自己对大数据的一个理解
大数据可以概括为5个V
- 数据量大(Volume):(大量的)
- 速度快(Velocity): (迅速)
- 类型多 (Variety):(多样,种类)
- 价值 (Value):(价值)
- 真实性(Veracity):(诚实,老实,真实)
大数据作为时下最火热的IT行业的词汇,随之而来的数据仓库、数据安全、数据分析、数据挖掘、等等围绕着大数据的商业价值的利用逐渐成为行业人士争相追捧的利润焦点。随着大数据时代的来临,大数据分析也应运而生。
为了解决数据量过大的问题有有两个方案
6. 垂直扩展:垂直扩展用白话文来说就是在自己的电脑上一直加内存或者在自己的虚拟机上一直加内存,但是你的电脑总会有装满的时候,所有就有了横向扩展。
7. 横向扩展:横向扩展其实就是多台服务器,连接起来。
大数据的始祖
谷歌三大论文
- MapReduce《分布式计算模型》
- Google FS《分布式文件系统》
- BigTable
分布式文件系统HDFS体系结构如下图
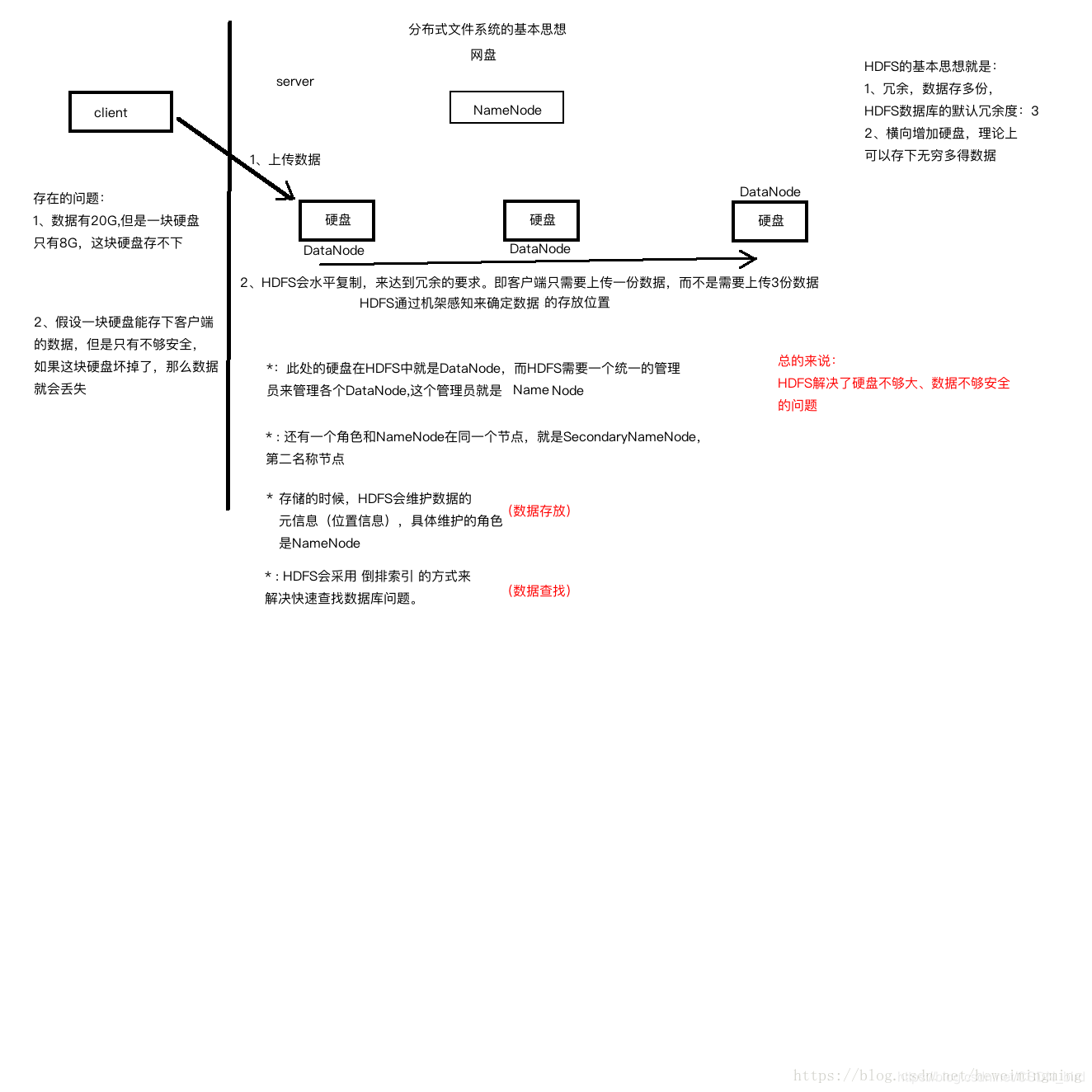
说起这个分布式文件系统就不得不说Hadoop了。
Hadoop官网的链接
Hadoop生态圈
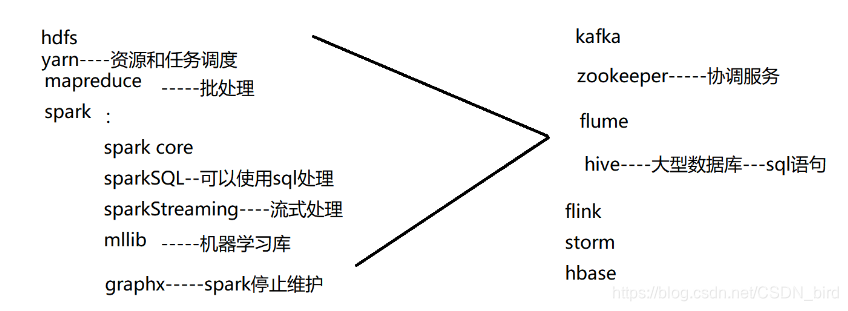
hadoop的主从架构(master/slave)
一个集群是由多态服务器组成的,一个集群只能有一个主节点
主节点就是NameNode,可以有多个从结点,从结点就是DataNode
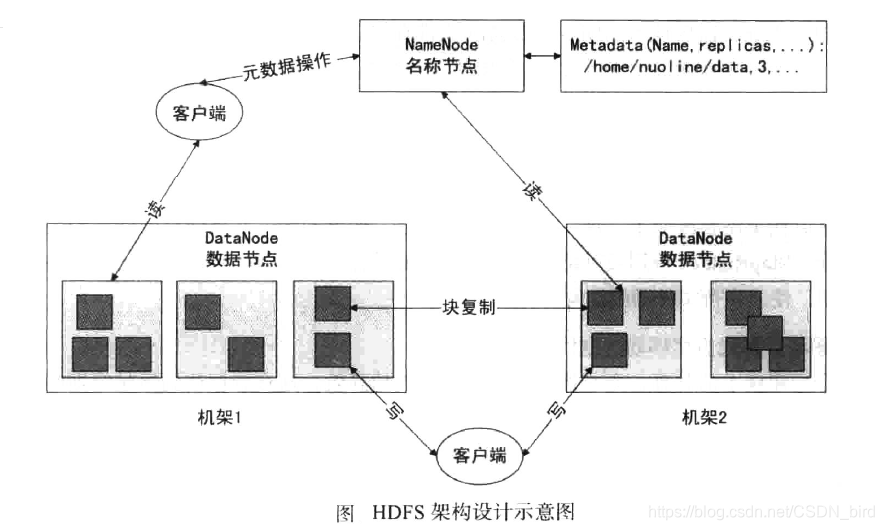
