环境准备
先启动hadoop集群
然后启动mysql
[root@master ~]# mysql -u root -p
输入密码进入mysql并切换到数据库hive
mysql> use hive;
启动hive
[root@master sbin]# hive
数据集准备
本地有以下两个数据文件作为表的数据源
ratings.csv:
1,31,2.5,1260759144
1,1029,3.0,1260759179
1,1061,3.0,1260759182
格式:userid,movieid,rating,timestamp
movies.csv:
1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy
2,Jumanji (1995),Adventure|Children|Fantasy
3,Grumpier Old Men (1995),Comedy|Romance
格式:movieid,movie_name,genres
创建表
movie内部表
1)创建movie内部表
在hive中执行以下建表语句,成功后会在hdfs中创建/movie_table目录,其中“row format delimited fields terminated by ‘,’ ”指定每行按逗号分隔字段;“ location ‘/movie_table’ ”指定在hdfs的哪个目录下存放表数据文件,如果不指定则会在/hive/warehouse/(hive-site.xml里配置)下创建表目录
CREATE Table movie_table
(movieid STRING,
title STRING,
genres STRING
)
row format delimited fields terminated by ','
stored as textfile
location '/movie_table'
也可将建表语句写到create_movie_table.sql,在本地执行以下命令建表:
[root@master boya]# hive -f create_movie_table.sql
2)往movie表里加载数据
将本地文件movies.csv上传到hdfs的/movie_table
[root@master boya]# hdfs dfs -put movies.csv /movie_table
此时在hive查询movie_table,会查到数据
hive> select * from movie_table limit 10;
3)删除movie表
在hive上执行删除表命令,成功后hive没有此表,hdfs上也没有了/movie_table目录。内部表会将表结构和数据一起删除。
hive> drop table movie_table;
rating外部表
1)创建rating外部表,在hive执行以下建表命令:
CREATE EXTERNAL Table rating_table
(userid STRING,
movieid STRING,
rating STRING,
ts STRING
)
row format delimited fields terminated by ','
stored as textfile
location '/rating_table'
2)往rating表里加载数据
在movie表里加载数据时是手动将数据复制到表目录中,这里使用LOCAL关键字将本地数据加载到表中,本地数据被复制到创建表时指定的目录中
hive> LOAD DATA LOCAL INPATH '/home/boya/ratings.csv' INTO TABLE rating_table;
此时hdfs上的/rating_table目录下存在ratings.csv文件,使rating有了数据来源
3)删除rating表
在hive里执行删除表命令,hive里就没有了rating-table,但在hdfs上仍然存在此表的目录及数据文件/rating_table/ratings.csv。外部表只删除表结构,数据还是保留的。
4)再次创建rating表
在hive里执行以下命令,此时不指定location,则会在hdfs的/hive/warehouse目录下创建rating_table表目录。不指定外部表的存放路径,这样Hive将在hdfs上的/hive/warehouse/目录下以外部表的表名创建一个目录,并将属于这个表的数据存放在这里
CREATE EXTERNAL Table rating_table
(userid STRING,
movieid STRING,
rating STRING,
ts STRING
)
row format delimited fields terminated by ','
stored as textfile
5)装载数据
加载hdfs的数据到rating表中,发现数据文件rating.csv从hdfs的/rating_table目录下移动(类似mv)到/hive/warehouse/rating_table目录中,本质是load一个hdfs上的数据时会转移数据
hive> LOAD DATA INPATH '/rating_table/ratings.csv' INTO TABLE rating_table;
join操作
rating表和movie表有相同的字段movieid,对两表作join操作产生MapReduce,其中“ /* +MAPJOIN(A) */ ”指定A表为小表,MAPJOIN会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据作匹配,由于在map进行了join操作,省去了reduce运行的效率也会高很多
select /* +MAPJOIN(A) */ B.userid, A.title, B.rating
from movie_table A
join rating_table B
on A.movieid == B.movieid
limit 100
产生新表
将上面join操作得来的数据存放进一张新表,产生MapReduce,执行成功后表的数据存放在hdfs的/hive/warehouse/behavior_table/000000_0:
create table behavior_table as
select /* +MAPJOIN(A) */ B.userid, A.title, B.rating
from movie_table A
join rating_table B
on A.movieid == B.movieid
limit 10
数据导出
1)导出到本地,执行MapReduce
INSERT OVERWRITE LOCAL DIRECTORY '/home/boya/hive_tmp' select userid, title from behavior_table;
2)导出到hdfs,执行MapReduce
INSERT OVERWRITE DIRECTORY '/hive_tmp' select userid, title from behavior_table;
分区Partition
1)创建分区表
Hive的分区使用HDFS的子目录功能实现。每一个子目录包含了分区对应的列名和每一列的值。但是由于HDFS并不支持大量的子目录,这也给分区的使用带来了限制。我们有必要对表中的分区数量进行预估,从而避免因为分区数量过大带来一系列问题。
一个表可以在多个维度上进行分区,并且分区可以嵌套使用。Hive 的分区通过在创建表时启动 PARTITION BY 实现,用来分区的维度并不是实际数据的某一列,具体分区的标志是由插入内容时给定的。建分区需要在创建表时通过PARTITIONED BY子句指定,例如以下命令创建datatime字段作为分区列
CREATE Table rating_table_p
(userid STRING,
movieid STRING,
rating STRING
)
partitioned by(datetime STRING)
row format delimited fields terminated by '\t'
lines terminated by '\n';
注意:PARTITONED BY子句中定义的列是表中正式的列(分区列),但是数据文件内并不包含这些列。分区列也不是表中的一个实际的字段,而是一个或者多个伪列。意思是说,在表的数据文件中实际并不保存分区列的信息与数据。
执行以下语句可查看表的结构信息,如列名,分区名,所属数据库Database,存放位置Location,桶Buckets等,其中可看到Location为hdfs://192.168.230.10:9000/hive/warehouse/rating_table_p
hive> desc formatted rating_table_p;
2)往分区表里装载数据
在将数据加载到表内之前,需要数据加载人员明确知道所加载的数据属于哪一个分区。例如将2003-10.data.small文件的数据装入分区表中,文件数据如下:
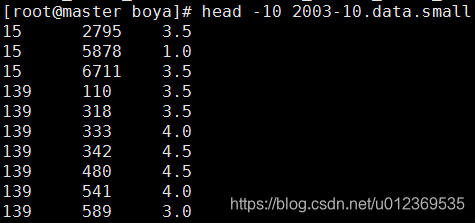
执行以下命令,指定该文件数据对应的分区列的值为‘2003-10’,执行成功后hive会在hdfs的/hive/warehouse/rating_table_p目录下建立datetime=2003-10子目录,并将2003-10.data.small文件放进datetime=2003-10子目录内
LOAD DATA LOCAL INPATH '/home/boya/2003-10.data.small' OVERWRITE INTO TABLE rating_table_p partition(datetime='2003-10');
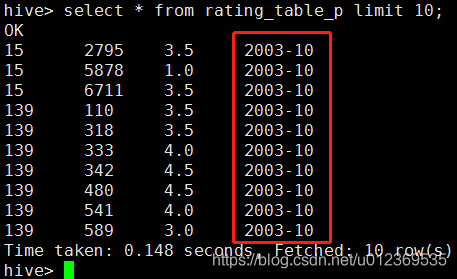
此时查询分区表的数据,会发现获得的数据中多出了时间伪列,而执行desc rating_table_p会发现表结构依然是userid、movieid和rating三个字段

分桶Bucket
Hive 中 table 可以继续拆分成 Partition table(分区表) 和 桶(BUCKET)表,桶操作是通过 Partition 的 CLUSTERED BY 实现的,BUCKET 中的数据可以通过 SORT BY 排序。
BUCKET 主要作用如下:
数据 sampling;
提升某些查询操作效率,例如 Map Side Join。
1)创建桶表
set hive.enforce.bucketing=true;
CREATE Table rating_table_b
(userid STRING,
movieid STRING,
rating STRING
)
clustered by (userid) INTO 16 buckets;
‘set Hive.enforce.bucketing=true’ 可以自动控制上一轮 Reduce 的数量从而适配 BUCKET 的个数,当然,用户也可以自主设置 mapred.reduce.tasks 去适配 BUCKET 个数,推荐使用:hive> set Hive.enforce.bucketing=true;
执行desc formatted rating_table_b可查看桶表的结构信息,如Num Buckets:16,Bucket Columns:[userid]
桶是通过对指定列下的值进行哈希计算来实现的,并用hash结果除以桶的个数做取余运算的方式来分桶,从而将数据打散,保证了每个桶中都有数据,但每个桶中的数据条数不一定相等。通过哈希值将一个列名 (userid)下的数据切分为一组桶,并使每个桶对应于该表名目录下的一个存储文件。
每个桶就是表(或分区)目录里的一个文件。它的文件名并不重要,但是桶 n 是按照字典序排列的第 n 个文件。事实上,桶对应于 MapReduce的输出文件分区:一个作业产生的桶(输出文件)和reduce任务个数相同.
2)向桶中插入数据
从外部表rating_table中导入数据到桶表,执行以下命令,产生MapReduce:
from rating_table
insert overwrite table rating_table_b
select userid, movieid, rating;
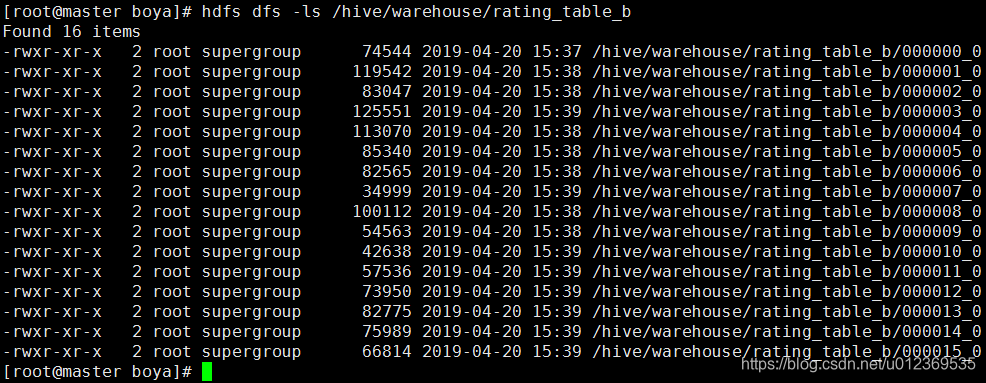
在建表时按照用户id分成了16个桶,这里在插入数据时对应16个reduce操作,输出16个文件。
 3)采样
3)采样
- tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUT OF y)
- y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分为64个bucket,当y=32时,抽取(64 / 32=)2个bucket的数据,当y=128时,抽取(64 / 128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。例如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32 / 16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。
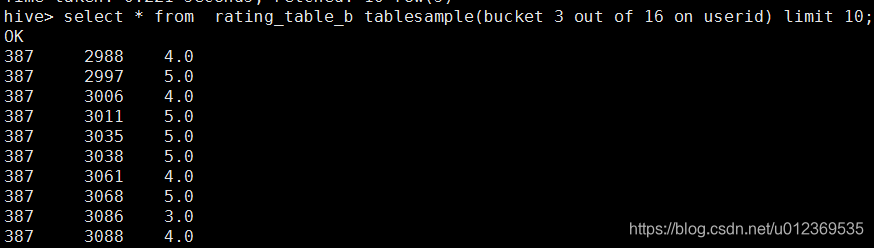
rating_table_b分成16个bucket,执行以下语句,抽取第3个bucket的数据:
select * from rating_table_b tablesample(bucket 3 out of 16 on userid) limit 10;
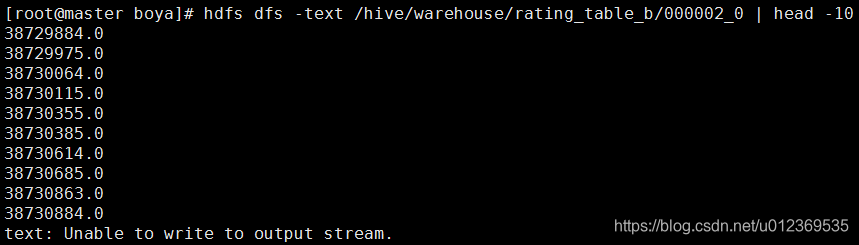
 验证是否是hdfs上第三个桶的数据,发现从/hive/warehouse/rating_table_b/000002_0抽取的数据:
验证是否是hdfs上第三个桶的数据,发现从/hive/warehouse/rating_table_b/000002_0抽取的数据:
对分区表再进行分桶
1)创建分区分桶表
set hive.enforce.bucketing=true;
CREATE Table rating_table_p_b
(userid STRING,
movieid STRING,
rating STRING
)
partitioned by(datetime STRING)
clustered by (userid) sorted by (movieid)
INTO 4 buckets
row format delimited fields terminated by ‘\t’
lines terminated by ‘\n’;
分区中的数据可以被进一步拆分成桶,先partitioned by (datetime STRING),再clustered by (userid) sorted by(movieid) into 4 bucket
2)插入数据
from rating_table_p
insert overwrite table rating_table_p_b partition(datetime='2003-10')
select userid, movieid, rating where datetime='2003-10' sort by movieid;
执行成功后查看hdfs,发现/hive/warehouse/rating_table_p_b/datetime=2003-10目录下有四个文件
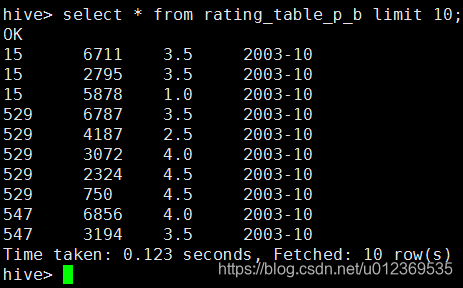
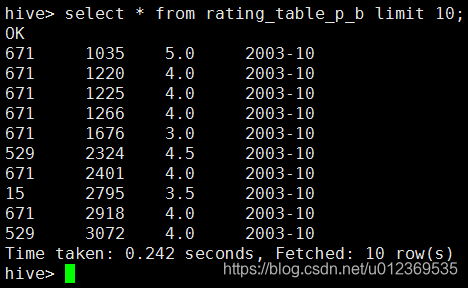
 在hive查询rating_table_p_b表,发现按movieid升序:
在hive查询rating_table_p_b表,发现按movieid升序:
 另外,如果不使用set hive.enforce.bucketing=true这项属性,我们需要显式地声明set mapred.reduce.tasks=4来设置Reducer的数量。此外,还需要在SELECT语句后面加上CLUSTERBY来实现INSERT查询。
另外,如果不使用set hive.enforce.bucketing=true这项属性,我们需要显式地声明set mapred.reduce.tasks=4来设置Reducer的数量。此外,还需要在SELECT语句后面加上CLUSTERBY来实现INSERT查询。
from rating_table_p
insert overwrite table rating_table_p_b partition(datetime='2003-10')
select userid, movieid, rating where datetime='2003-10' cluster by userid;
执行以上语句在hdfs中有四个输出文件,但在hive查询时没有按movieid升序,若加上order by movieid,则产生MapReduce按字典排序