2.3 GoogLeNet (Inception)网络
GoogLeNet与VGGNet共同参加了2014年的ImageNet挑战赛,并以一定的优势获得冠军。GoogLeNet是由谷歌公司研究出来的深度学习网络结构,其最大的创新就是提出了Inception模块,所以2014年提出的GoogLeNet网络又称为Inception V1,后来谷歌公司又不断对其进行改进,先后又提出了V2、V3以及V4的改进版。Inception V1凭借其独有的Inception结构在控制参数量的同时又扩展了网络的深度,Inception V1网络的深度有22层,但是参数量却只有500万个,大大少于VGGNet的1亿3000万和AlexNet的6000万的参数量。尽管参数量少于其他的网络结构,但是其网络性能却更加优越,在ILSVRC2014挑战赛上取得了-top5错误率6.67%的好成绩。
2.3.1 Inception V1
提高网络性能最有用的方法就是增加网络的深度和宽度,所谓深度就是网络的层的数量,所谓宽度就是每层的神经元数量。但是直接增加网络的尺寸却会带来两个主要的缺点:1.网络参数过多容易产生过拟合现象,为了解决过拟合问题需要大量的数据,而高质量的训练数据获取成本太高;2.极大地增加网络的计算量,如果增大的计算量得不到充分的利用(比如大量的权值趋向于0),那么就会造成计算资源的浪费。
论文认为将全连接层占据了网络的大部分参数,很容易产生过拟合现象,所以作者去除了模型最后的全连接层,并将全连接层甚至一般的卷积层转换为稀疏连接来解决上述问题。稀疏连接是神经科学中的概念,即神经科学中每个细胞只对一个视觉区域内极小的一部分敏感,而对其他部分则可以视而不见的现象启发。相比于全连接层,卷积操作本身就是一种稀疏的结构。然而,当对非均匀稀疏数据结构计算时,计算效率非常低,需要在底层的计算库做优化,即使算术运算的数量减少了100倍,查找和缓存丢失的代价也会占主导地位。而大量的文献表明,将稀疏矩阵聚类成相对密集的子矩阵是稀疏矩阵乘法计算的一个良好实践方法。Inception结构试图逼近隐含在视觉网络中的稀疏结构,并利用密集、易实现的组件来实现这样的假设(隐含的稀疏结构)。同时论文还指出,尽管Inception这样的架构成功应用于计算机视觉中,但其性能的成功是否归结于网络结构的构成还需要探讨和验证。总之,Inception结构就是一种基于事实的既能利用密集矩阵的高计算性能,又能保证网络结构稀疏性的方法。
2.3.1.1 Inception架构细节
之前网络结构都是layer-by-layer的模式,Inception架构将前一层分解成不同的卷积单元,由于卷积操作的性质,这些单元只与前一层的某些区域有关(在靠近输入图像的层中,相关单元将会集中在图像的局部区域),然后再将这些单元聚类到一起,聚类后形成下一个单位,与上一个卷积层相连接,也就是利用卷积操作将相关性高的区域聚类到一起来逼近最佳局部稀疏结构。论文中将卷积核的尺寸限制在1*1,3*3,5*5是因为使用过大的卷积核会导致聚类的数目变少。此外,当设定卷积步长stride=1时,再将padding分别设置为0,1,2就可以保证上述卷积核的输出与输入层尺寸保持一致,这样便于不同卷积核输出特征的拼接。由于Pooling操作能够增强网络的性能,所以作者在Inception架构中也嵌入了Pooling层。同时,论文中还指出,随着网络层数的增加,层数更高的层提取的特征也越抽象,不同区域之间的相关性也会下降,所以3*3和5*5的卷积核在更深层的时候使用更多。下图展示了Inception架构的初始结构:
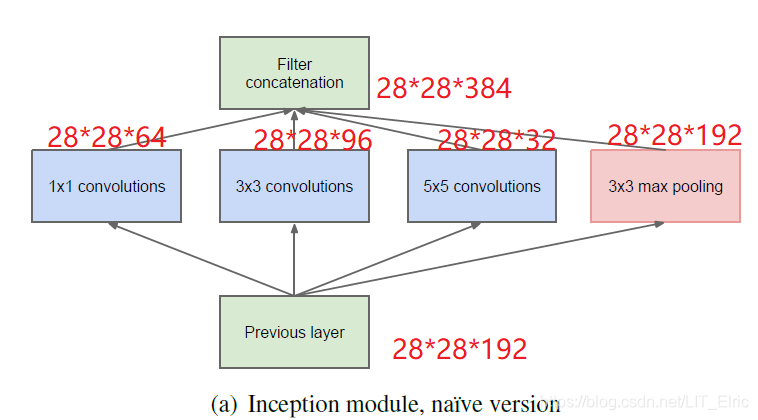
通过将1*1,3*3,5*5卷积层以及3*3最大池化层堆叠在一起,即能增加网络的宽度又能增加网络对尺度的对应性。使用不同尺度的卷积核和池化核能够提取前一层的不同特征信息,降低过拟合,提高模型性能。然而,采用上面的结构有一个问题,并且当pooling单元加入之后这个问题更加明显:由于Pooling层输出filters的数量等于上一步filters的数量,在最后叠加的时候会大大地增加filters的数量,随着网络结构的深化,到最后几层的时候filters的数量会越来越多。此外,使用5*5的卷积核依然会有不小的计算量。所以即使这个架构可能包含了最优的稀疏结构,还是会非常没有效率,导致计算没经过几步就崩溃。
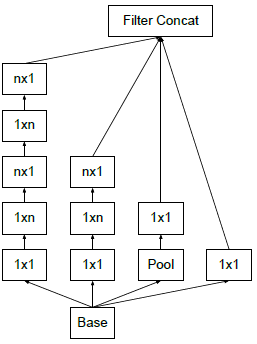
因此,文章引入了1*1的卷积核来进行数据降维。比如,上一层的输出为100*100*128,经过具有256个输出的5*5卷积层之后(stride=1,pad=2),输出数据为100*100*256。其中,卷积层的参数为128*5*5*256。假如上一层输出先经过具有32个输出的1*1卷积层,再经过具有256个输出的5*5卷积层,那么最终的输出数据仍为为100*100*256,但卷积参数量已经减少为128*1*1*32+32*5*5*256,大约减少了4倍。此外,引入1*1的卷积核还能够增加网络的非线性和网络的深度。改进版的Inception结构如下:

上图所示的Inception网络结构中,包含了3种不同尺寸的卷积核1个最大池化,增加网络对不同尺度的适应性。其中,1*1卷积核除了进行特征提取外,另一个最重要的作用是对输出通道进行升维或降维。Inception的4个分支最后通过一个聚合操作合并,构建出符合Hebbian原理的稀疏结构。在GoogLeNet中,作者就是通过堆叠这样的Inception结构拓宽加深网络结构,而又不至于参数过多产生过拟合。
2.3.1.2 GoogLeNet网络结构
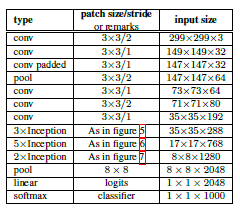
GoogLeNet共有22层深,在加入Inception架构之前,输入图像经过了3个卷积层和2个最大池化层来进行数据降维,同时在第2个卷积层和第2个最大池化层的输入还加入了一个LRN层。文中总共堆叠了9个Inception架构,在网络最后使用了平均池化层而不是全连接层,这种策略使得TOP1精度提高了0.6%。但是为了方便Finetune,作者还是在池化层后面接了一个全连接层,最后使用Softmax分类器用于分类的输出。需要注意的是,即使网络移除了全连接层,作者仍然使用Dropout技术防止过拟合现象。除了最后一层的输出,GoogleNet中间节点的输出效果也很好,因此作者引出网络中中间某一层的输出作为辅助分类节点,并给定一个较小的权重(占比为0.3)作用于最后的分类结果中,但在inference阶段,辅助分类器不使用。GoogLeNet的网络结构如下:
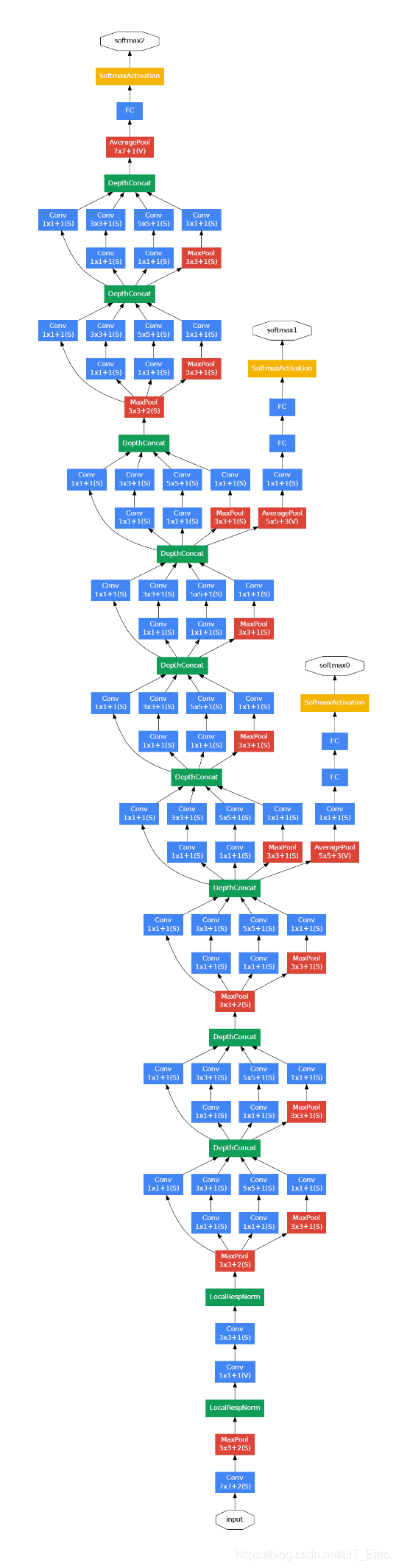
对于每一层的具体结构及输出尺寸如下,(但我感觉文中给出的参数量计算有点问题,网上搜了一圈也没有答案,有人说是第一层是1*7+7*1的卷积,然后再组合而成的7*7的卷积,其它层的数据量也有点小偏差,大家可以发表下自己的看法):

