看了几天了,结合之前看kaldi里的训练,现在我觉得可以稍微清楚的解释这个训练过程,后面的时间赶紧看解码部分。希望你可以有所收获。
这次我们从头开始,虽然mfcc特征大家都知道,但是为了完整性还是说下吧。希望这是最后一次写训练的过程。
1.数据准备我就不说了,直接说提特征,一般来说提mfcc特征。当然在gmm-hmm中一般都是mfcc特征。mfcc特征的具体流程,这里贴一张图,大家可以参考。htk或者kaldi里都有提特征的脚本,也有源码,相信这个应该都不算难事了。
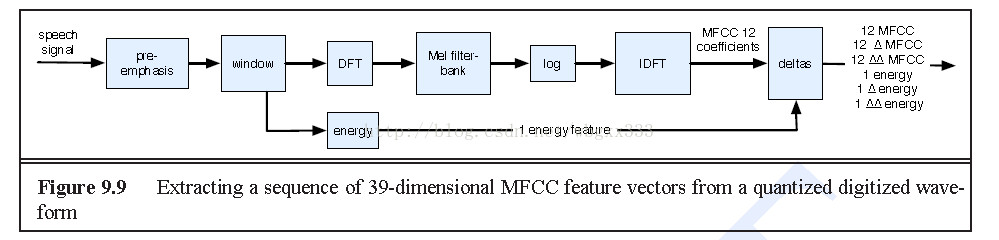
这个过程也比较清楚,这里就不多说了。
2.这里的特征提完了,接下里就是训练的事情。这里先做初始化的步骤,第一个初始化就是高斯模型的均值和方差,这里我们就用整个训练数据集的均值和方差来代替。注意这里应该是单高斯模型,用单高斯模型对每一帧数据进行建模,记住是每一帧(这里可能有错,也许是利用某个状态的观察变量来建立一个高斯)。还有一个初始化就是隐马尔科夫的参数,一般对音素用三个状态,这里除了开始和结束的三个。静音用5个状态。下图是一个音素的例子:
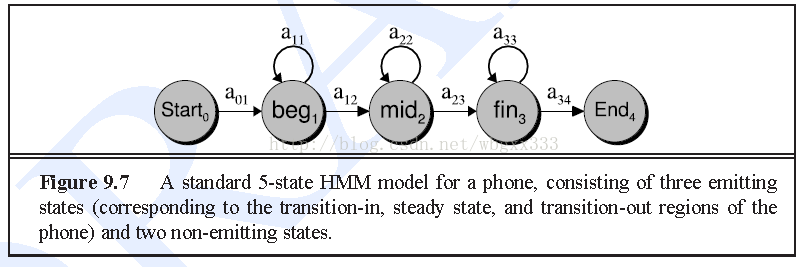
这个hmm的参数可以参考htk或者kaldi里的topo文件。这样,初始化已经完成。
此外,在嵌入式训练里有说到为每个训练的句子建立一个完整的hmm结构(@decoder修正:这个一句话我们事先是知道有多少个hmm的,所以我们事先时候是知道整个句子的hmm结构)。在kaldi里也有函数做了,函数就是compile-train-graph。当然我的理解这个是为了后来的对齐做准备。这里可以根据标注来为整个句子做个对齐,当然这个是kaldi里做的,至于原理里似乎没说。然后就开始用viterbi训练,这里没有用前向后向算法,具体的原因在嵌入式训练中提到了。kaldi也是这么去做的。然后我们需要做最大似然比的更新,kaldi里做了将近40次的更新。这样,单音素模型也就建立好了,第一步也就基本完成了。
3.上下文相关的三音素模型,这里为什么用三音素也很明显,因为它考虑了上下文的音素,使得效果更更加的好。这里我们首先做的就是复制每个单音素模型。具体的就是下图这个过程:
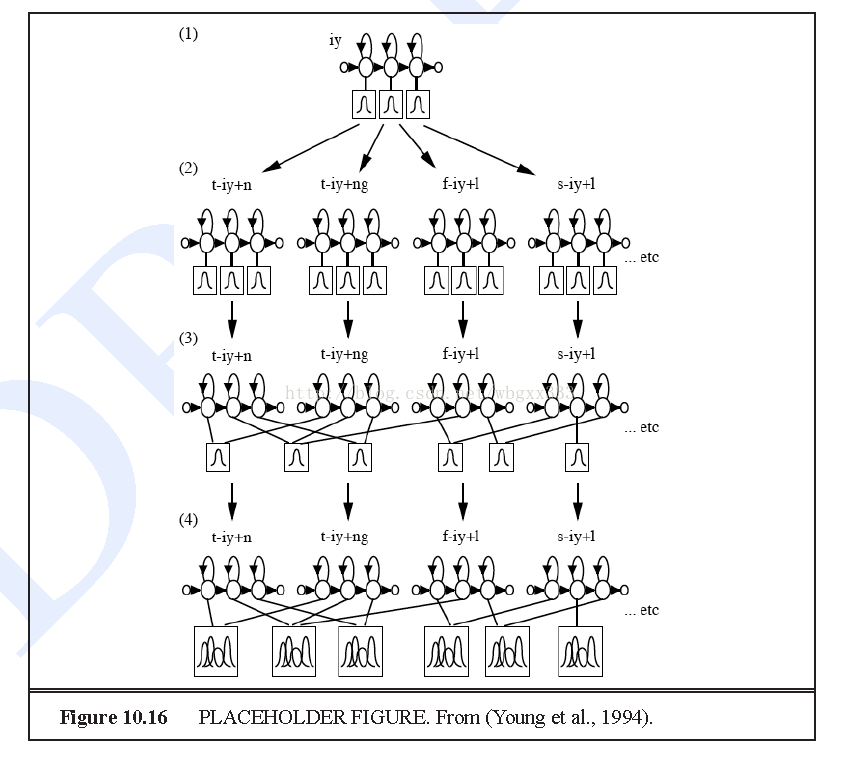
文字叙述就是下面这段,这段我是翻译的。
为了训练上下文相关模型,举例来说,我们首先用标准的嵌入式训练步骤来训练上下文独立模型,使用多次EM,得到每一个单音素的每一个子音素的单高斯模型。然后我们复制每个单音素模型,比如高斯模型的3个子状态是相同的,对每一个三音素做一个复制。转移矩阵A是不复制的,但是一个单音素的所有三音素复制都做绑定。然后我们再一次运行EM的一次迭代,和重新训练三音素高斯。现在对于每一个单音素,我们用15页上描述的聚类算法来对所有的上下文相关的三音素做聚类,得到绑定状态聚类的一个集合。一个典型的状态被选择作为整个类的代表,剩下的都跟它绑定。
我们使用相同的复制方法来学习混合高斯。首先我们对上述提到的每一个绑定的三音素状态,使用多次迭代的EM算法的嵌入式训练来学习单混合高斯模型。然后我们复制(分裂)每一个状态为2个相同的高斯,通过一些静音来修改其中每一个值,和运行EM来重新训练这些值。这种训练一直到每一个状态的观察量的数量我们都有一定数量的混合。
备注:kaldi或者htk的机制也跟这个类似。
这样我们也能得到每个音素的上下文相关的三音素模型了。这样基本的训练也就结束了,当然这个只是说是最基础的。后来的区分性训练或者其他的处理都没有加。等我看完基础的再看其他的。
如果你有任何疑问,欢迎留言讨论,也可以加入kaldi群跟我讨论。谢谢……
附上之前介绍的gmm-hmm的链接: