前言
自从上一篇博客详细讲解了Python遗传和进化算法工具箱及其在带约束的单目标函数值优化中的应用之后,我经过不断学习工具箱的官方文档以及对源码的研究,逐步更加地掌握如何利用遗传算法求解更多有趣的问题了。
首先简单回顾一下Python高性能实用型遗传和进化算法工具箱的用法。对于一个优化问题,需要做两个步骤便可进行求解:Step1:自定义问题类;Step2:编写执行脚本调用Geatpy进化算法模板对问题进行求解。在上一篇博客曾“详细”介绍过具体的用法:https://blog.csdn.net/weixin_37790882/article/details/84034956,但完整的中文教程可以参考官方文档。
下面切入主题:
本文的“最短路径问题”专指图的最短路径问题,而且只研究单目标的最短路径问题。(实际上最短路径问题还可以是多目标的),参考用书推荐:《网络模型与多目标遗传算法》。这本书我已经上传到此处,可以直接下载到:
https://download.csdn.net/download/weixin_37790882/11700202
图的最短路径问题从广义上说其实有很多种类型,比如:
- 确定起点和终点的有向图和无向图的最短路径问题。
- 旅行商最短路径问题。
- 车辆配送中的最短路径问题。
- 物流中心选址的最短路径问题。
其中确定起点和终点的无向图的最短路径问题可以延伸为机器人路径规划问题。也就是说,机器人避开障碍物从起点走向终点的那种路径规划问题本质上是一种复杂一些的“确定起点和终点的无向图的最短路径问题”。
本文主要讲解如何利用遗传算法求解“确定起点和终点的有向图最短路径问题”。对于无向图的,另外再写博客以机器人路径规划作为案例来展开叙述。
正文
问题举例:
以《网络模型与多目标遗传算法》一书中的一个小案例为例,如图所示,当从结点1驶向结点10时,我们经常会考虑怎样选择路径使得花最短的距离达到目的地。此时不需要像旅行商问题(TSP)那样,此类问题不需要要求所有的地点都访问一遍,而只需要想办法用最短的距离从起点走到终点即可。


书中讲述了两种遗传算法编码方式对上述问题进行求解。
法一:
利用二进制编码。假设 Xij 是有向图中所有边的一个集合,那么其中一种可行的路径对应的染色体可以是:
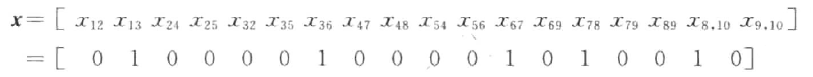
其中元素为1表示对应的边被“激活”,即最终路径上包含这条边。于是上面的染色体所代表的路径为:1 → 3 → 6 → 7 → 8 → 10。
这种编码方式最为直观,但有个很大的弊端:在进化过程中染色体往往无法表达一个合法的路径。于是这种情况下需要给遗传算法添加很多约束,此时便增加了遗传算法寻优的难度。
法二:
利用“基于优先级编码”。这种编码方式是Gen & Lin 在2005年提出的有利于很好地求解图的路径规划问题的编码方法。参考文献:(Lin L, Gen M. Priority-Based Genetic Algorithm for Shortest Path Routing Problem in OSPF[M]// Intelligent and Evolutionary Systems. 2009.)这篇文献可能比较难下载到,我将其上传到这里了,可以直接下载查看:
https://download.csdn.net/download/weixin_37790882/11699834
下面来详细讲解这种编码方式:
“基于优先级编码”是一种间接编码方式,这意味着染色体并不能直接表示路径,此时需要利用额外的数据来进行解码,解码后才表示一个路径。这种编码方式有个特点是染色体的每一位上的元素是互不相等的,这意味着这种编码方式具备“排列编码”的特征。(排列编码即比如从1到10的10个数中随机挑选若干个数组成的一个排列。)
以一条染色体为例,看看“基于优先级编码”的染色体是如何表示有向图中的一条路径的:

