利用HttpClient-Post去爬取数据
1、网络爬虫方法简述:
其实网络爬虫就跟我们人用浏览器去访问一个网页套路是一样的,都是分为四个部分:
- 打开浏览器:创建HttpClient对象。
- 输入网址:创建发起Post请求,创建HttpPost对象。
- 按回车:发起请求,返回响应,使用httpClient发送请求。
- 解析响应获取请求:判断状态码是否是200,如果为200就是访问成功了。
- 最后关闭response和httpClient
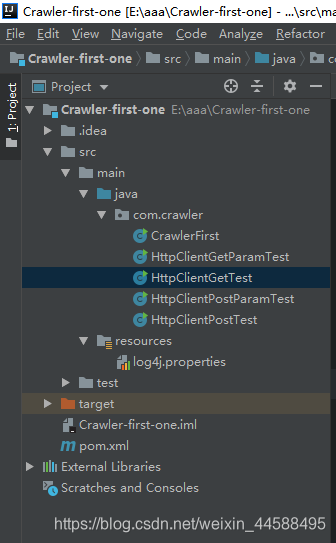
2、该项目的目录结构
如何创建项目请看:https://blog.csdn.net/weixin_44588495/article/details/90580722
3、不带参数去爬取数据
package com.crawler;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class HttpClientPostTest {
public static void main(String[] args) throws Exception {
//1、打开浏览器,创建HttpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
//2、输入网址,创建发起Get请求,创建HttpGet对象
HttpPost httpPost = new HttpPost("http://www.itcast.cn");
CloseableHttpResponse response = null;
try {
//3、按回车,发起请求,返回响应,使用httpClient发送请求
response = httpClient.execute(httpPost);
//4、解析响应获取请求,判断状态码是否是200
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity httpEntity = response.getEntity();
String content = EntityUtils.toString(httpEntity,"utf-8");
System.out.println(content.length());
}
} catch (IOException e) {
e.printStackTrace();
}
response.close();
httpClient.close();
}
}
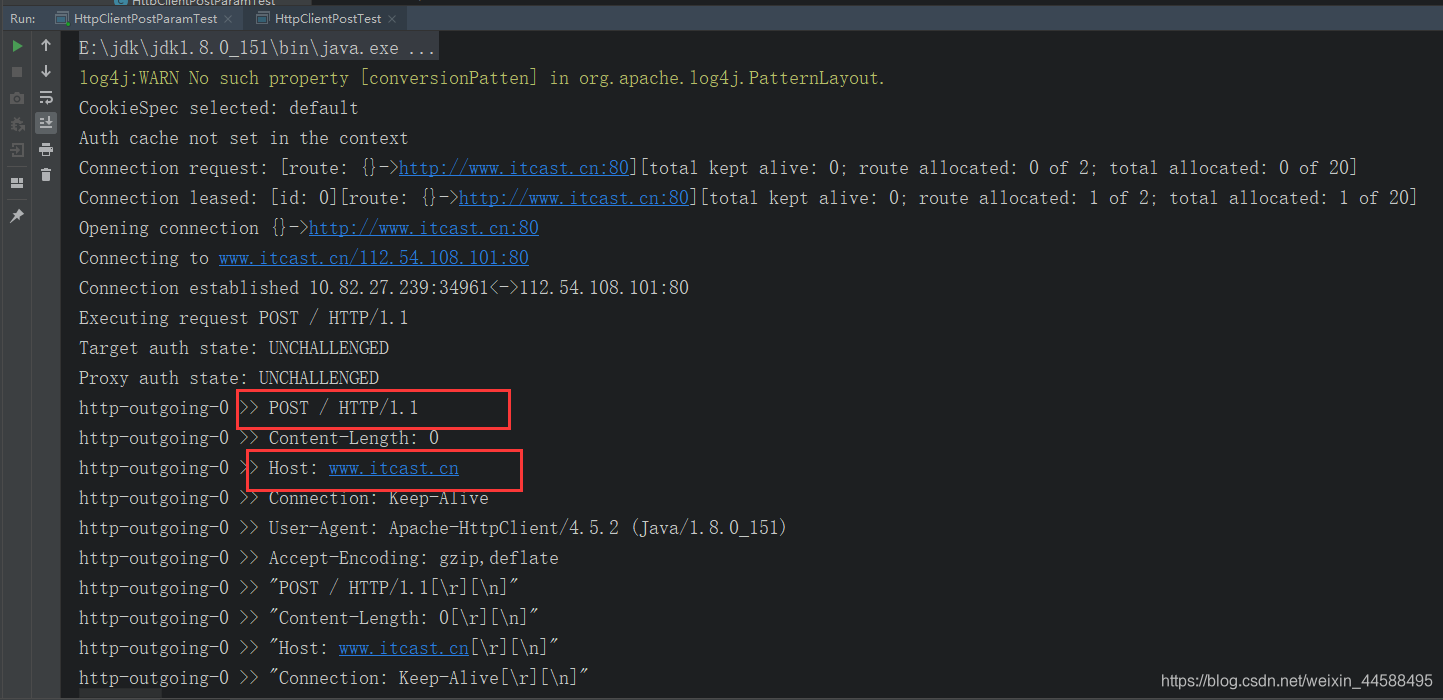
运行结果:
4、带参数去爬取数据
由于Post请求像Get请求那样在地址栏中表示,所以需要用一个List去装参数。还需要创建一个表单对象,将参数放入表单对象中,然后再将表单对象添加到HttpPost对象中。
