数字图像处理第八章
数字图像处理—图像压缩
目前是毕业论文,毕业设计的后期验收阶段,所以时间不是很充裕,暂时对书上已经写得很清楚的知识点不再重复赘述,主要做一些总结,思考以及知识点的梳理和扩展。
图像压缩原理:
- 数据压缩的对象是数据,大的数据量并不代表含有大的信息量。
- 图像压缩就是除去图像中多余的数据而对信息没有本质的影响。
- 图像压缩是以图像编码形式实现的,用较少的比特数表示出现概率较大的灰度级,用较多的比特数表示出现概率较小的灰度级,从而使平均码长更接近于信息熵。
图像压缩目的:减少表示数字图像时所需的数据量。减少数据量的基本原理是除去其中多余的数据。从数学角度看,这一过程实际上就是将二维像素矩阵变换为一个在统计上无关联的数据集合。
图像压缩方法分类:
-
按压缩前及压缩后的信息保持程度分类:
(1)信息保持型
压缩、解压中无信息损失,主要用于图像存档,其特点是信息无损失,但压缩比有限,也称无失真/无损/可逆型编码。
(2)信息损失型
牺牲部分信息,来获取高压缩比,数字电视,图像传输和多媒体应用场合常用这类压缩,其特点是通过忽略人的视觉不敏感的次要信息来提高压缩比,也称有损压缩。
(3)特征抽取型
仅对于实际需要的(提取)特征信息进行编码,而丢掉其他非特征信息,属于信息损失型。
第三类针对特殊的应用场合。因此,一般将图像压缩编码分成无损和有损两大类。 -
按图像压缩的方法原理可分成四类:
(1)像素编码
编码时只对每个像素单独处理。如脉冲编码调制,熵编码,行程编码等。
(2)预测编码
通过去除相邻像素之间的相关性和冗余性,只对新的信息进行编码。常用的有差分脉冲编码调制。
(3)变换编码
对给定图像采用某种变换,使得大量的信息能用较少的数据表示。通常采用的变换包括:离散傅里叶变换(DET),离散余弦变换(DCT)和离散小波变换(DWT)。
(4) 其他方法
早期的编码,如混合编码,矢量量化,LZW算法。
近些年来也出现了很多新的压缩编码方法,如使用人工神经网络的压缩编码算法、分形、小波、基于对象的压缩编码方法、基于模型的压缩编码算法等。
数据冗余定义:
数据是用来表示信息的。如果不同的方法为表 示给定量的信息使用了不同的数据量,那么使用 较多数据量的方法中,有些数据必然是代表了无用的信息,或者是重复地表示了其它数据已表示的信息,压缩是通过去除一个或三个基本数据冗余达到的。
如果n1和n2代表两个表示相同信息的数据集合 中所携载信息单元的数量,则n1表示的数据集合 的相对数据冗余
定义为:

为压缩率,定义为:
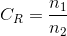
相对数据冗余和压缩率的一些特例:
| n1相对于n2 | 对应的情况 | ||
|---|---|---|---|
| n1=n2 | 1 | 0 | 第1种表达相对第2种表达不含冗余数据 |
| n1>>n2 | →∞ | →1 | 第1种数据集合包含相当多的冗余数据 |
| n1<<n2 | →0 | →∞ | 第2种数据集合包含相当多的冗余数据 |
三种基本的数据冗余
- 编码冗余
如果一个图像的灰度级编码,使用了多于实 际需要的编码符号,就称该图像包含了编码冗余。
举例:黑白二值图像编码

如果用8位表示该图像的像素,我们就说该图像存在编码冗余,因为该图像的像素只有两个灰度,用一位即可表示。
图像直方图的定义:
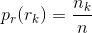
k=0,1,2,…,L-1
是第k个灰度级在图像中出现的次数,n是图像 中的像素总数,L是灰度级数。
如果用于表示每个
值的比特数为l(
), 则表达每个像素所需的平均比特数为:
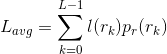
不同的编码方法可能会有不同的Lavg,由此引出两种编码冗余。
- 相对编码冗余:Lavg大的编码相对于Lavg小的编码就存在相对于编码冗余。
- 绝对编码冗余:使Lavg > Lmin的编码就存在绝对编码冗余。
- 像素间冗余
因为一幅图像的像素间,或是图像序列中相邻图像像素间的相关性而造成的冗余。对于一幅图像,很多单个像素对视觉的贡献是冗余的。它的值可以通过与它相邻的像素值为基础进行预测。
例子:原图像数据:234 223 231 238 235
压缩后数据:234 -11 8 7 -3
- 心理视觉冗余
人眼感觉到的图像区域亮度不仅取决于该区域的反射光,例如根据马赫带效应,在灰度值 为常数的区域也能感觉到灰度值的变化,这是由于眼睛对所有视觉信息感受的灵敏度 不同。在正常视觉处理过程中各种信息的相对重要程度不同,有些信息在通常的视觉过程中与另外一些信 息相比并不那么重要,这些信息被认为是心理视觉冗余的,去除这些信息并不会明显降低图像质量。
由于消除心理视觉冗余数据会导致一定量信息的丢失,所以这一过程通常称为量化。心理视觉冗余压缩是不可恢复的,量化的结果导致 了数据有损压缩。
(一) 背景
正如从图 8-1 中可以看到的那样,图像压缩系统是由两个截然不同的结构块组成的:编码器和解码器。

信道:如Internet、广播、通讯、可移动介质。

信源编码器:减少或消除输入图像中的编码冗余、像素间冗余及心理视觉冗余。
转换器:对输入的数据进行转换,以改变数据的描述形式,减少或消除像素间的冗余(可逆)。
量化器:根据给定的保真度准则降低转换器输出的精度,以进一步减少心理视觉冗余(不可逆)。
符号编码器:根据使用的码字为量化器输出和映射 输出创建码字,减少编码冗余。
并不是每个图像压缩系统都必须包含这3种操作,如进行无误差压缩时,必须去掉量化器。
信道编码器和信道解码器:信道是有噪声的或易产生误差时,信道编码器和信道解码器对整个编解码过程非常重要。由于信源编码器的输出数据一般只有很少的冗余,所以它们对输出噪声很敏感。
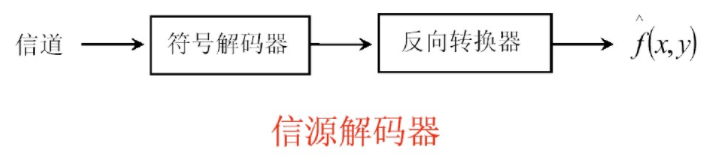
符号解码器:进行符号编码的逆操作。
反向转换器:进行转换器的逆操作。
因为量化操作是不可逆的,所以信源解码器中没有对量化的逆操作。
图像f(x,y)被送入编码器,编码器从输入数据建立一组符号,并用它们描述图像。 如果令n1和n2分别表示原始及编码后的图像携带的信息单元的数量(通常是比特),达到的压缩可以通过压缩比,用数字进行量化:
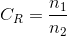
可能是 10(或 10:1)压缩比,这指出在压缩过的数据集中,对于每 1 个单元,原始图像有 10 个携带信息的单元(如比特)。在MATLAB 中,用于表示两幅图像文件或变量的比特数的比率可通过下面的 M-函数计算出来:
function cr = imratio(f1, f2)
error(nargchk(2, 2, nargin)); % Check input arguments
cr = bytes(f1) / bytes(f2); % Compute the ratio
function b = bytes(f)
if ischar(f)
info = dir(f); b = info.bytes;
elseif isstruct(f)
% MATLAB's whos function reports an extra 124 bytes of memory
% per structure field because of the way MATLAB stores
% structures in memory. Don't count this extra memory; instead,
% add up the memory associated with each field.
b = 0;
fields = fieldnames(f);
for k = 1:length(fields)
elements = f.(fields{k});
for m = 1:length(elements)
b = b + bytes(elements(m));
end
end
else
info = whos('f'); b = info.bytes;
end
JPEG 编码图像 sun.jpg的压缩可以通过以下命令进行计算:
r=imratio(imread('D:\数字图像处理\第八章学习\sun.jpg'),'D:\数字图像处理\第八章学习\sun.jpg');

观察并运用压缩的(也就是编码后的)图像,必须把图像发送到解码器(见图 8-1), 这里产生重建的输出图像f^(x,y)。一般而言, f^(x,y)可能是,也可能不是f(x,y)的精确表示。如果是, 系统就是无误差的、信息保持的或无损的;如果不是,在重建图像中会有一部分失真。对于后一种情况,被称为有损压缩,可以对x和y的任意取值在f(x,y)和f^(x,y)之间定义误差e(x,y):
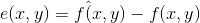
所以,两幅图像间的总误差为:
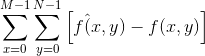
同时,f(x,y)和f^(x,y)之间的均方根(root-mean-square,rms)误差erms是 MxN数组的均方误差的平均值的平方根:
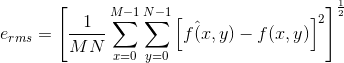
(二) 编码冗余
前面讲过编码冗余,那自然会有如下问题:表示一幅图像的灰度级到底需要多少比特?也就是说,是否存在在不丢失信息的条件下,能足够充分描绘一幅图像的最小数据量?信息论提供了回答这一相关问题的数学框架。
信息测量:
对一个随机事件E,如果它的出现概率是 P(E),那么它包含的信息:
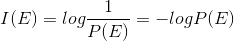
I(E)称为E的自信息。如果P(E)=1(即事件总发 生),那么I(E)=0。
信息信道:

信道是连接信源和用户的物理媒介。它可以是电话线、无线传播、导线或internet。
信源:
- A={ , ,…, }称为信源字母表。
- 信源产生符号
的事件概率是P(
),且
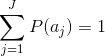
- 一个J×1向量z=[P( ),P( ),P( ),…,P( )]T用于表示所有信源符号的概率集合。
- 有限总体集合(A,z)完全描述了信息源。
- 如果产生k个信源符号,则大数定律保证对于一个充分大的k,符号
将被输出kP(
)次。因此,根据k输出得到的平均自信息是
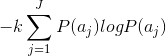
- 每个信源输出的平均信息,也称为信源的熵为
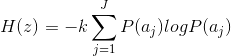
- 如果信源符号的出现是等可能性的,则上述熵被最大化,此时信源提供大信息量。
信道输出 :
- B={ , ,…, }称为信道字母表。
- 提交给用户的字符 的概率是P( )。
- 有限集合(B,v)完整描述了信道输出和用户收到的信息,v=[P( ),P( ),P( ),…,P( )]T。
- 有限总体集合(A,z)完全描述了信息源。
- 给定信道输出概率P(
)和信源符号概率 P(
),它们由下式相联系:
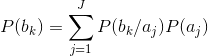
- 将上式中的条件概率放入一个K×J的正向信 道传递矩阵Q,其元素qkj=P(bk|aj)为条件概率
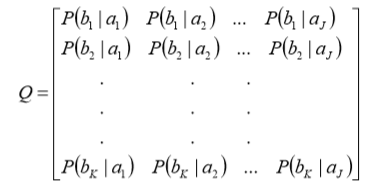
则输出符号集的概率分布由下式计算:
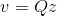
例8.1:计算熵
考虑一幅简单的 4x4图像,下面的命令行顺序生成一幅这样的图像并计算熵的一阶估计:
f=[119 123 168 119; 123 119 168 168];
f=[f; 119 119 107 119;107 107 119 119]



函数 ntrop 使用 find 来建立索引向量 i,加入直方图 xh, 这个直方图随后被用于通过最后一条语句的熵计算,从而消除所有零值元素。如果没有完成的话,函数 log2 在任意符号概率为 0 时强制输出 h 到 NaN(0*-inf 的结果不是数字)。
2.1 霍夫曼码
当对一幅图像的灰度级或某个灰度级映射操作的输出进行编码时(像素差、行程长度,等等),霍夫曼码包含了对于每个信源符号(比如灰度值)可能的最小编码符号(如比特)数,遵从每 次仅编码一个信源符号的限制条件。
霍夫曼编码具体步骤:
- 通过对符号的概率进行排序,建立信源递减序列,这种符号排序考 虑了合并最低概率的符号作为单独的符号,并在下一次信源约简时替换它们。在最左边,初始信源符号集和它们的概率按照概率值由高到低降序排序。为了形成第一次信源约简,底部的两个概率值0.125和 0.1875 被合并,形成概率值为 0.3125 的合并过的符号。这个合并过的符号和与之关联的概率被放置在第一次信源约简列,这 样,约简信源的概率还要从最大到最小排序。然后,这个过程一直重复,直到约简信源只有两个符号(在最右边)为止。

- 对每个约简的信源进行编码,编码从最小的信源开始,一直到原始信源。当然,对于两符号信源的最短二进制编码由 0 和 1 组成。这些符号被分配给右边的两个符号(分配是任意的,颠倒 0 和 1 的顺序也是可以的)。概率为 0.5的约简 信源符号通过合并两个约简信源左侧的符号生成,用来编码的 0现在被分配给这些符号,并且 0 和 1 被任意分给每个符号以便区分它们。然后, 这个操作对每个约简信源重复,直到到达原始信源。最终的代码出现在图 8-5的最左列(第 3 列)。

图 8-5中的霍夫曼码是瞬时的、唯一可译码的块编码。之所以是块编码,是因为每个信源符号均映射到固定的码字符号序列。之所以是瞬时的,是因为码字符号字符串 的每个码字可以不参照随后的符号而被译码。也就是说,在任意给定的霍夫曼码中,没有码字是其他码字的前缀。之所以是唯一可译码的,是因为代码符号字符串仅有唯一的译码方法。 这样,任意霍夫曼码符号字符串都可以通过从左到右的方式考察单独字符串而被译码。
下面的命令行序列使用 huffman 产生图 8-5中的码字:

输出是长度可变的字符数组,其中的每一行是由0和 1(对应索引符号 P中的二进制码)组成的字符串。例如,‘010’是概率为0.125的灰度级的码字。
2.2 霍夫曼编码
霍夫曼编码基本思想:
- 完全依据字符出现概率进行编码
- 出现概率高的字符使用较短的编码
- 出现概率低的字符使用较长的编码
- 编码后平均码字长最短
霍夫曼编码算法:
- 信源符号按概率分布大小,以递减次序排列。
- 取两个最小的概率,分别赋以“0”,“1”。
- 按重排概率值,重复(2)…,直到概率和达到1为止。
- 由后向前排列码序,即得霍夫曼编码。
霍夫曼编码具体步骤:
- 统计像素出现的概率——得到由大到小排列的像素概率表。
- 构建霍夫曼树——a.从2个概率最小的开始做父节点,b.循环操作a,最终做到根节点1的位置结束。
- 对图像进行编码——从父节点开始到根节点结束,排序后进行逆序,即为编码,并建编码模式表。
设有数字图像,其灰度集合为X={x1,x2,x3,x4,x5,x6},
其概率分布为P(x1)=0.4,P(x2)=0.3,P(x3)=0.1,P(x4)=0.1,P(x5)=0.06,P(x6)=0.04,
现求其最佳霍夫曼编码W={w1,w2,w3,w4,w5,w6}:
| 元素 | xi | x1 | x2 | x3 | x4 | x5 | x6 |
|---|---|---|---|---|---|---|---|
| 概率 | P(xi) | 0.4 | 0.3 | 0.1 | 0.1 | 0.06 | 0.04 |
| 编码 | wi | 1 | 00 | 011 | 0100 | 01010 | 01011 |

霍夫曼变长编码方法能得到一组最优的变长码,其过程是:
- 把信源x中的消息按出现的概率从大到小的顺序排列。
- 把最后两个出现概率最小的消息合并成一个消息,从而使信源的消息数减少一个,并同时再次将信源中的消息概率从大到小排列一次。
- 重复上述步骤,直到信息源最后为两个信息源 为止。
- 对最后的信息源赋予1和0或0和1,并逐步向前编码。
通过上述步骤就可以构成最优变长码。
经霍夫曼编码后,平均码长长度为:
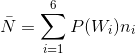
=0.4x1+0.3x2+0.1x3+0.1x4+0.06x5+0.04x5
=2.20(bit)
图像熵值:(熵表示每个像素的平均信息量为多少比特,是编码所需比特数的下限)
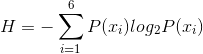
=-0.4lo
0.4-0.3lo
0.3-2x0.1lo
0.1-0.06lo
0.06-0.04lo
0.04
2.14(bit)
平均码长与H接近,
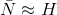
在一般情况下,编码效率往往用下列简单公式表示:
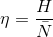
例8.2 : MATLAB中的变长编码映射
考虑简单的 16 字节 4x4图像:

f2 中的每个像素都是8比特的字节,16 字节用于表现整幅图像。因为 f2 的灰度不是等概率的,所以变长码字会减少表现图像所必需的存储量。 函数 Huffman 计算如下码字:

因为霍夫曼码与被编码的信源符号出现的频率有关(不是信号本身),所以 C 和例 8.1 中构成图像的码字一样。事实上,图像 f2 可以从例 8.1 中分别把灰度级107、119、123 和 168 映射到 1、2、3、4 来得到。对于任何一幅图像,p = [ 0.1875 0.5 0.125 0.1875]。
基于码字 c 对 f2 编码的简单方法是执行如下简单的查表操作:

这里,f2(UNIT8 类的二维数组)被变换成单元数组 hlf2 转置的紧凑显示。hlf2 中的元 素是可变长度的字符串,并对应 f2 中从上到下、从左到右扫描的像素(也就是列方式)。正如看到的那样,被编码的图像用了存储的 1018 个字节,基本上是f2要求的存储量的 60倍。
对 hlf2 使用的单元数组是合乎逻辑的,因为这是处理不同数据的两个标准 MATLAB 数据结构之一。对于 hlf2,不同之处在于字符串的长度,以及为通过单元数组透明 地处理它所付出的代价是存储器的总开销(单元数组固有的特性),要求必须追踪变长元素的位置。可以通过把 hlf2 变换为两维的字符数组来减少此开销。

在这里,单元数组 hlf2 被变换为 3x16 的字符数组 h2f2。h2f2 的每一列以从上到下、 从左到右扫描方式对应 f2 中的像素,也就是列方式)。注意,空白处被以合适的尺寸插入数组, 并且因为对于码字的 0 和 1 都要求两字节,所以 h2f2 的存储总量是96 字节,还是比 f2 需要 的原始 16 字节大6倍。可以像下面这样来消除插入的空格:

但是要求的存储空间还是比 f2 的原始 16 字节大。 为了压缩 f2, 码字 C 必须在比特级应用,用一些编码像素打包成单字节:

虽然 mat2huff 函数返回结构 h3f2, 但仍要求 518 个字节的存储量,其中大部分开销都和下面两个因素有关: 1)结构可变的开销MATLAB 中的每个 结构字段需要 124 个字节的开销) ;2) mat2huff 产生的信息更易于将来的译码。忽视这些开销, 当考虑实际(比如普通大小)的图像时,它们是可以忽略掉的。mat2huff 以 4:1 的比率压缩 f 2。f2 的 16 个 8比特像素被压缩为两个16比特的字 h3f2 中字段 code 的元素:

注意,dec2bin 被用来显示 h3f2.code的单比特。忽视末尾的模 16 的插入比特(最后的 3 个 0),32 比特编码相当于先前产生的、瞬时且唯一的、可解码的 29 比特码字10101011010110110000011110011。
例8.3 :用 mat2huff 进行编码
f1=rgb2gray(imread('D:\数字图像处理\第八章学习\face.jpg'));
c=mat2huff(f1);
cr1=imratio(f1,c)

通过去除与传统的 8比特二进制编码相关联的那些编码冗余,图像已被压缩到原来大小的 80%左右(与包含的译码开销信息一样)。因为 mat2huff 的输出是结构,所以用 输出写入磁盘:
save SqueezeTracy c;
cr2 = imratio('D:\数字图像处理\第八章学习\face.jpg','SqueezeTracy.mat')

save函数与菜单命令Save Workspace As和SaveSelection As一样。为创建的文件添加.mat 扩展名。在这种情况下,产生的文件 SqueezeTracy.mat 被叫做MAT-文件。它是二进制数据文件,包括工作空间变量名和值。 在这里,它包括单独的工作空间变量 c。 最后, 我们注意到先前计算出的压缩率 crl 与 cr2 之间的微小差异,该差异源于 MATLAB数据文件的开销。
2.3 霍夫曼译码
霍夫曼编码图像几乎没什么用,除非能被解码并重建为刚开始时的原始图像。前面一节的输出 y = mat2huff (x) ,解码器必须首先计算用来编码 x 的霍夫曼码(基于 x 的直方图 和 y 中有关的信息),然后反映射已编码的数据(还是从 y 中提取)来重建 x。
正如在下面列出的函数 x=huff2mat (y) 中看到的那样,上述处理可以分为 5 个基本步骤:
(1) 从输入结构 y 中提取维数 m 和 n,以及最小值 xmin(最后的输出 x)。
(2) 重新创建霍夫曼码,通过将它的直方图传递到 huffman 函数来对 x 进行编码。在列 表中产生的编码将被map 调用。
(3) 建立数据结构(转换和输出表 link), 以便在 y.code 中通过一系列有效的二进制搜索 对编码数据解码。
(4) 传递数据结构和已编码数据(比如 link 和 y.code)到 C 函数 unravel。这个函数最 小化为执行二进制搜索要求的时间,产生已解码的 double 类的输出向量 X。
(5) 把xmin添加到x的每个元素中,并加以改造以匹配原始x的维数(也就是m行和n列)。
huff2mat 的唯一特点是对 MATLAB 可调用C 函数 unravel 的结合(见步骤(4)),这使得对大多数标准分辨率的图像的解码几乎都是瞬时的。
(三)空间冗余
空间冗余:图像内部相邻像素之间存在较强的相关性多造成的冗余。
f1=imread('D:\数字图像处理\第八章学习\Fig0807(a).tif');
f2=imread('D:\数字图像处理\第八章学习\Fig0807(c).tif');
subplot(2, 2, 1), imshow(f1);title('(a)原图像');
subplot(2, 2, 2), imhist(f1);title('(b)a图直方图');
subplot(2, 2, 3), imshow(f2);title('(c)原图像');
subplot(2, 2, 4), imhist(f2);title('(d)c图直方图');