图中展示了HDFS的NameNode、DataNode以及客户端之间的存取访问关系,单一节点的NameNode大大简化了系统的架构。NameNode负责保存和管理所有的HDFS元数据,因而用户数据就不需要通过NameNode,也就是说文件数据的读写是直接在DataNode上进行的。HDFS存储的文件都被分割成固定大小的Block,在创建Block的时候,NameNode服务器会给每个Block分配一个唯一不变的Block标识。DataNode服务器把Block以Linux文件的形式保存在本地硬盘上,并且根据指定的Block标识和字节范围来读写块数据。出于可靠性的考虑,每个块都会复制到多个DataNode服务器上。在默认情况下,HDFS使用三个冗余备份,当然用户可以为不同的文件命名空间设定不同的复制因子数。NameNode管理所有的文件系统元数据。这些元数据包括名称空间、访问控制信息、文件和Block的映射信息,以及当前Block的位置信息。NameNode还管理着系统范围内的活动,比如,Block租用管理、孤立Block的回收,以及Block在DataNode服务器之间的迁移。NameNode使信息周期性地和每个DataNode服务器通信,发送指令到各个DataNode服务器并接收DataNode中Block的状态信息。
HDFS客户端代码以库的形式被链接到客户程序中。在客户端代码中需要实现HDFS文件系统的API接口函数,应用程序与NameNode和DataNode服务器通信,以及对数据进行读写操作。客户端和NameNode的通信只获取元数据,所有的数据操作都是由客户端直接和DataNode服务器进行交互的。HDFS不提供POSIX标准的API功能,因此,HDFS API调用不需要深入到Linux vnode级别。无论是客户端还是DataNode服务器都不需要缓存文件数据。客户端缓存数据几乎没有什么用处,因为大部分程序要么以流的方式读取一个巨大的文件,要么工作集太大根本无法被缓存。因此,无须考虑与缓存相关的问题,同时也简化了客户端及整个系统的设计和实现。
