期望目的
基于VMware workstation 10.0 + CentOS 7 + hadoop 3.2.0,在虚拟机上搭建一套Hadoop集群环境,总共包含4个节点,其中1个master节点、3个slave节点。
操作过程
步骤一 创建虚拟机、安装系统
需提前在计算机上安装好VMware workstation 10,下载好CentOS 7的镜像文件。具体步骤不再赘述,这里讲几个安装系统过程中需要注意的地方:
- 选择最小化安装
- 默认网络是关闭的无法上网,安装时设置网络打开
- Vmware Tools没必要安装
- 记住设置的root用户密码和创建的账户、密码
如果安装时没有打开网络,可以安装系统完毕之后手动打开:
#编辑网卡配置文件 vi /etc/sysconfig/network-scripts/ifcfg-ens33
在配置文件中增加或修改一项ONBOOT="yes",顾名思义,开机启动网卡。然后重启网络服务:
service network restart
步骤二 配置宿主主机通过SecureCRT登录到虚拟机
Vmware里虚拟机间、虚拟机与宿主间切换实在太麻烦,这里借助SecureCRT通过SSH登录到虚拟机,这样操作就舒服多了。
配置也很简单,网上找个SecureCRT绿色版,装在宿主计算机上,创建新Session,协议默认SSH2就行,Hostname填要连接的虚拟机IP,连接时输入账户、密码就能登录到虚拟机上了。
步骤三 基础配置
- 创建用于操作hadoop内容的用户hadoop_user
#切换成root用户
su
#创建用户
useradd hadoop_user
#为hadoop_user用户设置密码
passwd hadoop_user - 安装JDK
2.1 拷贝、解压jdk
本来想直接在虚拟机中通过wget下载jdk的,无奈Oracle现在下载jdk时必须登录,只得作罢。
这里选择用宿主计算机下载好jdk,然后通过SecureFX发送jdk压缩包到虚拟机中。
2.2 为jdk添加环境变量#切换成root用户 su #创建放jdk的目录 mkdir /opt/software/jdk/ #解压jdk到刚创建的目录 tar zxvf /home/zhq/jdk-8u211-linux-x64.tar.gz -C /opt/software/jdk/ #将jdk执行文件所在目录添加到环境变量 vi /etc/profile
在profile文件末尾添加以下语句后保存、退出export JAVA_HOME=/opt/software/jdk/jdk1.8.0_211 export PATH=$PATH:$JAVA_HOME/bin#使环境变量配置生效 source /etc/profile #将JDK目录所属用户改为hadoop_user,以便之后使用 chown hadoop_user:hadoop_user /opt/software/jdk/
- 安装net-tools
由于我们采用的是最小化安装,有一些常用的工具系统里并没有,这里我们手动安装他们。
su yum install -y net-tools
- 配置Hostname和Hosts
设置Hostname为master
hostnamectl set-hostname master
配置Hosts(其中slave1、slave2、salve3三台主机当前并不存在,我们按VMware虚拟IP地址递增的规则预估这三台的IP,步骤五进行完后如发现IP有出入再回到这里做相应调整)
在hosts文件末尾添加以下内容:#编辑hosts文件 su vi /etc/hosts
192.168.212.132 master 192.168.212.133 slave1 192.168.212.134 slave2 192.168.212.135 slave3
步骤四 Hadoop配置
- 安装hadoop
1.1 拷贝、解压hadoop