注意,这两幅图像的一阶熵估计大致相同(分别为7.4253和 7.3505 比特/像素);它们同样由 mat2huff 压缩(压缩比为 1.0704 和 1.0821)。这些明显强调了如下事实:变长编码的设计不是为了利用图8-6©中排成一排的火柴之间的明显结构关系的优点。虽然在图像中,像素与像素之间的相关性更明显,但这一现象在图8-6(a)中也存在。因为任何一幅图中的像素都可以合理地从 它们的相邻像素值预测,这些单独像素携带的信息相对较少。单一像素的视觉贡献对一幅图像 来说大部分是多余的;它们应该能够在相邻像素值的基础上推测出来。这些相关性是像素间冗余的潜在基础。
为了减少像素间的冗余,通常必须把由人观察和解释的二维像素数组变换为更有效的格式 (但通常是“不可视的”) 。例如,邻近像素点之间的差值可以用来表示一幅图像。这种类型(也就是说,移走像素间的冗余)的变换被称为映射。如果原始图像可以从变换的数据集重建,它们就被称为可逆映射。 图 8-7 展示了简单的映射过程。这种被称为无损预测编码的处理方法可以通过对每个像素中新的信息进行提取和编码来消除相近像素间的冗余。像素的新信息被定义为实际值和预测值 的差值。由此可见,系统由编码器和解码器组成,每个都含有相同的预测器。当每个输入图像 中相继的像素表示为fn时,fn被送进编码器,预测器以过去某些输入为基础产生像素的预测值。 预测器的输出被四舍五入成最接近的整数。表示为f^n; 并用来产生差或预测误差:
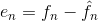

预测误差用变长编码(通过符号编码器)产生压缩数据流的下一个元素。 图 8-7中的解码器用收到的变长码字执行相反的操作以重建 :
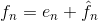
各种本地的、全局的和自适应方法可以用来产生f^n。然而对于大部分情况,预测由前面的 几个像素的线性结合而形成,也就是:
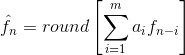
这里, m是线性预测器的阶, “ round”是用来表示四舍五入或接近整数的函数(就像 MATLAB 中的 round 函数)。并且对于 i=l, 2⋯,m 是预测参数。对于一维线性预测编码,这个等式可以写作:
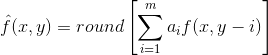
这里,每个带下标的变量已明确作为空间坐标(xy)的函数来表示。注意预测f^(x,y)是当前的扫描行上前一些像素的函数。
M-函数mat21pc和 lpc2ma执行刚才讨论的预测编码和解码处理(负符号编码和解码的步骤)。
例8.5 无损预测编码
编码思想:
认为相邻像素的信息有冗余。当前像素值可以用以前的像素值来获得。(去除像素冗余)
操作:
用当前像素值
,通过预测期得到一个预测值f^n,对当前值和预测值求差,对差编码,作为压缩数据流中的下一个元素。
由于差比元数据要小,因而编码要小,可用变长编码。大多数情况下,fn的预测是通过M个以前像素的线性组合来生成的。
编码过程:
- 压缩头处理
- 对每一个符号:f(x,y),由前面的值,通过预测器,求出预测值f^(x,y)
- 求出预测误差:e(x,y)=f(x,y)-f^(x,y)
- 对误差e(x,y)编码,作为压缩值。
- 重复二,三,四步。
解码过程:
- 对头解压缩
- 对每一个预测误差的编码解码,得到预测误差e(x,y)。
- 由前面的值,得到预测值f^(x,y)。
- 误差e(x,y),与预测值f^(x,y)相加,得到解码f(x,y)。
- 重复二,三,四步。
编码分析:
f=imread('D:\数字图像处理\第八章学习\Fig0807(c).tif');
subplot(1, 3, 1);imshow(f);
title('(a)预测编码原图')
fshang=entropy(f) %fsang=7.3505
c0=mat2huff(double(f));
cfshang=entropy(c0.code) %cfshang=7.9963
cfr=imratio(f,c0) %cfr=1.0821,即huffman编码后熵变大
%预测编码
e=mat2lpc(f);
subplot(1, 3, 2),imshow(mat2gray(e));
title('(b)线性预测编码后图');
esgang=entropy(e) %esang=5.9727,变小
cer=imratio(f,e)%cer=1.0821
c=mat2huff(e); %将lpc编码后继续进行huffman编码
ceshang=entropy(c.code) %7.9937
cr=imratio(f,c) %1.3311
[h,x]=hist(e(:)*512,512);
subplot(1, 3, 3),bar(x,h,'k');title('(c)预测误差直方图');
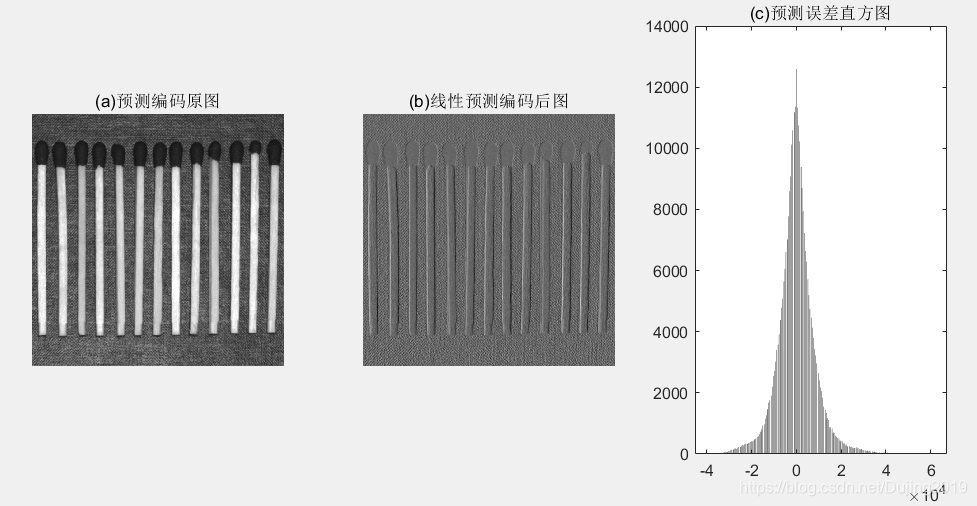
总结:预测误差的熵 e 显著地比原始图像 f 的墒要小。尽管 m比特图像需要(m+1)个比特 以准确表示造成的误差序列,但是熵已从 7.3505比特/像素减少到 5.9727比特/像素。熵的减少意味着预测误差图像可以比原始图像更有效地进行编码,当然这是映射的目标。压缩率从 1,0821(当直接对灰度级进行霍夫曼编码时)增大到 1.3311。0周围的峰值很高,与输入图像的灰度级务布相比有相对较小的方差。 这反映出正如前面计算的熵值那样,由预测和微分处理移去了大量的像素间冗余。
(四)不相关的信息
与编码及像素间冗余不同,心理视觉冗余和真实的或可计量的视觉信息有联系。心理视觉冗余的去除是值得的,因为对通常的视觉处理来说,信息本身不是本质的。因为心理视觉冗余数据的消除引起的定量信息损失很小,所以称为量化。这个术语和普通词的用法一样。通常意味着把宽范围的输入值映射为有限数量的输出值。这是不可逆操作(也就是说,视觉信息有损失),量化将导致数据的有损压缩。
有损压缩概述:
- 牺牲图像复原的准确度以换取压缩能力的增加;
- 如果产生的失真可以容忍,则压缩能力的增加是有效的;
- 压缩率较大,有损压缩编码技术可达100:1压缩率,并且10:1~50:1之间,图像无本质区别(单色图像)。
常用的有损编码方法:预测编码、变换编码…
预测编码:预测编码是通过消除紧邻像素在空间和时间上的冗余实现的,它仅对每个像素中的新信息进行提取并代替原图像进行编码。新信息=实际值-预测值,即预测误差。在各类编码方法中,预测编码是比较容易实现的,如微分(差分)脉冲编码调制(DPCM)方法。
有损预测编码:直接对像素在图像空间进行操作,称为空域方法。与无损预测编码的不同之处在于:是否存在量化器。


