str 和 unicode
以下摘自《Effective Python》
python3有两种表示字符序列的类型:bytes 和 str。前者的实例包含原始的8位值;后者的实例包含Unicode字符。
python2中也有两种表示字符序列的类型,分别叫做 str 和 unicode 。与 python3 不同的是,str 的实例包含原始的8位值,而 unicode 的实例,则包含 Unicode 字符。
下图辅助理解。
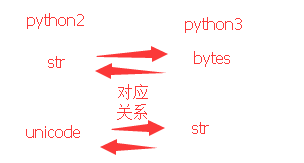


以下可复制:
def to_unicode(unicode_or_str):
if isinstance(unicode_or_str, str):
value = unicode_or_str.decode('utf-8')
else:
value = unicode_or_str
return value # Instance of unicode
def to_str(unicode_or_str):
if isinstance(unicode_or_str, unicode):
value = unicode_or_str.encode('utf-8')
else:
value = unicode_or_str
return value # Instance of str
示例:解决Python2.7无法输出中文的问题
对比示例:
json_all = getExampleData(args)
for key in json_all.keys():
curlogger.info(to_str(key)) # 使用 to_str,将 unicode 转换成 str
curlogger.info(json_all.keys()) # 不转换成 str,直接输出 unicode
输出log:
2019-12-21 21:36:46,871 - INFO: json_all.keys() = axisclass
2019-12-21 21:36:46,871 - INFO: json_all.keys() = 中文示例
2019-12-21 21:36:46,871 - INFO: json_all.keys() = timeseries
2019-12-21 21:36:46,875 - INFO: ['axisclass', u'\u4ed3\u5355\u6a61\u80f6', 'timeseries']
这样可以正常解码 unicode 字符,方便查看log