package com.crawler;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class HttpClientPostParamTest {
public static void main(String[] args) throws Exception {
//1、打开浏览器,创建HttpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
//2、输入网址,创建发起Get请求,创建HttpGet对象
HttpPost httpPost = new HttpPost("http://yun.itheima.com/course");
//3、声明List集合,封装表单中的参数
List<NameValuePair> params = new ArrayList<NameValuePair>();
//设置请求地址是:http://yun.itheima.com/course?keys=java
params.add(new BasicNameValuePair("keys","java"));
//创建表单的Emtity对象,第一个参数是封装好的表单数据,第二个参数是编码
UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(params,"utf-8");
//设置表单中的Emptity对象到Post请求中
httpPost.setEntity(formEntity);
CloseableHttpResponse response = null;
try {
//3、按回车,发起请求,返回响应,使用httpClient发送请求
response = httpClient.execute(httpPost);
//4、解析响应获取请求,判断状态码是否是200
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity httpEntity = response.getEntity();
String content = EntityUtils.toString(httpEntity,"utf-8");
System.out.println(content.length());
}
} catch (IOException e) {
e.printStackTrace();
}
response.close();
httpClient.close();
}
}
运行结果:
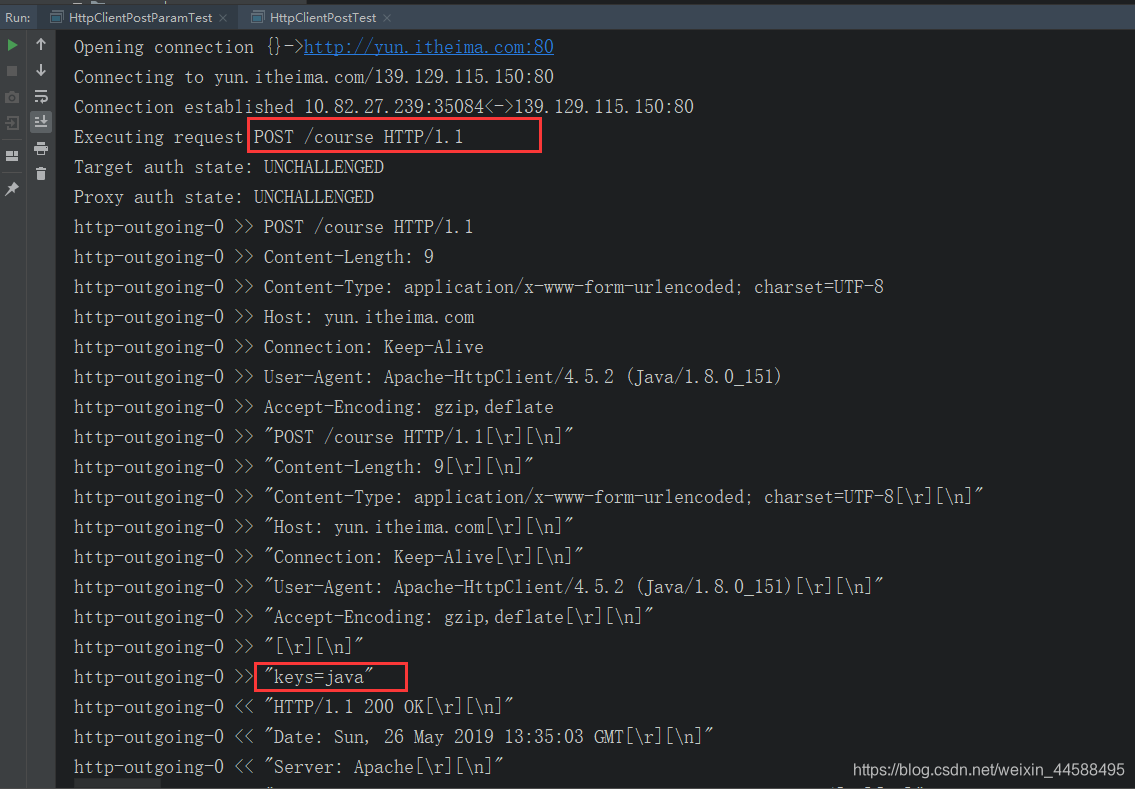
温馨提示:这次输出的爬虫数据与上一篇文章不同,输出的是爬取数据的长度。