一直想写个关于语音识别系统原理的博文。前段时间我和@零落一起做了很多实验,比如htk,kaldi等。从周五开始就已经放寒假了,明天就做火车回家了。今晚加点劲写点吧,回家由于没网。大家有问题只能留言或者找我qq,我尽量过段时间来回答吧。现在我就把语音识别的原理说下去。
具体的框架图还是来一个把。这个图我也是我从网上找的。
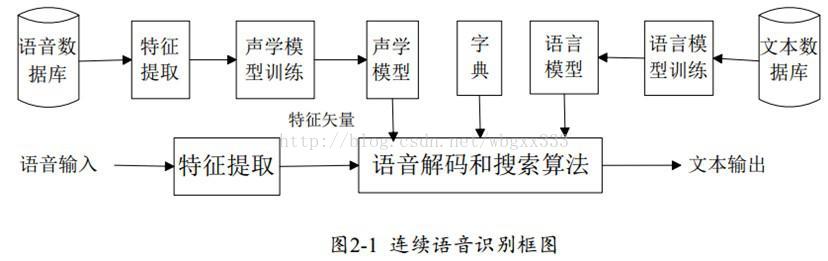
按照上图的说法,语音识别是由语言模型和声学模型构成的。下面我就根据图上的流程说下。
一 特征提取
现在主流的特征是mfcc。具体mfcc的步骤,在我前面转的博客里也有。地址:语音信号处理之(四)梅尔频率倒谱系数(MFCC)。这里我引有知乎里的一个人的说法:
首先说一下作为输入的时域波形。我们知道声音实际上是一种波。常见的mp3、wmv等格式都是压缩格式,必须转成非压缩的纯波形文件,比如Windows PCM文件,即wav文件来处理。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。采样率越大,每毫秒语音中包含的点的个数就越多。另外声音有单通道双通道之分,还有四通道的等等。对语音识别任务来说,单通道就足够了,多了浪费,因此一般要把声音转成单通道的来处理。下图是一个波形的示例。

备注:这个波形你可以用htk里的标注和录音去看。其他的语音处理软件也可以吧。
另外,通常还需要做个VAD处理,也就是把首尾端的静音切除,降低对后续步骤造成的干扰,这需要用到信号处理的一些技术。
时域的波形必须要分帧,也就是把波形切开成一小段一小段,每小段称为一帧。分帧操作通常使用移动窗函数来实现,分帧之前还要做一些预加重等操作,这里不详述。帧与帧之间是有交叠的,就像下图这样:
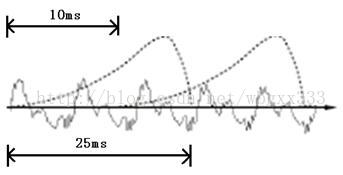
图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。
分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取MFCC特征,把每一帧波形变成一个12维向量。这12个点是根据人耳的生理特性提取的,可以理解为这12个点包含了这帧语音的内容信息。这个过程叫做声学特征提取。实际应用中,这一步有很多细节,比如差分、均值方差规整、高斯化、降维去冗余等,声学特征也不止有MFCC这一种,具体就不详述了。
备注:mfcc的一些处理还是有很多研究的东西。等寒假回来可以跟大家交流。
