1. 项目背景
a. 每个系统都有日志,当系统出现问题时,需要通过日志解决问题
b. 当系统机器比较少时,登陆到服务器上查看即可满足
c. 当系统机器规模巨大,登陆到机器上查看几乎不现实
2. 解决方案
a. 把机器上的日志实时收集,统一的存储到中心系统
b. 然后再对这些日志建立索引,通过搜索即可以找到对应日志
c. 通过提供界面友好的web界面,通过web即可以完成日志搜索
3. 面临的问题
a. 实时日志量非常大,每天几十亿条
b. 日志准实时收集,延迟控制在分钟级别
c. 能够水平可扩展
4. 业界方案ELK
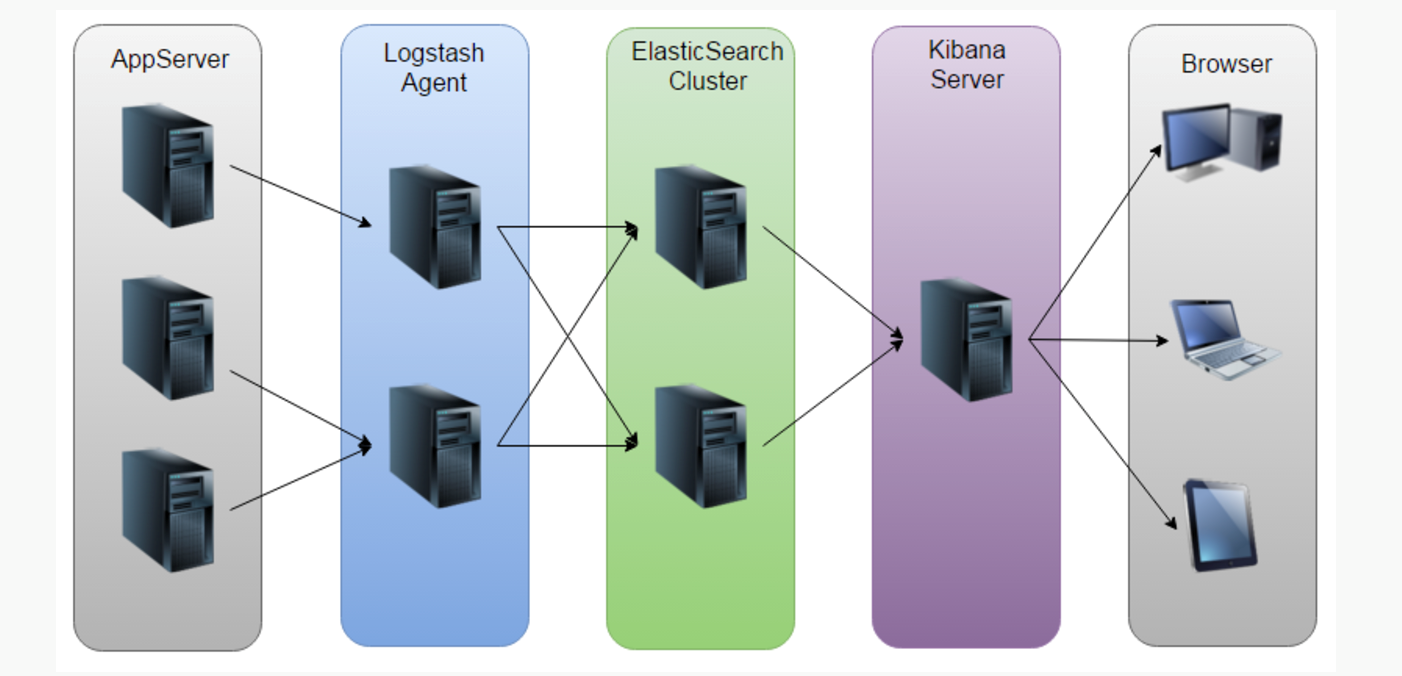
5. elk方案问题
a. 运维成本高,每增加一个日志收集,都需要手动修改配置
b. 监控缺失,无法准确获取logstash的状态
c. 无法做定制化开发以及维护
6. 日志收集系统设计
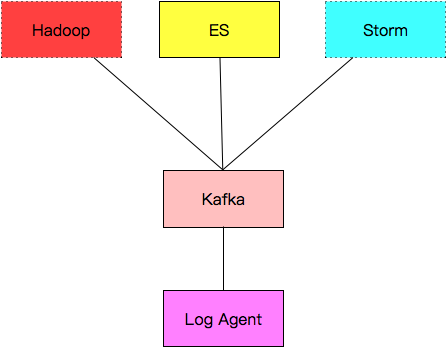
7. 各组件介绍
// a. Log Agent,日志收集客户端,用来收集服务器上的日志(部署在每个需要收集日志的业务服务器上) // b. Kafka,高吞吐量的分布式队列,linkin开发,apache顶级开源项目 // c. ES,elasticsearch,开源的搜索引擎,提供基于http restful的web接口 // d. Hadoop,分布式计算框架,能够对大量数据进行分布式处理的平台 (小量数据用 mysql 就行,海量数据利用 Hadoop ) // e. Storm ,实时计算框架(数据流从Storm流过就能计算出来) // f. zookeeper,分布式的存储系统,可用于服务注册和服务发现,也可用作配置中心和分布式锁(kafka所有的配置也都写在zookeeper中)
7.1 kafka 应用场景:
- 异步处理,把非关键流程异步化,提高系统的响应时间和健壮性
- 应用解耦,通过消息队列
- 流量削峰
7.2 zookeeper应用场景
- 服务注册 & 服务发现
- 配置中心
- 分布式锁
- Zookeeper是强一致的
- 多个客户端同时在Zookeeper上创建相同znode,只有一个创建成功