1.准备工作
1.1 安装配置NTP
官方建议在所有 Ceph 节点上安装 NTP 服务(特别是 Ceph Monitor 节点),以免因时钟漂移导致故障。
ln -sf /usr/share/zoneinfo/posix/Asia/Shanghai /etc/localtime
yum -y install ntpd
systemctl enable ntpd
vim /etc/ntp.conf
server 0.cn.pool.ntp.org
systemctl stop ntpd
ntpdate 0.cn.pool.ntp.org
systemctl restart ntpd
hwclock --systohc1.2 创建 Ceph 部署用户
ceph-deploy 工具必须以普通用户登录 Ceph 节点,且此用户拥有无密码使用 sudo 的权限,因为它需要在安装软件及配置文件的过程中,不必输入密码。官方建议所有 Ceph 节点上给 ceph-deploy 创建一个特定的用户,而且不要使用 ceph 这个名字。这里为了方便,我们使用 cephd 这个账户作为特定的用户,而且每个节点上(monitor、node)上都需要创建该账户,并且拥有 sudo 权限。在 Ceph 集群各节点进行如下操作
1.2.1 创建 ceph 特定用户
$ sudo useradd -d /home/cephd -m cephd
$ sudo passwd cephd1.2.2 添加 sudo 权限
$ echo "cephd ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephd
$ sudo chmod 0440 /etc/sudoers.d/cephd1.2.3 cephd用户互信
接下来在 ceph-deploy 节点上,切换到 cephd 用户,生成 SSH 密钥并把其公钥分发到各 Ceph 节点上,注意使用 cephd 账户生成,且提示输入密码时,直接回车。
1.生成 ssh 密钥
$ ssh-keygen2.将公钥复制到 monitor和node节点
$ ssh-copy-id cephd@k8smaster021.3 其他网络配置
1.3.1 打开网络接口
官网文档中指定 Ceph 的各 OSD 进程通过网络互联并向 Monitors 上报自己的状态,所以要保证网络为开启状态,不过某些发行版(如 CentOS )默认关闭网络接口。所以我们需要保证集群各个节点系统网络接口是开启的。
在 Ceph 集群各节点进行如下操作
$ sudo cat /etc/sysconfig/network-scripts/ifcfg-enp0s3
TYPE="Ethernet"
BOOTPROTO="dhcp"
DEFROUTE="yes"
PEERDNS="yes"
PEERROUTES="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_PEERDNS="yes"
IPV6_PEERROUTES="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="enp0s3"
UUID="3e68d5a3-f9a6-4c83-9969-706f7e3b0bc2"
DEVICE="enp0s3"
ONBOOT="yes" ----------这里要设置为 yes注意:这里因为在我安装的虚拟机集群中网卡为 enp0s3,所以需要修改 /etc/sysconfig/network-scripts/ifcfg-enp0s3 文件,请根据自己系统网卡名去修改对应配置文件。
1.3.2 SELINUX 设置
在 CentOS 系统上, SELinux 默认为 Enforcing 开启状态,为了方便安装,建议把 SELinux 设置为 Permissive 或者 disabled。
在 Ceph 集群各节点进行如下操作
1.临时生效设置
$ sudo setenforce 02.永久生效设置
$ sudo cat /etc/selinux/config
SELINUX=disabled # 这里设置为 Permissive | disabled
SELINUXTYPE=targeted 1.3.3 开放所需端口设置
Ceph Monitors 之间默认使用 6789 端口通信, OSD 之间默认用 6800:7300 这个范围内的端口通信,所以我们需要调整防火墙设置,开放所需端口,允许相应的入站请求。
1.防火墙设置
$ sudo firewall-cmd --zone=public --add-port=6789/tcp --permanent2.当然我们也可以关闭防火墙
$ sudo systemctl stop firewalld.service #停止 firewall
$ sudo systemctl disable firewalld.service #禁止 firewall 开机启动2. Ceph存储集群搭建
集群结构为 k8smaster01 (ceph-deploy、monitor-1)、k8smaster02(monitor-2)、k8smaster03(monitor-3)、k8sslave01(osd-1)、k8sslave02(osd-2)、k8sslave03(osd-3)、k8sslave04(osd-4)。
首先要提一下的是,如果我们在安装过程中出现了问题,需要重新操作的时候,例如想清理我搭建的这个集群的话,可以使用以下命令。
ceph-deploy 上执行:
清理 Ceph 安装包:
ceph-deploy purge k8smaster01 k8smaster02 k8smaster03 k8sslave01 k8sslave02 k8sslave03 k8sslave04清理配置:
ceph-deploy purgedata k8smaster01 k8smaster02 k8smaster03 k8sslave01 k8sslave02 k8sslave03 k8sslave04
ceph-deploy forgetkeys2.1 deploy节点安装ceph-deploy
vim /etc/yum.repos.d/infernalis-ceph.repo
[ceph-noarch]
name=Ceph noarch packages
baseurl=https://download.ceph.com/rpm-{ceph-release}/{distro}/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.ascyum clean all && yum makecache && yum install ceph-deploy
2.2 创建执行目录
首先 Cephd 用户创建一个目录 ceph-cluster 并进入到该目录执行一系列操作。在 deploy 节点上执行如下命令:
$ mkdir ~/ceph-cluster && cd ~/ceph-cluster2.3 创建集群
2.3.1 创建集群
$ ceph-deploy new k8smaster01 k8smaster02 k8smaster03
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/cephd/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.39): /usr/bin/ceph-deploy new monitor-1 monitor-2 monitor-3
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] func : <function new at 0xa06410>
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0xa6add0>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] ssh_copykey : True
[ceph_deploy.cli][INFO ] mon : ['monitor-1', 'monitor-2', 'monitor-3']
[ceph_deploy.cli][INFO ] public_network : None
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] cluster_network : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] fsid : None
...
