
[HMM对语音信号的序列特性进行建模,DNN对所有聚类后的状态(聚类后的三音素状态)的似然度进行建模。对时间上的不同点采用同样的DNN]
HMM三大问题:
通过训练,得到三个参数:初始状态概率分布pai,隐含状态序列的转移矩阵A(就是某个状态转移到另一个状态的概率观察序列中的这个均值或者方差的概率)和某个隐含状态下输出观察值的概率分布B。
CD-DNN-HMM包含三个组成部分:dnn,hmm,一个状态先验概率分布prior。
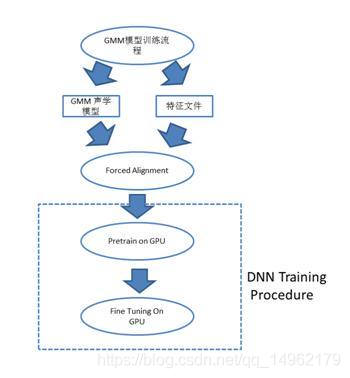
[DNN声学模型训练流程]
1.CD-DNN-HMM系统和GMM-HMM系统共享音素绑定结构(即Topo结构),训练CD-DNN-HMM第一步是使用训练数据训练一个GMM-HMM系统作为初始化模型。
2.用训练好的GMM-HMM模型hmm0创建一个从状态名字到senoneID的映射,在训练数据上采用维特比算法生成一个状态层面的强制对齐,利用stateTosenoneIDMap,把其中的状态名转变为senoneIDs。然后可以生成从特征到senoneID的映射对(featuresenoneIDPairs)来训练DNN。相同的featuresenoneIDPairs也被用来估计senone先验概率。
训练流程如下:
——训练CD-DNN-HMM
——使用CD-DNN-HMM对训练语料进行维特比解码,强制对齐特征和状态。
——DNN训练
dnn训练的准则是基于后验概率,而hmm训练的准则是基于似然概率。