编码过程:
- 压缩头处理
- 对每一个符号:f(x,y),由前面的值,通过预测器,求出预测值f^(x,y)
- 求出预测误差:e(x,y)=f(x,y)-f^(x,y)
- 对误差e(x,y)编码,作为压缩值。
- 重复二,三,四步。
解码过程:
- 对头解压缩
- 对每一个预测误差的编码解码,得到预测误差e(x,y)。
- 由前面的值,得到预测值f^(x,y)。
- 误差e(x,y),与预测值f^(x,y)相加,得到解码f(x,y)。
- 重复二,三,四步。
误差信号:
=
-
^
量化器误差:
=
-
’
接收端输出:
’=
^-
’
可以推出:
-
‘=
当
等于0时,无损预测编码
当
不等于0时,有损预测编码
失真对所有的有损预测编码都是很普遍的。失真的严重性取决于所使用的量化和预测方法之间的相互作用。一般预测器和量化器在设计中独立进行。预测器在设计中认为量化器没有误差。而量化器在设计中则需要最小化自身误差。
预测器:
预测器的选择要满足两个要求:
- 使均方预测误差最小,即
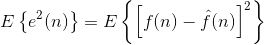
- 约束条件:
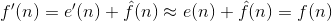
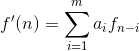
常用的几种线性预测方案
- 前值预测:
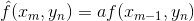
- 一维预测:
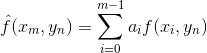
- 二维预测:
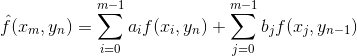
- 三维预测:也叫帧间预测,主要用于视频压缩。
变换编码:基于图像变换的编码方法,称为频域方法;用可逆的线性变换(如傅里叶变换)将图像映射成1组变换系数,然后将这些系数量化和编码。大多数图像变换得到的系数值很小,这些系数可以较粗地量化或者忽略不计。虽然失真很小,信息仍然不能完全复原,所以还是有损压缩。
图像变换通常是一种二维正交变换,常用的变换编码所使用的正交变换有离散傅里叶变换(DFT)、离散余弦变换(DCT)和沃尔什-哈达马变换(WHT)。
变换后图像能量更加集中,在量化和编码时,结合人类视觉心理因素等,采用“区域取样”或“阈值取样”等方法,保留变换系数中幅值较大的元素,进行量化编码,而大多数幅值小或某些特定区域的变换系数将全部当做0处理 。