还是使用SecureFX将hadoop压缩包发送虚拟机master中。发送完毕之后在虚拟机中执行如下操作:1.2 为hadoop添加环境变量#切换成root用户 su #创建放hadoop的目录 mkdir /opt/software/hadoop/ #解压jdk到刚创建的目录 tar zxvf /home/zhq/hadoop-3.2.0.tar.gz -C /opt/software/hadoop/ #将jdk执行文件所在目录添加到环境变量 vi /etc/profile
在profile文件末尾添加以下语句后保存、退出export HADOOP_HOME=/opt/software/hadoop/hadoop-3.2.0 export PATH=$PATH:$HADOOP_HOME/bin
#使环境变量配置生效 source /etc/profile #将hadoop目录所属用户改为hadoop_user,以便之后使用 chown hadoop_user:hadoop_user /opt/software/hadoop/
-
配置hadoop环境参数
注意,master作为namenode,有些datanode才需要的配置项本可以不用配,但为了后面拷贝虚拟机时不用挨个集群节点修改,这里冗余写上了,冗余部分姑且用斜体标识。
2.1 在hadoop-env.sh和yarn_env.sh中配置JAVA_HOME
在以上两个文件末尾添加如下代码:export JAVA_HOME=/opt/software/jdk/jdk1.8.0_211
2.2 编辑core-site.xml,在配置中添加如下配置项以指定集群使用的文件系统为hdfs,namenode为master。
<property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property>
2.3 编辑hdfs-site.xml,在配置中添加如下配置项以指定hdfs的存储副本数为2,namenode的相关文件存储路径为/hdfs_storage/name/,datanode的本地文件存储路径为/hdfs_storage/data/(ps: 这里用到的目录记得提前手动创建出来)。
<property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/hdfs_storage/name/</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/hdfs_storage/data/</value> </property>
2.4 编辑mapred-site.xml,在配置中添加如下配置项以指定执行mapreduce作业的使用的框架为yarn,作业历史访问地址为master:10020,作业历史webapp地址为master:19888。
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jophistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jophistory.webapp.address</name> <value>master:19888</value> </property>
2.5 编辑yarn-site.xml,在配置中加入如下配置项以指定yarn的资源管理器地址为master:8032,资源管理器的调度器地址为master:8030,资源管理器的资源追踪器地址为master:8031,资源管理器的管理员地址为master:8033,资源管理器的webapp访问地址为master:8088,MapReduce程序使用的混洗服务为mapreduce_shuffle。
<property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
步骤五 克隆出集群中的其余主机
这里我们借助VMware的克隆虚拟机的功能,在master的基础上克隆出slave1、slave2、slave3。
步骤六 配置ssh免密登录
- 生成rsa秘钥对
以hadoop_user身份登录到master,在/home/hadoop_user/中创建.ssh目录并创建出密钥对:
cd /home/hadoop_user/ #创建.ssh目录 mkdir .ssh cd .ssh #创建rsa加密的ssh密钥对 ssh-keygen -t rsa #一路回车后,在.ssh目录下会创建一对秘钥文件id_rsa和id_rsa.pub。 - 将公钥拷贝到slave1,并添加到信任公钥
在master中操作如下:
scp id_rsa.pub hadoop_user@slave1:/home/hadoop_user/ #输入slave1中的hadoop_user用户的密码后,拷贝成功
在slave1中操作如下:
cd /home/hadoop_user/ mkdir .ssh #将master的公钥添加到自己的信任列表 cat id_rsa.pub >> .ssh/authorized_keys #调整文件权限 chmod 700 .ssh chmod 600 .ssh/authorized_keys
- 测试是否可以免密登录
在master中输入 ssh slave1 如果不需要输入密码即可登入slave1说明成功,否则检查是否有遗漏步骤。
- 重复2、3,以实现免密登入到其余主机
步骤七 验证环境搭建结果
- 格式化HDFS
第一次使用前必须先格式化一次hdfs,成功后方可启动各个守护进程。格式化方式如下:
bin/hdfs namenode -format
无报错信息的话则格式化成功。
- 启动HDFS
执行以下命令启动hdfs:
sbin/start-hdfs.sh与其对应的停止命令为
sbin/stop-hdfs.sh启动命令执行无报错的话,可执行 jps 命令查看java进程,master中会出现NameNode和SecondaryNameNode两个进程,各个slave节点中会出现DataNode进程。
- 启动YARN
执行以下命令启动yarn:sbin/start_yarn.sh与其对应的停止命令为
sbin/stop-yarn.sh启动命令执行无报错的话,可执行jps命令查看java进程,master中会出现ResourceManager进程,各个slave节点中会出现NodeManager进程。
步骤八 防火墙配置
上面配置里配了好几个端口号,默认情况下centos防火墙是打开的,这里我们需要配置一下防火墙打开上面这些端口号,不然会访问不到对应的web页面。命令如下:
firewall-cmd --zone=public --add-port=8030/tcp --permanent firewall-cmd --zone=public --add-port=8031/tcp --permanent firewall-cmd --zone=public --add-port=8032/tcp --permanent firewall-cmd --zone=public --add-port=8033/tcp --permanent firewall-cmd --zone=public --add-port=8088/tcp --permanent firewall-cmd --zone=public --add-port=10020/tcp --permanent firewall-cmd --zone=public --add-port=19888/tcp --permanent firewall-cmd --reload
执行完毕后,在浏览器中访问master:8088访问到集群信息界面就OK了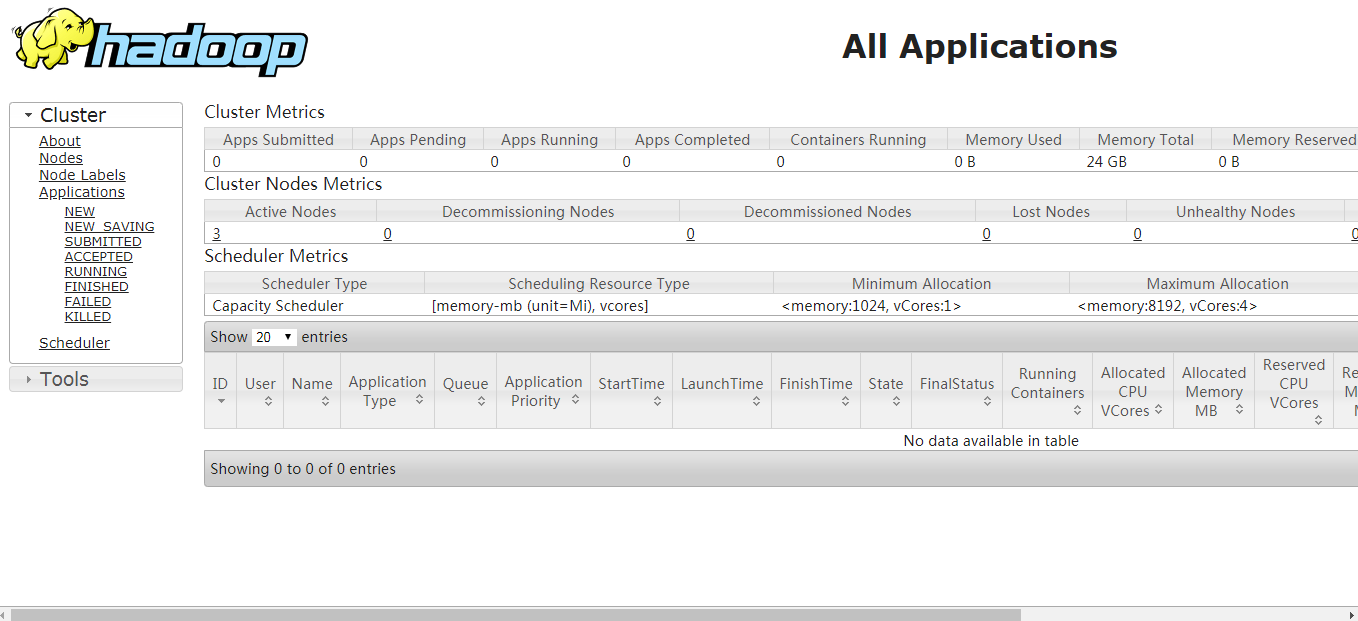
总结
经过以上八步之后,一个全分布式的hadoop集群搭建完毕!最后,附上hadoop官网的配置链接https://hadoop.apache.org/docs/r3.2.0/hadoop-project-dist/hadoop-common/ClusterSetup.html,英语能力还可以的话建议去官网学习。