为什么字符串要编码呢?
因为计算机只能处理数字,最底层的CPU只能识别0和1。所以字符串就需要编码成对应的数字。
在计算机中,最开始只有ASCII,我们开始接触计算机编程时就学了ASCII码。最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,如大写字母A的编码是65,小写字母a的编码是97。
但是对于其他语言,比如中文、韩文等等,ASCII码就没法表示了,比如,对于中文字符,一个字节(8位)显然是不够的。因此,各个国家制定了各自的编码,比如中国的GB2312编码,韩国的Euc-kr编码,这些编码只适应于各国语言,这样就带来一个编码不统一的问题,显示别国语言可能会乱码。于是后来有了Unicode,所谓万国码。Unicode把所有语言都统一到一套编码里,解决了乱码问题。
ASCII码与Unicode编码的区别在于前者用一个字节表示一个字符,后者用至少两个字节,比如字母A用ASCII编码是十进制的65,二进制的01000001,而用Unicode编码是二进制的00000000 01000001。对于这种字符,显然用Unicode编码造成了存储空间的浪费。于是,后来出现了utf-8编码,这种编码的原则是能用多少表示就是用多少表示(即高字节的全0直接去掉,节省存储空间),如字母A用utf-8编码是01000001。
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本等进行编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
在Python2中我们通常在脚本的前端会加上:
# -*- coding:utf8 -*-
指定编码方式,告诉Python解释器,按照utf-8编码读取源代码。这样就能显示中文字符。如果不加这行,显示中文时会报错:
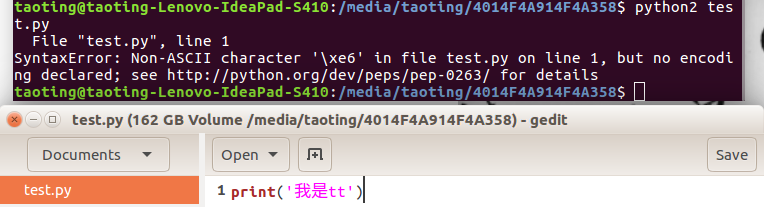

而在交互式命令中则可以直接显示:

在Python3中,则不需要指定,因为Python3中字符串是以Unicode编码的,支持中文显示。


Python中字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。要在网络传输或者保存到磁盘的话,就需要转化成bytes。Python中bytes类型用带b前缀的单引号或双引号表示:string1 =b'test'。
转化方式:encode()方法:'test'.encode('ascii') ---> b'test';'中文'.encode('utf-8') --> b'\xe4\xb8\xad\xe6\x96\x87'。
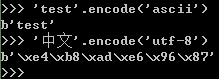
从这里也可以看出,utf-8中3个字节表示一个中文字符,1个字节表示一个英文字符。
相反地,我们从磁盘读取的字节流是bytes,那么转化成str的方式是decode()方法:b'HTG'.decode('ascii') ---> 'HTG';b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') ---> '中文'

字符串的格式化
我们经常要输出字符串,里面包含常量也包含变量,那么如何进行格式化,使得两者可以一起进行输出呢?
字符串的格式化就是用来格式化字符串变量。
两种方式:
1.用%,%s表示用字符串替换,%d表示用整数替换,%f表示用浮点数替换,%x表示用十六进制整数替换
例:'This is an %s example!' % 'simple';'This is the %s %s example!' % ('second','simple')。注意多个变量时要加括号;要输出%时用%%表示。

2.用.format(),将一个字符串中的占位符替换为指定的值。