上表中的#3*3 reduce和 #5*5 reduce表示在进入3*3卷积层之前的数据通道数,特别的,对于Inception结构,就是指使用1*1卷积核的数量。除了GoogLeNet的主体结构,辅助分类器的结构参数如下:
-
平均池化层池化核的尺寸为5*5,步长为3,4a的输出为4*4*512,4d的输出为4*4*528
-
总共有128个1*1的卷积核参与卷积计算
-
全连接层共有1024个神经元用于线性激活
-
Dropout率设置为70%
-
使用softmax作为分类器(和主分类一样预测1000个类,但在inference时移除)
2.3.1.3 GoogLeNet实验效果
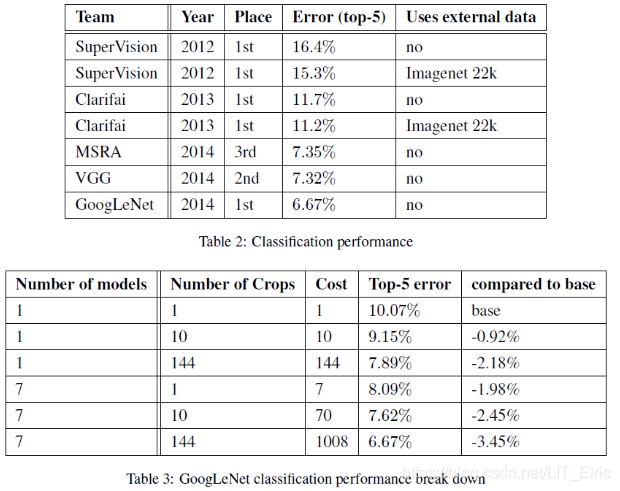
文中分别训练了7个模型,每个模型初始值相同,但模型的采样方法和输入图片的随机序列不同。在测试时,将图片短边resize到4个固定的S值(256,288,320,352),再根据最短边的数值裁剪resize后图像的上中下(或左中右)三个正方形区域,然后将正方形图像的5个区域(左上、右上、左下、右下、中央)和该正方形图像整体(共6张图片)resize到224*224同时再水平翻转一次作为网络输入。这样一张图片能够扩增为4*3*6*2=144张测试图片。将这些图片在softmax层做平均,获得最后的预测结果。
2.3.2 Inception V2
由于Inception V1在图像分类问题上取得了巨大的成功,GoogLeNet团队继续改进推出了InceptionV2结构。InceptionV2主要有两点创新,第一个是借鉴了VGGNet使用两个3*3的卷积核代替一个5*5的大卷积核,这样能够在不增加过多的计算量的同时提高网络的表达能力;另一个就是引入Batch Normalization来提高训练速度和分类准确率。
小卷积核的优点之前在VGGNet中提到过了,通过堆叠两个小的卷积核可以达到和大卷积核一样的感受野,并且能够进一步增加网络的非线性,提高网络性能。Batch Normalization方法的优点我们在上一篇博文里面已经详细介绍了,这里就不再进一步展开了。通过引入BN层能够设置较大的学习率,使得网络更快地收敛,同时还能够在一定程度上提高分类准确率。作者认为BN某种意义上起到了正则化的作用,可以有效减少过拟合,进而减少甚至取消Dropout层的使用,简化网络结构。所以作者在InceptionV2结构中使用了较大的学习率,取消了Dropout和LRN层并减轻了L2正则的影响,减少数据增强过程中对数据的光学畸变(BN训练更快,每个样本被训练的次数更少,因此真实的样本对训练更有帮助)。
2.3.3 Inception V3
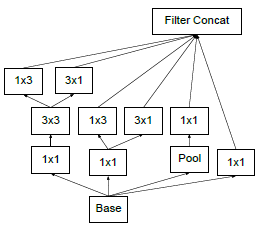
Inception V3进一步推进了Inception V2中小卷积核的思想,将3*3的卷积核拆分成了两个1*3和3*1的卷积核,使得网络结构变得更深。出来卷积核尺寸的改进之外,作者还对Inception网络结构提出了很多改进方案,包括加深网络层数一些通用性准则、优化辅助分类器、优化池化和优化标签等。目前官方提供的源码也是基于Inception V3的。
2.3.3.1 大尺寸卷积核分解
大的卷积核拥有更大的感受野,能够提取更多的局部特征,但同时越大的卷积核意味着更多的参数,更大的计算量。VGGNet中指出,大卷积核完全可以通过堆叠一系列3*3的卷积核来表达,并且不会造成表达能力的缺失甚至还能由于添加非线性激活提高网络性能。Inception V3更进一步,将3*3的卷积核分解成2个更小的卷积核来代替,如下图:
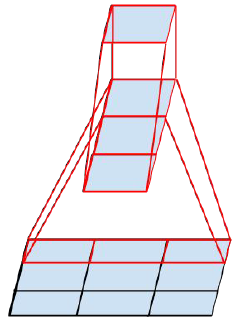
在实际过程中作者发现在网络的前期使用这种分解效果并不好,只有在feature map尺寸在一定范围内(m*m大小的feature
map,建立m在12到20之间)的情况下使用这种分解策略能使模型性能提高。Inception V3总共设计了包含Inception V1中的Inception在内的3种不同Inception结构,分别处理35*35,17*17和8*8的不同输入feature map尺寸。如下图:

2.3.3.2 通用网络结构设计准则
1.在网络靠前的地方不能过分压缩特征。一般而言,设计的分类网络结构呈漏斗状,feature map尺寸逐渐减少,维度逐渐增加。所以如果直接在网络第一层就使用一个11*11,stride=5的卷积核是不合适的。由于很多情况下是通过池化层来对特征图进行降采样,这样就会造成一定量的信息丢失,作者设计一种更复杂的池化来解决这个问题。
2.更多的特征更容易处理局部信息。高维特征更易区分,每个卷积层的通道数增加对处理局部信息是有好处的,能够加快训练。
3.可以在更深的较底层上压缩数据而不需要担心丢失很多信息。比如对于网络后面的feature maps上使用1*1的卷积核进行降维再进行3*3这样大卷积核的卷积计算,这样不但不会影响模型精度,反而还能加快其收敛速度。
4.平衡网络的宽度和深度。论文认为一个好的网路结构一定会在深度和宽度上都有增加,过宽或者过深的网络效果都不是很好。
2.3.3.3 辅助分类器优化
通过对比试验,作者发现辅助分类器在训练初期并不能加速收敛,只有当训练快结束时才会略微提高网络精度,所以作者在Inception V3中将Inception V1中的第一个辅助分类器去除了。
2.3.3.4 池化层优化
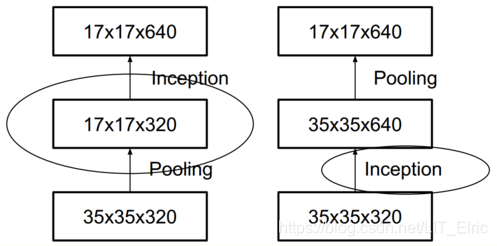
对于池化层降采样feature map,会不可避免的产生信息丢失,因此为了防止信息过度丢失,传统的优化方法要么是在进行池化之前使用1*1的小卷积核扩增feature map的filters数量,然后再进行池化降维,要么是再进行池化之后再使用1*1的卷积核扩增filters的数量。但这两种方法并不高效,会消耗一定的计算资源。对此,作者提出了他们的池化方法,即分别使用pool与conv来进降维再将这两个部分concatenate起来。至于这种方法的设计思路,论文中只字未提。下图左展示了一般的优化方法,图右展示了Inception V3的优化方法:

2.3.3.5 标签优化
到目前为止我们学习的标注标签都是one-hot类型向量(即一组由0,1表示的向量),但是作者认为这样的标注方式类似于控制工程中的脉冲信号,有可能会导致过拟合和网络适应性差的问题,其原因是“网络对它预测的东西太自信了”。所以,Inception V3使用Label Smoothing方法对标签进行处理,如下式:
其中 表示one-hot标签, 表示类别的个数的倒数, 是一个超参数。这样可以将one-hot的分布变得稍微平滑一点。Label smooth方法使得Inception V3网络精度提高了0.3%。
2.3.3.6 Inception V3示例源码
2.3.4 Inception V4
Inception V4借鉴了ResNet的结构,这里就不再展开讲了,有兴趣的同学可以自行去翻阅原论文。