流程解析:
- 子图像分解
将一幅大小为MxN的输入图像分解成nxn的子图像。
原因:a.距离远的像素之间的相关性比较差;
b.小块图像的变换比较容易。 - 正交变换
将一幅图像从空间域映射到变换域的系数集合。
特点:a.不会丢失信息;
b.去除部分相关性;
c.能量(信息)集中,大的系数能量多低频,小的系数能量少高频; - 量化
系数选择(滤波):区域法和阈值法
量化:小数系数变成整数 - 编码
变长编码法
(五)JPEG 压缩
5.1 JPEG
JPEG是联合图象专家组(Joint Picture Expert Group)的英文缩写,是国际标准化组织(ISO)和CCITT联合制定的静态图象的压缩编码标准。JPEG比其它几种压缩比要高得多,而图象质量都差不多,JPEG处理的颜色只有真彩和灰度图。
JPEG有两种基本的压缩算法、两种熵编码方法、四种编码模式。
压缩算法:
- 有损的离散余弦变换DCT(Discrete Cosine Transform)
- 无损的预测压缩技术;
熵编码方法:
- Huffman编码;
- 算术编码;
编码模式:
- 基于DCT的顺序模式:编码、解码通过一次扫描完成;
- 基于DCT的渐进模式:编码、解码需要多次扫描完成,扫描效果由粗到精,逐级递增;
- 无损模式:基于DPCM,保证解码后完全精确恢复到原图像采样值;
- 层次模式:图像在多个空间分辨率中进行编码,可以根据需要只对低分辨率数据做解码,放弃高分辨率信息;
在实际应用中,JPEG图像编码算法使用的大多是离散余弦变换、Huffman编码、顺序编码模式。这样的方式,被人们称为JPEG的基本系统。基本系统的JPEG压缩编码算法一共分为11个步骤:颜色模式转换、采样、分块、离散余弦变换(DCT)、Zigzag 扫描排序、量化、DC系数的差分脉冲调制编码、DC系数的中间格式计算、AC系数的游程长度编码、AC系数的中间格式计算、熵编码。
注意:
- JPEG的图片使用的是YCrCb颜色模型,而不是计算机上最常用的RGB,YCrCb颜色模型更适合图像压缩。因为人眼对图片上的亮度Y的变化远比色度C的变化敏感。
- 常用的采样格式有4:1:1和1:1:1
4:1:1采样指对于一个2x2像素的数据块,取4个亮度Y样本,1个红色差Cr样本,1个蓝色差Cb样本。
1:1:1采样就是保留所有的YCrCb值,相当于每个像素点用1个Y样本、1个Cr样本,1个Cb样本表示。 - DCT要求输入数据是一个8x8的矩阵,且每个矩阵元素具有8bit精度。
- 为了达到压缩数据的目的,DCT系数需要进行量化。量化的目的是减少非0系数的幅度以及增加0值系数的数目,将信号幅值由连续量变成离散量,在一定的主观保真的前提下,丢掉那些对视觉效果影响不大的信息。量化是图像质量下降的最主要原因。
5.2 JPEG 2000
虽然JPEG标准是一个非常成功的标准,但在一些新的应用如高清图像、数字图书馆、高精确彩色图像、多媒体和因特网应用、无线、医学图像等方面,JPEG表现不足,因此弥补JPEG对连续色调静止图像的无损压缩和近无损压缩效率不高的缺陷,最终提出了JPEG2000标准。
该标准采用了先进的压缩技术并在可伸缩压缩图像及灵活性方面有许多先进的特征,其系统功能比JPEG标准优越,尤其是JPEG2000采用的是离散小波变换替代了JPEG中采用的离散余弦变换,并采用了最新的编码算法来支持灵活性,这样许多应用只需要单一码流提供。JPEG2000可广泛应用于通信、图像处理、信号处理和多媒体 等领域中。
性能特点:
- 高压缩率
压缩性能比JPEG提高30~50%,同时,使用JPEG2000的系统稳定性好,运行平稳,抗干扰性好,易于操作。 - 同时支持有损和无损压缩
JPEG只支持有损压缩,而JPEG2000能支持无损压缩。在实际应用中,诸如卫星遥感图像、医学图像、文物照片等重要的图像都非常适用于采用JPEG2000压缩。 - 实现了渐进传输
这是JPEG2000一个及其重要的特征,它可以先传输图像的轮廓,然后逐步传输数据,不断提高图像质量,让图像由朦胧到清晰展示,而不必像现在的JPEG那样,由上到下慢慢显示,这在网络传输中有重大意义。 - 支持感兴趣区域
用户可以任意指定图像上感兴趣区域的研所质量,还可以选择指定的部分先解压缩,从而使重点突出。这种方法的优点在于它结合了接收方对压缩的主观要求,实现了交互式压缩。
关键技术:
JPEG2000与传统JPEG最大的不同在于它放弃了JPEG所采用的以离散余弦为主的区块编码方式,转而采用以小波变换为主的多解析编码方式。
余弦变换是经典的谱分析工具,它考察的是整个时域过程的频域特征或整个频域过程的时域特征,因此对于平稳过程,它有很好的效果,但对于非平稳过程,它却有诸多不足。图像的压缩率越高,频域信息被丢弃的越多。
小波变换是现代谱分析工具,它既能考察局部时域过程的频域特征,又能考察局部频域过程的时域特征,因此即使对于非平稳过程,处理起来也得心应手。它能将图像变换为一系列小波系数,这些系数可以被高效压缩和存储。此外,小波的粗略边缘可以更好的表现图像,因为它消除了DCT压缩普遍具有的方块效应。通过伸缩平移运算对信号逐步进行多尺度细化,最终达到高频处时间细分,低频处频率细分,能自动适应时频信号分析的要求,从而可聚焦到信号的任意细节。
(六)视频压缩
视频压缩课本已经讲解的很详细了,暂时没有补充,下面是书本上的内容,可以根据自身需求观看。
视频是图像序列,称为视频帧, 其中的每一帧都是单色或彩色图像。在这一节,我们介绍可以用来增加压缩的冗余,这些压缩通过 独立处理就可以达到。这些冗余又称为时间冗余,这是因为相邻帧的像素间相关。
在接下来的内容中,我们介绍视频压缩的基础知识和主要的图像处理工具箱函数,函数 用于处理图像序列,这些序列无论是基于时间的视频序列还是基于空间的视频序列,就像在 磁共振成像中产生的图像序列。然而在继续之前,我们注意到,在我们的例子中使用的非压 缩视频序列以多帧 TIFF 文件存储。多帧 TIFF 可以保存图像序列,可以使用下面的 imread 语法一次一个地读取:
imread('filename.tif', idx)
其中,idx 是读入序列中帧的整数索引,为了把非压缩帧写入多帧 TIFF 文件中, 相应的imwrite语法是:
imwrite(f, 'filename', 'Compression', 'none’,...'WriteMode', mode)
其中,当写入初始帧时 mode 置为 ‘Overwrite’,当写入所有的其他帧时置为‘append’。注意,与 imread 不同,imwrite 对多顿 TIFF 文件不提供随机访问支持,中贞 必须以它们产生的顺序写入。
6.1 MATLAB图像序列和电影
有两种标准的方法用来在 MATLAB 工作空间中描述视频。第一种,也是最简单的一种, 视频的每一帧都沿着 4 维数组的第 4 维连接起来。结果数组被称为 MATLAB 图像序列,并且 结果数组的头两维是连接帧的行维数和列维数。第3 维对于单色图像(或索引)是 1,对于彩色图 像是3。 第4维是图像序列的帧数。这样,下边的指令•shuttle.tif•将读取 16帧的多帧TIFF 文件的第一帧和最后一帧,并建立两帧的 256x480x1x2的单色图像序列 si:
i=imread('D:\数字图像处理\第八章学习\shuttle.tif');
frames = size(imfinfo('D:\数字图像处理\第八章学习\shuttle.tif'), 1);
s1 = uint8(zeros([size(i) 1 2]));
s1(:,:,:,1) = i;
s1(:,:,:,2)=imread('D:\数字图像处理\第八章学习\shuttle.tif',frames);
size(s1)
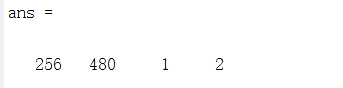
在 MATLAB 工作空间中描述视频的另一种方法是把连续的视频帧插入到称为电影帧的结 构矩阵中。得到的一行矩阵中叫做MATLAB电影的每一列均是结构,其中包括cdata和colormap 字段,前者用于保存视频的帧,就像uintS类的二维或三维矩阵那样;后者包含标准的MATLAB 彩色查找表。下边的指令把图像序列 si 变换为 MATLAB电影 ml:
i=imread('D:\数字图像处理\第八章学习\shuttle.tif');
frames = size(imfinfo('D:\数字图像处理\第八章学习\shuttle.tif'), 1);
s1 = uint8(zeros([size(i) 1 2]));
lut = 0:1/255:1;
lut = [lut' lut' lut'];
ml(1) = im2frame(s1(:,:,:,1),lut);
ml(2) = im2frame(s1(:,:,:,2),lut);
size(ml)
ml(1)
正如我们将要看到的那样,电影ml是1x2矩阵,其中的元素是包含256x480像素大小的uint8 图像和256x3的查找表。查表lut 是1:1 的灰度映射。最后,取一幅图像和彩色查找表作为参数 的函数 im2frame 用于建立每个电影巾贞。无论给定的视频序歹 ! j表示为标准的 MATLAB 电影还是 MATLAB图像序列,它们都可以用implay函数来观看(放映、暂停、单步等等)。
implay(frms, fps)
其中,frms 是 MATLAB电影或图像序列,fps是回放的帧率选项(帧每秒)。默认的帧率 是 20 倾/秒。多帧可以用 montage 函数同时观看:
montage(frms, ’Indices', idxes, 'Size‘ , [rows cols])
为了在多帧TIFF 文件和 MATLAB图像序列之间进换,可以使用:
`
s = tifs2seq(‘filename.tif’)
和
seq2tifs(s,‘filename.tif’)
其中,s 是 MATLAB图像序列,'filename.tif’是多帧 TIFF 文件。为了对 MATLAB 电影执行类似的变换,可以使用:
m = tifs2movie('filename.tif ’ )
和
movie2tifs(m, ‘filename.tif’)
其中, m 是 MATLAB电影。最后,为了把多帧TIFF 文件转换为 AVI 文件,以便使用 Windows 媒体播放器进行播放。可以与 MATLAB函数 movie2avi 协同使用 tifs2movie:
movie2avi(tifs2movie(’filename.tif ‘), filename.avi’)
其中,‘filename.tif’ 是多顿 TIFF 文件, 'filename.avi’是产生的 AVI 文件名。为了在工具箱电影播放器上观看多帧TIFF 文件,可以将 tifs2movie 与函数 implay结合使用:
implay(tifs2movie(‘filename.tif’))
6.2 时间冗余和运动补偿
类似空间冗余,它缘于空间中彼此接近的像素间的相关,时间冗余缘于时间上彼此接近的 像素的相关。正如在下边的例子中将要看到的那样,这个例子与 9.3 节中的例 9.5 并列,两种冗 余都以很多相同的方法访问。
例8.10 时间冗余
图 8-19⑻显示了多帧 TIFF 文件中的两帧,它们的第一帧和最后一帧已在图 8-18中描述, 正如 8.2 节和8.3 节中说明的那样,存在于传统的8比特帧描述中的空间和编码冗余可以使用霍夫曼编码和线性预测编码移除:
f2=imread('D:\数字图像处理\第八章学习\shuttle.tif',2);
ntrop(f2)