[ceph_deploy.new][DEBUG ] Monitor initial members are ['monitor-1', 'monitor-2', 'monitor-3']
[ceph_deploy.new][DEBUG ] Monitor addrs are ['10.142.21.21', '10.142.21.22', '10.142.21.23']
[ceph_deploy.new][DEBUG ] Creating a random mon key...
[ceph_deploy.new][DEBUG ] Writing monitor keyring to ceph.mon.keyring...
[ceph_deploy.new][DEBUG ] Writing initial config to ceph.conf...此时,我们会发现 ceph-deploy 会在 ceph-cluster 目录下生成3个文件,ceph.conf 为ceph配置文件,ceph-deploy-ceph.log为ceph-deploy日志文件,ceph.mon.keyring 为 ceph monitor 的密钥环:
$ ll ceph-cluster
总用量 16
-rw-rw-r--. 1 cephd cephd 247 1月 31 14:32 ceph.conf
-rw-rw-r--. 1 cephd cephd 5540 1月 31 14:32 ceph-deploy-ceph.log
-rw-------. 1 cephd cephd 73 1月 31 14:32 ceph.mon.keyring
$ cat ceph.conf
[global]
fsid = b0b23151-c33a-4c8c-baf1-01159d09bc50
mon_initial_members = k8smaster01, k8smaster02, k8smaster03
mon_host = 10.142.21.21,10.142.21.22,10.142.21.23
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx2.3.2 修改 ceph.conf 配置文件
修改 ceph.conf 配置文件,增加副本数为 4,因为我们有4个 osd 节点:
vim ceph.conf
[global]
fsid = b0b23151-c33a-4c8c-baf1-01159d09bc50
mon_initial_members = k8smaster01, k8smaster02, k8smaster03
mon_host = 10.142.21.21,10.142.21.22,10.142.21.23
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd pool default size = 4 #增加默认副本数为42.3.3 Ceph软件包安装
通过 ceph-deploy 在各个节点安装 ceph:
ceph-deploy install k8smaster01 k8smaster02 k8smaster03 k8sslave01 k8sslave02 k8sslave03 k8sslave04此过程需要等待一段时间,因为 ceph-deploy 会 SSH 登录到各 node 上去,依次执行安装 ceph 依赖的组件包。
2.3.4 初始化 monitor 节点
初始化 monitor 节点并收集所有密钥:
$ ceph-deploy mon create-initial不过很遗憾,执行过程中报错了。查看原因应该是已经存在了 /etc/ceph/ceph.conf 配置文件了,解决方案就是加上 –overwrite-conf 参数,覆盖已存在的配置。
$ ceph-deploy --overwrite-conf mon create-initial执行完毕后,会在当前目录下生成一系列的密钥环,应该是各组件之间访问所需要的认证信息吧。
ll ~/ceph-cluster
-rw-------. 1 cephd cephd 113 12月 7 15:13 ceph.bootstrap-mds.keyring
-rw-------. 1 cephd cephd 71 12月 7 15:13 ceph.bootstrap-mgr.keyring
-rw-------. 1 cephd cephd 113 12月 7 15:13 ceph.bootstrap-osd.keyring
-rw-------. 1 cephd cephd 113 12月 7 15:13 ceph.bootstrap-rgw.keyring