元数据与源数据的差别
直白一点 ,源数据就是你所拥有的数据,
元数据是能生成其他数据的基本数据,也可以说元数据就是解释你的源数据的数据,
例:name=张三
张三是一个源数据 而name就是元数据··
大文件的存储方式
一般是由客户端分割成block块放在服务器上
Block块
block块大小为什么是128M?
磁盘寻址时间:10ms左右
I/O速率:100M/s
要让文件的寻址时间不会占用太多的文件读写时间,通常是1%;10ms*100 = 1s;所以让文件块的大小在100M左右,100M转换为二进制就是128M

Block概念:
磁盘有默认的数据块大小,它是磁盘读/写数据的最小单位。构建在这样的磁盘上的文件系统也是通过磁盘块来管理该文件系统中的块,该文件系统块的大小可以是磁盘块的整数倍。文件系统块一般为几千字节,磁盘块一般为512字节。对于用户来讲对文件的访问/存取都是透明的,同样系统管理员可以利用系统本身的命令对数据块进行相关操作。
HDFS也有一个块(Block)的概念,不但是大得多,默认为128MB。和一般的文件系统不同的是:虽然块设置得比较大,但是当一个文件的大小小于HDFS的块大小时,实际存储所占的大小并不占用一个块的大小(例如,当一个1MB的文件存储在一个128MB的块中时,文件只使用1MB的磁盘空间,而不是128M)。
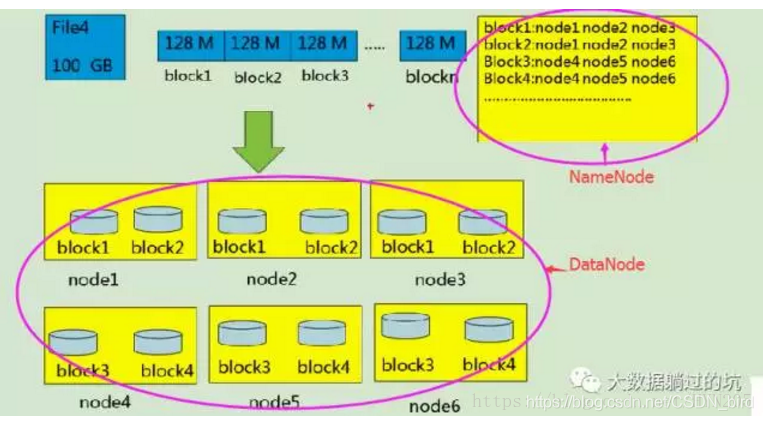
hadoop1.x的默认块大小是为64Mb,hadoop2.x的默认块大小是为128Mb,
block是存放在哪里的
NameNode中有block的映射,真正的的数据是在DataNode中的,
元数据是存在NameNode里,同样不能简单地认为block就存放在DataNode里,