上面这条染色体是遗传算法中随机生成的(并非最优),结点优先级并不是指结点的访问先后顺序,而是结点的优先级,是给后面解码用的。
解码需要一个集合nodes,用于存储以各结点为起点的有向边的终点,即各个结点下一步可达的结点。本题的集合nodes为:nodes = [[], [2,3], [3,4,5], [5,6], [7,8], [4,6], [7,9], [8,9], [9,10], [10]]。因为python中列表的下标是从0数起的,而本题的结点是从1数起的,为了能直接对应,故上面的nodes的第0号元素设置为[],表示无意义。解析一下nodes的组成:第1号元素是[2,3],表示题目的有向图中1号结点下一步可达的结点是2和3。nodes的第2号元素是[3,4,5],表示2号结点下一步可达的结点是3,4,5。以此类推。
于是上面的染色体[7, 3, 4, 6, 2, 5, 8, 10, 1, 9]的详细解码过程如下:
从1号结点出发,在nodes中下标为1的元素是[2,3],表示1号结点下一步可以去2号结点或3号结点。此时从染色体中找到这两个结点对应的优先级分别为3和4,如图所示:

从中选出具有更高优先级的结点3作为结点1下一步需要访问的结点。
紧接着,在nodes中下标为3的元素是[5,6],表示3号结点下一步可以去5号或6号结点。此时从染色体中找到这两个结点对应的优先级分别为2和5,如图所示:

从中选出具有更高优先级的结点6作为结点1下一步需要访问的结点。
以此类推,最终得到完整的访问路径为:
1 → 3 → 6 → 7 → 8 → 10。
有了解码得到路径,如何求个体的适应度?
想要求个体的适应度,首先要定一个优化目标。本题是要让路径最短,于是我们便要根据访问结点求出路径长度,把这个作为优化目标。有了优化目标,便可利用基于目标函数值排序的适应度分配(ranking)求出适应度值。当然,这类单目标优化问题也可以直接让个体的适应度等于优化目标函数值(即路径长度)。而路径长度即为访问路径上各条有向边的权值之和。
代码实现:
首先编写问题类,把待优化模型写在问题类中。然后编写执行脚本,调用“soea_SEGA_templet“(增强精英保留的遗传算法模板)进行进化优化。该算法模板的源码及算法流程详见:
https://github.com/geatpy-dev/geatpy/blob/master/geatpy/templates/soeas/GA/SEGA/soea_SEGA_templet.py
由于本题比较简单,故用4个个体、10代的进化即可得到很好的结果。完整的实验代码如下:
# -*- coding: utf-8 -*-
import numpy as np
import geatpy as ea
class MyProblem(ea.Problem): # 继承Problem父类
def __init__(self):
name = 'Shortest_Path' # 初始化name(函数名称,可以随意设置)
M = 1 # 初始化M(目标维数)
maxormins = [1] # 初始化maxormins(目标最小最大化标记列表,1:最小化该目标;-1:最大化该目标)
Dim = 10 # 初始化Dim(决策变量维数)
varTypes = [1] * Dim # 初始化varTypes(决策变量的类型,元素为0表示对应的变量是连续的;1表示是离散的)
lb = [0] * Dim # 决策变量下界
ub = [9] * Dim # 决策变量上界
lbin = [1] * Dim # 决策变量下边界
ubin = [1] * Dim # 决策变量上边界
# 调用父类构造方法完成实例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)
# 设置每一个结点下一步可达的结点(结点从1开始数,因此列表nodes的第0号元素设为空列表表示无意义)
self.nodes = [[], [2,3], [3,4,5], [5,6], [7,8], [4,6], [7,9], [8,9], [9,10], [10]]
# 设置有向图中各条边的权重
self.weights = {'(1, 2)':36, '(1, 3)':27, '(2, 4)':18, '(2, 5)':20, '(2, 3)':13, '(3, 5)':12, '(3, 6)':23,
'(4, 7)':11, '(4, 8)':32, '(5, 4)':16, '(5, 6)':30, '(6, 7)':12, '(6, 9)':38, '(7, 8)':20,
'(7, 9)':32, '(8, 9)':15, '(8, 10)':24, '(9, 10)':13}
def decode(self, priority): # 将优先级编码的染色体解码得到一条从节点1到节点10的可行路径
edges = [] # 存储边
path = [1] # 结点1是路径起点
while not path[-1] == 10: # 开始从起点走到终点
currentNode = path[-1] # 得到当前所在的结点编号
nextNodes = self.nodes[currentNode] # 获取下一步可达的结点组成的列表
if len(nextNodes) == 0:
raise RuntimeError("Error in decode: No way to go. (当前结点出度为0,无路可走。)")
chooseNode = nextNodes[np.argmax(priority[np.array(nextNodes) - 1])] # 从NextNodes中选择优先级更高的结点作为下一步要访问的结点,因为结点从1数起,而下标从0数起,因此要减去1
path.append(chooseNode)
edges.append((currentNode, chooseNode))
return path, edges
def aimFunc(self, pop): # 目标函数
pop.ObjV = np.zeros((pop.sizes, 1)) # 初始化ObjV
for i in range(pop.sizes):
priority = pop.Phen[i, :]
path, edges = self.decode(priority) # 将优先级编码的染色体解码得到访问路径及经过的边
pathLen = 0
for edge in edges:
key = str(edge) # 根据路径得到键值,以便根据键值找到路径对应的长度
if not key in self.weights:
raise RuntimeError("Error in aimFunc: The path is invalid. (当前路径是无效的。)", path)
pathLen += self.weights[key] # 将该段路径长度加入
pop.ObjV[i] = pathLen # 计算目标函数值,赋值给pop种群对象的ObjV属性
if __name__ == "__main__":
problem = MyProblem() # 生成问题对象
"""=================================种群设置================================="""
Encoding = 'P' # 编码方式
NIND = 4 # 种群规模
Field = ea.crtfld(Encoding, problem.varTypes, problem.ranges, problem.borders) # 创建区域描述器
population = ea.Population(Encoding, Field, NIND) # 实例化种群对象(此时种群还没被初始化,仅仅是完成种群对象的实例化)
"""===============================算法参数设置==============================="""
myAlgorithm = ea.soea_SEGA_templet(problem, population) # 实例化一个算法模板对象
myAlgorithm.MAXGEN = 10 # 最大进化代数
myAlgorithm.recOper = ea.Xovox(XOVR = 0.8) # 设置交叉算子
myAlgorithm.mutOper = ea.Mutinv(Pm = 0.1) # 设置变异算子
myAlgorithm.drawing = 1 # 设置绘图方式(0:不绘图;1:绘制结果图;2:绘制过程动画)
"""==========================调用算法模板进行种群进化=========================="""
[population, obj_trace, var_trace] = myAlgorithm.run() # 执行算法模板,得到最后一代种群以及进化记录器
population.save() # 把最后一代种群的信息保存到文件中
# 输出结果
best_gen = np.argmin(obj_trace[:, 1]) # 记录最优种群是在哪一代
best_ObjV = np.min(obj_trace[:, 1])
print('最短路程为:%s'%(best_ObjV))
print('最佳路线为:')
best_journey, edges = problem.decode(var_trace[best_gen, :])
for i in range(len(best_journey)):
print(int(best_journey[i]), end = ' ')
print()
print('有效进化代数:%s'%(obj_trace.shape[0]))
print('最优的一代是第 %s 代'%(best_gen + 1))
print('评价次数:%s'%(myAlgorithm.evalsNum))
print('时间已过 %s 秒'%(myAlgorithm.passTime))
运行结果如下:

在有向图中表现为:

后记
值得注意的是:上面题目中的有向图并不存在回路,实际上,复杂的有向图往往会存在许多回路,此时需要进行一定的处理来避免陷入回路当中,即避免一直在回路上“打转”。处理方式有很多,例如在解码过程中对已经访问过的结点的有限度进行惩罚等等。这里暂时就不深入探讨了,待之后讲述无向图最短路径及机器人寻路问题时再展开叙述。
最后回顾一下上一篇博客提到的”遗传算法套路“:

该套路实现了具体问题、使用的算法以及所调用的相关算子之间的脱耦。而Geatpy工具箱已经内置了众多进化算法模板类以及相关的算子,直接调用即可。对于实际问题的求解,只需关心如何把问题写在自定义问题类中就好了。
更多详细的教程可以详见:http://geatpy.com/index.php/geatpy%E6%95%99%E7%A8%8B/
后续我将继续学习和挖掘该工具箱的更多深入的用法。希望这篇文章在帮助自己记录学习点滴之余,也能帮助大家!