e2 = mat2lpc(f2);
ntrop(e2, 512)

c2 = mat2huff(e2);
>> imratio (f2, c2)

当使用 mat2huff 对预测值和真实值之间的差值进行编码时,函数 mat21pc 从它们前一 个直接相邻的(空间)像素预测 f2 中的像素值。预测和差值处理可得到 1.753:1 的 压 缩 比。因 为 f2 是图像中时间序列的一部分,所以可以从前一帧的相应像素来预测图像的像素。使用一阶线性预测器:
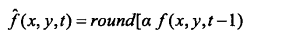
使用a=1和霍夫曼编码产生的误差如下:
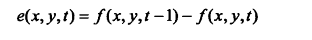
我们得到:
f1=imread('D:\数字图像处理\第八章学习\shuttle.tif',1);
ne2 = double(f2) - double(f1);
ntrop(ne2,512)
nc2 = mat2huff(ne2);
imratio (f2, nc2)

使用帧间预测器,而不是使用之前面向空间的像素预测器,压缩比增加到 2.5756。在任何 一种情况下,压缩是无损的,并且归因于如下事实:预测的残留熵(对于 e2 是 4.4537位/像素, 对于 ne2 是 3.0267 位/像素)低于帧 f2 的熵,为 6,8440位/像素。注意,预测残留 ne2 的直方 图显示在图 8-19(b)中,在 0附近是高峰,并且有相对较小的方差,使得变长霍夫曼编码是理想 的。
增加最大帧间预测的准确性的一种方法是解决帧和帧之间的目标运动——一种被称为运动补偿的处理方法。正如预期的那样,运动估计是运动补偿的关键。在运动估计中,测量每个宏块的运动,并 将它们编码为运动矢量。矢量是依据关联的宏块像素和参考帧中预测像素间的误差最小来选择。 最常用的误差测量方法之一是计算绝对失真的和(SAD):