2.2 VGGNet网络
VGG论文原文在这里。VGG是由Simonyan和Zisserman提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。VGG模型和之后提到的GoogleNet模型共同参加了2014年的ImageNet图像分类与定位挑战赛,尽管以0.6%的劣势惜败于GoogleNet,但是其着重于研究网络深度对模型性能的影响,并成功构筑了16-19层深的卷积神经网络,这使得分类错误率大幅下降(相比AlexNet错误率降低了一倍)并增强模型的泛化能力。到目前为止,依然有许多网络使用VGG来提取图像特征。VGGNet也是由卷积层和全连接层组成,可以看成是AlexNet的深化版,并且作者认为只使用3*3的小尺寸卷积核能够显著加深网络的深度。
2.2.1 VGGNet网络结构
在训练过程中,首先对输入图片固定到224*224大小,并对其去均值化(所以输入图片减去RGB的平均值)。为了验证不同卷积层深度对模型性能的影响,VGGNet采用块结构(Block)来构建网络,类似AlexNet,VGGNet中总共有5个Block和3个全连接层,每个Block中又含有若干个卷积层和一个池化层。作者总共测试了6种不同的网络结构的性能,深度从11层到19层不等,其中变化的仅仅是Block中卷积层的数量和卷积核尺寸。卷积层中采用卷积核尺寸均为3*3(有一种策略使用了1*1大小的卷积核,这样的卷积核不改变输入通道的维度且可以提高模型的学习能力),五个池化层皆为最大池化,并且池化核为2*2,步长为2。VGGNet具体网络结构如下所示,其中,convN表示使用N*N的卷积核:

以16层的VGG16为例,具体的卷积网络结构如下:
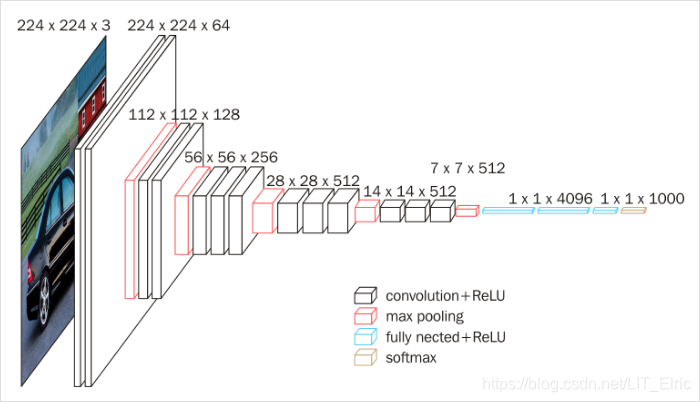
可以看到在VGGNet中,网络结构还是比较简洁的,就通过堆叠卷积层和池化层,最后再接3个全连接层,卷积层只负责提取特征而不改变输入的尺寸,尺寸降采样则是通过池化层来实现的,每通过一次最大池化层,输入尺寸减半。斯坦福的人工智能公开课上给出了VGG16网络的资源占用情况(没有考虑偏置值),如下:

蓝色的字体表示当前层参数的数量,红色的字体表示计算所需的显存容量。尽管网络层数不断加深,但A到E这六种网络结构的参数量变化却不是很大,这是因为大部分参数在后面的全连接层。VGG16有超过1亿的参数量,其拟合能力很强,但是也正是因为其参数量过多导致训练时间过长,调参难度大,并且VGG16的权重值存储文件大小为500多MB,不利于安装到嵌入式系统中。
2.2.2 VGGNet特点
- 小尺寸卷积核和更深的网络结构
相比于AlexNet中的5*5甚至11*11的卷积核,VGG使用了多个3*3的小尺寸卷积核卷积层堆叠来实现和大卷积核卷积层相同的感受野,作者在论文中认为使用2个3*3的卷积核相当于使用1个5*5的卷积核。。这样不仅能够减少参数量,由于卷积层输出前会经激活函数激活,因此相当于进行了更多的非线性映射,可以增加网络的学习能力。此外,论文中C结构还使用了1*1的卷积核,这也是为了增加决策函数的非线性而不影响卷积层的感受野。
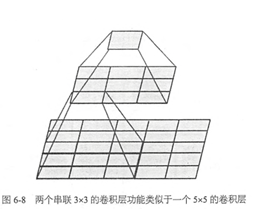
可以看到,最顶层的1*1输出是由最底层的5*5的输入提取出来的,经过两个3*3的卷积核,效果与一个5*5的大卷积核类似。在参数数量上,两个3*3的卷积核,有2*3*3=18参数,而一个5*5=25参数,可以看到参数量上也少了很多。
- 使用迁移学习来初始化权值
神经网络的权值初始化是非常重要的,因为由于深度网络中梯度的不稳定性不好的初始值会使学习陷入停滞。为了更好地初始化权值,作者先训练一个深度较浅的网络A,然后再利用训练好的网络A的权值来作为深度较深的网络的初始值。虽然和AlexNet相比,VGGNet的参数更多、深度更深,但是却收敛的更快。原因有两点,一是前面提到的更深的层和更小的卷积核相当于隐式的进行了正则化;二是在训练期间对某些层进行了预初始化。
- 多尺度训练和测试
在训练阶段,网络首先将输入图像进行缩放,使得最短边的尺寸缩放至S(S>=224),然后再对缩放后的图像进行采样crop至224*224。对于S的大小,论文中讨论了两种方案。第一种是使用固定的值,作者评估了两个S大小的模型,S=256和S=384。对于S=384,先是训练一个S=256的模型,再利用S=256的模型权值初始化S=384的模型权值来训练S=384的模型。第二种使用变长的输入尺寸S,随机在S=[Smin,Smax]中取值进行训练。
在测试阶段,同样将输入图像进行缩放,使得最短边的尺寸缩放至Q。Q不需要与S相同,然后使用两种不同的方式进行分类:dense evaluation和multi-crop evaluation,这两种方式分别借鉴于Overfeat和GoogleNet。下面分别介绍这两种方式:
1. dense evaluation
由于训练网络输入图像是224x224x3,如果后面三个层都是全连接,那么在测试阶段就只能将测试的图像全部都要缩放大小到224x224x3,才能符合后面全连接层的输入数量要求,这样就不便于测试工作的开展。Dense evaluation是将最后三层全连接层改成了卷积层来实现对任意输入图像的测试的。对于训练网络而言,假设最后一层卷积层的输出是m*m的C个通道的feature map,那么在进入全连接层之前,需要将其展开成一个m*m*C的一维向量再与全连接层相连接。在VGG中,它将全连接层看成是一个卷积核大小为m*m,通道数为第一个全连接层神经元个数n1的卷积层,这样得到的输出大小是1*1*n1,效果与全连接层一样。然后对于第二个全连接层,可以看成是大小为1*1,通道数为第二个全连接层神经元个数n2的卷积层;同理第三个全连接层也可做类似改变成卷积层。如下图:
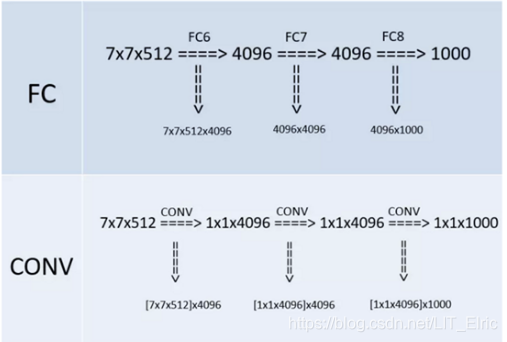
将全连接换成卷积后,则可以来处理任意分辨率(在整张图)上计算卷积,这就是无需对原图做重新缩放处理的优势。
2. multi-crop evaluation
Multi-crop策略首先将图像缩放到3种不同的尺寸(纵横比不变),对于得到的每个尺寸图像,取四个顶点加中心五个位置的正方形图像(边长就是最短边的长度。对于纵向图像来说,则取上、中、下三个位置),因此每个尺寸的图像得到3个正方形图像;然后再在每个正方形图像的4个crop顶点和中心位置处crop出224*224大小的图像,因此每个正方形图像得到6个224*224大小的图像;最后,再将所有得到的224*224的图像水平翻转。因此,每个图像可以得到3*5*5*2=150个224*224大小的图像。将这些图像分别输入神经网络进行分类,最后取平均,作为这个图像最终的分类结果。
2.2.3 VGGNet实验效果
作者对这六种网络结构进行了评估,具体的可以参考原文,这里只贴出但尺度评估的效果,即取固定的Q;
 )
)
可以看出:
1、LRN层对网络性能提升不大
作者通过网络A-LRN发现,AlexNet曾经用到的LRN层(local response normalization,局部响应归一化)并没有带来性能的提升,因此在其它组的网络中均没再出现LRN层。
2、随着深度增加,分类性能逐渐提高(A、B、C、D、E)
从11层的A到19层的E,网络深度增加对top1和top5的错误率下降很明显。
3、多个小卷积核比单个大卷积核性能好(B)
作者做了实验用B和自己一个不在实验组里的较浅网络比较,较浅网络用conv5*5来代替B的两个conv3*3,结果显示多个小卷积核比单个大卷积核效果要好。
2.2.4 实现代码
参考文献
[1] VGG16学习笔记
[2]TensorFlow实战:Chapter-4(CNN-2-经典卷积神经网络(AlexNet、VGGNet))
[3] VGGNet