这里,每个工具箱提供的特征都是不一样的。具体的可以去参考各个工具箱的说明。如:htkbook的第五章。
最后,这个mfcc的变形有很多,也就是对于mfcc的改进也很多。适合自己的才是最好的。此外,这步处理后就是一组13维*帧数的二维向量。这步在训练和测试都得做。
二 声学模型
特征提取完毕就是声学模型的事情。通常需要大量的数据来训练我们的声学模型。这样,我们最后的识别率才是理想。这步就是用马尔科夫模型的过程。具体的细节我暂时也写不清楚。我贴一个图,希望对你理解有好处。
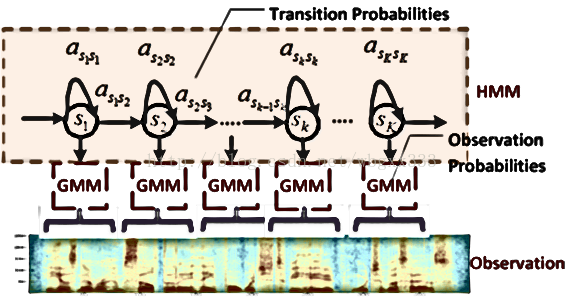
稍微说明一下:最下面的observation就是我们提取的特征。gmm-hmm就是把我们的特征用混合高斯模型区模拟,然后把均值和方差输入到hmm的模型里。
此外,dnn-hmm的模型图:
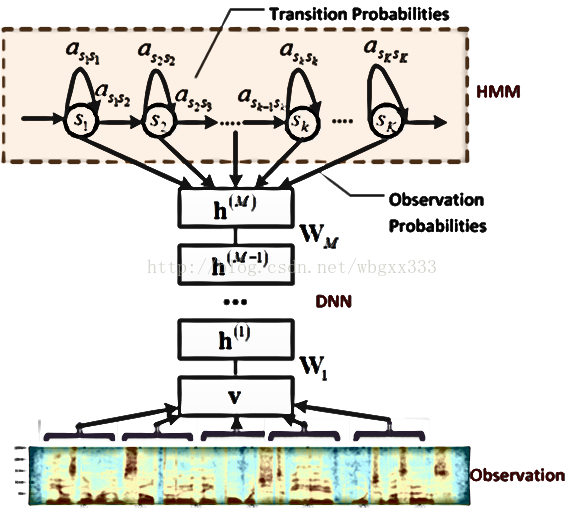
最后是dbn-hmm:
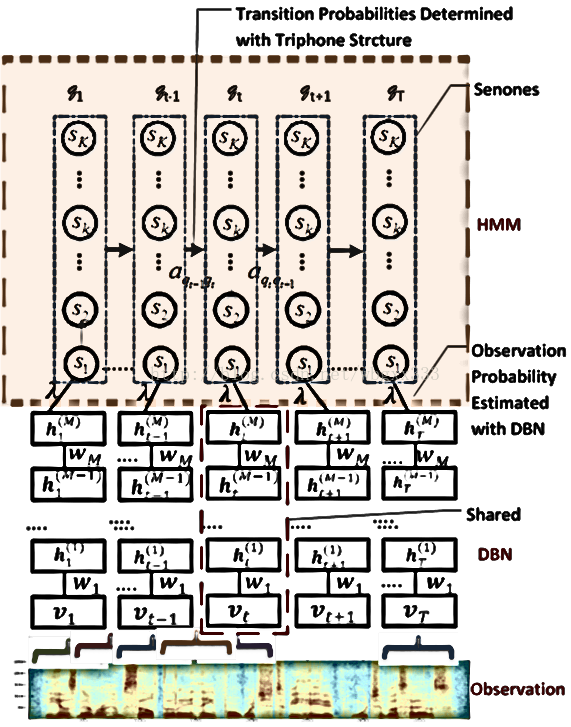
希望我寒假过来可以很好的解释这三个图,如果有人可以解释这三个图,欢迎和我联系,与我交流。谢谢……
这些就是声学模型的全部了。如果你有时间,欢迎分享你的理解。
三 语言模型
语言模型,我就引用@zouxy09的博客。
语言模型是用来计算一个句子出现概率的概率模型。它主要用于决定哪个词序列的可能性更大,或者在出现了几个词的情况下预测下一个即将出现的词语的内容。换一个说法说,语言模型是用来约束单词搜索的。它定义了哪些词能跟在上一个已经识别的词的后面(匹配是一个顺序的处理过程),这样就可以为匹配过程排除一些不可能的单词。
语言建模能够有效的结合汉语语法和语义的知识,描述词之间的内在关系,从而提高识别率,减少搜索范围。语言模型分为三个层次:字典知识,语法知识,句法知识。
对训练文本数据库进行语法、语义分析,经过基于统计模型训练得到语言模型。语言建模方法主要有基于规则模型和基于统计模型两种方法。统计语言模型是用概率统计的方法来揭示语言单位内在的统计规律,其中N-Gram模型简单有效,被广泛使用。它包含了单词序列的统计。
N-Gram模型基于这样一种假设,第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。
四 待续……还有很多,……寒假过来补吧……
希望这个对大家理解整个过程有点用。具体的细节过程寒假过后补过来。如果大家有任何想法和建议,欢迎留言和与我交流。
最后,这是本命年最后一个博客应该。来年我希望我自己可以在语音识别做得更多,希望和大家一起学习,一起努力……加油……提前祝大家新春快乐。