实际数据岑放在DataNode中的block里,block的映射在NameNode里,其实也有存储在
NameNode里的
以Block块形式将大文件进行存储
-
block分散处在集群结点中
-
单一文件的block大小一致,文件与文件之间可以不一致
例:在A文件中一个Block块的大小为128Mb,那么其他的Block块也是128Mb,
在B文件中Block块可以按着所用对对需求来分Block的大小。
Block可以设置副本数,副本分在在不同的节点中。 -
副本数不要超过结点数。
-
文件上传的时候是可以设置Block大小和副本数的
-
已经上传的Block副本数可以调整,大小不变。
-
只支持一次写入多次读取,同一时刻只有一个写入者。
备份机制
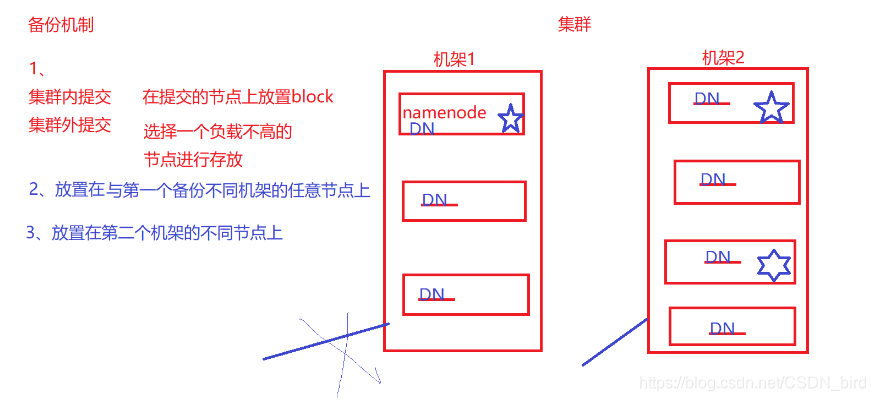
备份机制
- 集群内提交就是没有客户端做中间操作,NameNode可能会和DateName同时占用同一个节点, NameNode会在最近的节点上放置Block块的备份
- 集群外提交 就是客户端会选择一个负载不高的节点进行存放。标记星标的就是备份所存放的位置。
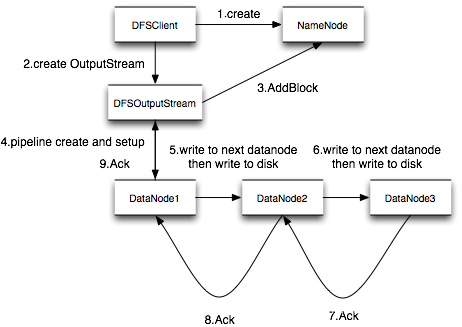
Pipeline管道
1.NameNode在返回给Client一些DataNode信息之后
CLIENT 会和这些DataName形成一个管道并且将Block块分割成一个个ackPackage(64KB)
DataNode会从管道中拿走相对应的数据进行存储,当存储完成之后,DataName会向NameNode进行汇报
(本文是由自己的知识整理 以及 借鉴的大牛讲解所完成 ,小弟初学大数据,有错请各位大牛进行指教,小弟在此感激不尽,各位看官看完之后可以一起讨论,一起学习,一起进步)