缩小,目前使用较多的是音素。
ONE w ah n
YOUNG y ah ng
这时英文单词one,young的音素,其中ah就是他们公共都有的音素了,这样音素真个语音中就比较少了。给出每个单词由哪些音素构成的叫做读音词典,想做语音识别必须先要有读音词典,英文读音词典例子。连续语音识别的基本思想是找出所有音素(数量大概有几十或几百个吧,但要比单词数量少了很多了这就是选择音素的愿意),然后为每个音素建立一个HMM,然后用各自的音素数据训练各自的HMM模型。
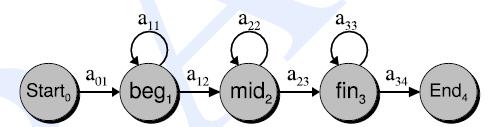
其中HMM模型和语音对应的关系和单个词时的一样,同样用每帧的MFCC特征作为HMM的观察符号(帧是最小单位,比如one这个词的发音包含3个音素,one的wav数据可以分成几百个帧,所以一个音素可以包含多个帧)HMM状态数通常用5个,其中第一个和最后一个状态没有实际意义,中间三个状态分别代表音素开始阶段、音素稳定阶段、音素结束阶段,这三个状态才发射观察序列,头和尾的状态不发射,头和尾状态其他音素连接时一般要去掉的。如下图所示一个音素模型的HMM结构:
这样就能碰另一个问题,一个发音数据中我们怎么知道每个音素从哪儿开始到哪儿结束呢?这叫做音素标注问题。现在有2种做法一种是HMM训练用已经标注的wav文件,另一种是不需要标注也能训练HMM。所谓标准一般需要人工进行,需要听声音,然后判断每个音素的边界。比如one为例0~80ms是发音“w”,81~136ms是发音”ah”,136~536ms是“n”。英文里有timit语料库,有音素标准文件。当然这个标注会非常耗费人力的工作,现在也有语音无需标准就能训练HMM的办法的叫做embedded training (嵌入式训练) ,只需给出语音文件和音素序列就可以比如 语音文件是one.wav 音素信息是“w ah n”,而不用详细给出音素分界线。
有了音素以后就可以用串联音素模型构成字的HMM模型(当然要借助发音词典)。比如英文SIX(s ih k s)由4个音素组成,每个音素又由3状态的HMM构成(连接时头和尾状态要去掉),那么整个SIX的HMM就下图所示(Sb代表第一个音素‘s’的开始阶段的状态):
同理如果有一个句子“call nine one one”,同样可以为它建立HMM模型(先用音素串联构成词,词串联构成句子)。这个句子的音素构成是“k ao l n ay n w ah n w ah n”,总共有12个音素。句子的HMM的A矩阵和B矩阵是有各个音素HMM的A矩阵和B矩阵构成的。比如音素“k”HMM定义的A矩阵如下:
A_k=[
0 1 0 0 0
0 1/2 1/2 0 0
0 0 1/2 1/2 0
0 0 0 1/2 1/2
0 0 0 0 0
]
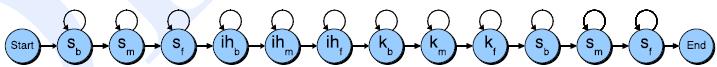
A_ao=[
0 1 0 0 0
0 1/2 1/2 0 0
0 0 1/2 1/2 0
0 0 0 1/2 1/2
0 0 0 0 0
]
A_l=[
0 1 0 0 0
0 1/2 1/2 0 0
0 0 1/2 1/2 0
0 0 0 1/2 1/2
0 0 0 0 0
]
那”call”的HMM的A矩阵就是
A_call=[
0 1 0 0 0 0 0 0 0 0 0
0 1/2 1/2 0 0 0 0 0 0 0 0
0 0 1/2 1/2 0 0 0 0 0 0 0
0 0 0 1/2 1/2 0 0 0 0 0 0
0 0 0 0 1/2 1/2 0 0 0 0 0
0 0 0 0 0 1/2 1/2 0 0 0 0
0 0 0 0 0 0 1/2 1/2 0 0 0
0 0 0 0 0 0 0 1/2 1/2 0 0
0 0 0 0 0 0 0 0 1/2 1/2 0
0 0 0 0 0 0 0 0 0 1/2 1/2
0 0 0 0 0 0 0 0 0 0 0
]
句子以此类推。A矩阵中和多地方都是0,代表不可能的状态转移。句子中的B矩阵和音素的B矩阵一样,但一个句子音素可能出现多次,因此B矩阵是可以共享的。
Embedded Training
我们的目的是训练各个音素的HMM模型参数,用这个HMM模型去代表语音的音素。最简单的训练方式是我们有很多音素对应的观察序列,然后用Baum-Welch算法(EM算法的一个实现方式)去训练A、B矩阵。但前面说过我们很难从一个句子或词语的发音中精确的找到音素、甚至是伴音素的边界。为了解决这个苦难一般采用embedded training的方式。embedded training需要的数据包括:
①训练用的句子的文本文件、例子: call nine one one !
②读音词典。例子:
CALL k ao l
NINE n ay n
ONE w ah n
③语音文件。sen01.wav sen02.wav
④音素列表级音素原始HMM定义
embedded training的基本思路是:读取一个句子的文本、把文本表示的一个句子转成用音素表示的句子(利用读音词典)、利用原始音素HMM定义串联起来构成句子的HMM定义(可能是非常长的HMM了)。然后把一个句子的wav文件转换成帧、提取特征,变成长的特征序列。然后把整个句子的特征序列看做是句子HMM模型的观察序列,直接却训练长的句子HMM模型(这时和普通的HMM模型一样用Baum-Welch算法)。句子训练好以后实际上各个音素也训练好了(因为句子的A、B矩阵就由音素的A、B矩阵构成)。看下图:
算法步骤如下:
1.为每个训练句子建立整句HMM模型
2.初始化整句HMM模型的A矩阵,其中开始和结束状态外,每个状态只能到自己或下一个状态,概率分别是0.5
3.所有状态的B矩阵(一般用混合高斯模型)用全部训练样本的均值和方差初始化高斯模型的均值和方差
4.多次执行Baum-Welch算法。
语音解码
如上所属如果所有音素的HMM都训练好了,那么现在来了一个声音文件、怎么转换成文本呢?这就是语音解码问题。“给定一个音素模型的观察序列,和他对应的概率最大的文字序列是什么?”这就是解码问题。
观察序列 O=o1,o2,o3,...,ot,
文本序列 W=w1,w2,w3,...,wt,
识别就是在给定观察序列(代表的是声音信息)下,在所有的文字序列集合中哪个的概率最高的问题。把概率最高的文字序列看做是语音识别的结果。计算P(W|O)的难度比较大,所以这里通过贝叶斯公式进行转换如下:
其中P(W)是文字先验概率(N-gram模型可以描述),P(O|W)是已知文字下获得观察序列O的概率叫做声学模型(HMM模型可以描述)。P(O)在分母上,对所有的W都是一样的所以可以忽略不用计算。那就变成:
这两项概率一般需要做一些权重的修正,实际中经常使用:
第二个公式取对数后的形式(计算一般用对数概率),其中LMSF是语言模型的放大倍数同行取5~15之间的数,N:文字长度,WIP是常数叫做word insertion penalty
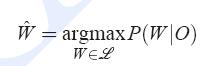
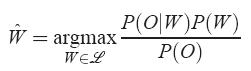
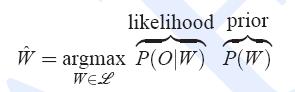
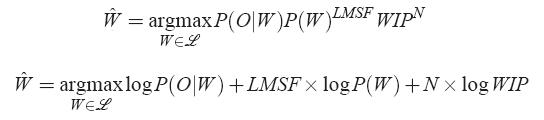
连续语音识别中解码的难点:
- 连续语音中词与词的边界是不知道的
- 给出一段语音信号,其中包含的额文字个数是未知的
- 搜索全部可能性是很难的,比如总共有M个词,语音长度是V个帧,全部组合是Mv这么多可能性,无法全部遍历。
解码的基本思路:
用训练好的音素模型为每个字构建HMM模型(字个数应该包含目标语种中全部或常用的字)。其中字与字之间的关系用语言模型来描述(N-gram)。字和发音序列之间的关系用HMM模型来描述。利用这两部分信息构建一个庞大的网状结构(具体实现形式可以有很多种)叫做搜索空间,然后在这个上运行搜索算法(有Viterbi算法、Viterbi with Beam-Pruning、Token传递算法等等)获得最优可能的文字序列作为识别结果。
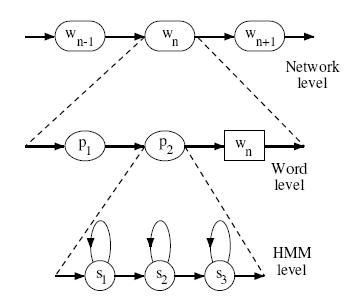
其中搜索空间可以看成是三层结构:网络层、字层、HMM层。如图所示:
对未知的语音序列,假设有T个帧构成。从识别网络所有可能入口开始经过T个HMM发射状态都叫做一个识别路径。每个路径都可以计算一个对数概率值。每个路径可能包含 音素HMM状态之间的转移、音素边界之间的转移和字边界之间的转移三部分。HMM内部概率可以由HMM模型计算、音素边界可以用固定概率、字边界转移概率可以用语言模型的N-gram概率提前获得。
Token Passing Algorithm
每个Token代表识别网络中的一个路径,内部存储该条路径的概率和回溯信息。t=0时刻,每个可能的开始节点(对应于音素HMM的状态)生成一个token。每经过1帧(t=t+1)token向所有可能的下一个节点传播(当前节点和多个节点有连接时token复制)。每次转播到发射节点(音素边界、字边界也看做是节点但不发射观察序列)时暂停,然后token里记录的对数概率增加(参考转移概率A和观察序列矩阵B),然后再传播。可以规定每个节点最多同时保持N个token(最简单情况N=1,保留多个token中概率最高的一个进行传播,或者采取一些剪枝策略(purning))。其中token穿过字边界时可以把N-gram模型的概率加入到token的对数概率里,这样就综合考虑和音素模型和语言模型了。同时穿过字边界时需要记录路径,最后结束时用回溯列出识别文字(从这一点上看识别网络中不存的字肯定是无法识别的了)。
三音素模型
所有上述内容都用单音素模型了,实际中通常使用三音素模型(Triphone)。需要考虑上下音素的协同发音情况。例子:
单音素:BRYAN → B R AY AX N
三音素:BRYAN → SIL-B+R B-R+AY R-AY+AX AY-AX+N AX-N+SIL
其中“-”代表当前音素,“+”代表后续音素,“-”号前的代表前面的音素。三音素的好处就是音素级别建模更精确了,不如本来有50个音素,单因素只需要训练50个HMM,三音素就出现503=12500个HMM需要训练了。参数就会变得巨大,相比训练数据就会稀疏很多了。解决方案就是:三音素合并、状态共享等。并不是所有的三音素都合法、其次有些三音素很接近利用一些聚类的方式可以合并三音素减少模型数量。其次观察矩阵B对于很多音素出现再不同的三音素里可能是差不多的,这时就可以共享同一个B矩阵了(详细省略)。
至此原理部分基本讲完了,希望大家能看懂
主要用的资料有:
HMM基础论http://www.cs.ubc.ca/~murphyk/Software/HMM/rabiner.pdf
HTK说明文档 htkbook.pdf (网上可下载)
书【Speech and Language Processing】Daniel Jurafsky & James H. Martin 提取码:ceye
本文中有些图是摘自上述资料。
全部结束感谢大家的阅读!