-rw-------. 1 cephd cephd 129 12月 7 15:13 ceph.client.admin.keyring
-rw-rw-r--. 1 cephd cephd 222 12月 7 14:47 ceph.conf
-rw-rw-r--. 1 cephd cephd 120207 12月 7 15:13 ceph-deploy-ceph.log
-rw-------. 1 cephd cephd 73 12月 7 14:46 ceph.mon.keyring到此,ceph monitor 已经成功启动了。
2.3.5 创建osd
接下来需要创建 OSD 了,OSD 是最终数据存储的地方,这里我们准备了4个 OSD 节点。
1. prepare OSD:
接下来,我们需要 ceph-deploy 节点执行 prepare OSD 操作,目的是分别在各个 OSD 节点上创建一些后边激活 OSD 需要的信息。
ceph-deploy --overwrite-conf osd prepare k8sslave01:sdd k8sslave02:sdd k8sslave03:sdd k8sslave04:sdd会在/dev/sdd这块裸盘上建两个分区:/dev/sdd1、/dev/sdd2;/dev/sdd1是osd盘,/dev/sdd2是journal盘
备注:
假如磁盘之前有分区信息会报错,可以:
- 先zap掉原有分区:
ceph-deploy disk zap k8sslave01:sdd - 假如之前ceph已经有mount了,再umount一下:
umount /var/lib/ceph/osd/ceph-8 - 更新分区表
partprobe /dev/sdd - 还需要用ceph 相关命令清空ceph osd tree:
https://www.cnblogs.com/boshen-hzb/p/6796604.html
2. 激活 activate OSD:
ceph-deploy osd activate k8sslave01:/dev/sdd1 k8sslave02:/dev/sdd1 k8sslave03:/dev/sdd1 k8sslave04:/dev/sdd1看日志,激活也没有问题。
3. 同步秘钥
最后一步,通过 ceph-deploy admin 将配置文件和 admin 密钥同步到各个节点,以便在各个 Node 上使用 ceph 命令时,无需指定 monitor 地址和 ceph.client.admin.keyring 密钥。
ceph-deploy admin k8smaster01 k8smaster02 k8smaster03 k8sslave01 k8sslave02 k8sslave03 k8sslave04同时为了确保对 ceph.client.admin.keyring 有正确的操作权限,所以还需要增加权限设置。
$ sudo chmod +r /etc/ceph/ceph.client.admin.keyring4. 查看集群状态
至此,Ceph 存储集群已经搭建完毕了,我们可以查看一下集群是否启动成功!
$ ceph -s

或者查看集群健康状况
$ ceph health
HEALTH_OK
查看集群 OSD 信息
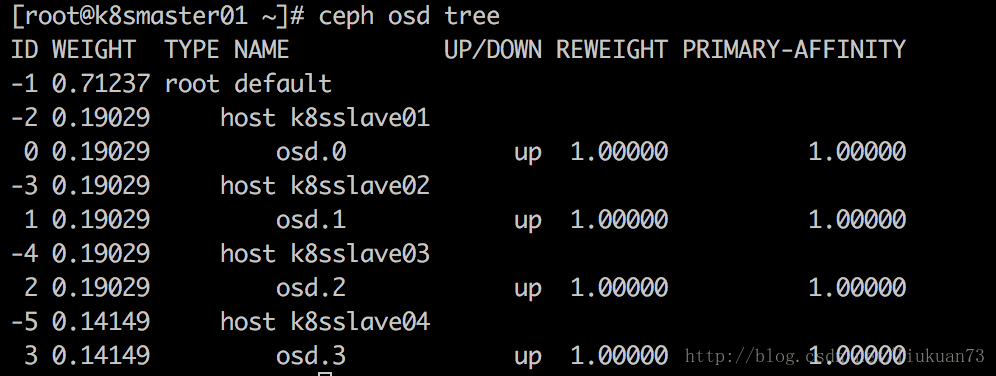
$ ceph osd tree
3. Ceph使用
3.1 ceph块设备(rbd)
Ceph 块设备也可以简称为 RBD 或 RADOS 块设备,不过我们还是习惯叫 RBD,官网文档中指出不能在与 Ceph 存储集群(除非它们也用 VM )相同的物理节点上执行使用 RBD(why?)。
如果另起一个节点的话,那么就得安装 Ceph 到该节点上并配置。注意:以下操作是基于上一篇文章已搭建好的集群结构及目录的,使用 cephd 账号。
3.1.1配置一个新的client节点使用ceph(非之前的monitor或osd节点):
1、在管理节点(admin-node)上,通过 ceph-deply 将 Ceph 安装到该节点 node-client(假设将新节点 hostname 设置为 node-client)。
$ ceph-deploy install node-client2、在管理节点(admin-node)上,通过 ceph-deploy admin 将 Ceph 配置文件和 ceph.client.admin.keyring 密钥同步到该节点 node-client。切换到 Ceph 配置文件和密钥所在目录,执行如下命令:
$ cd ~/ceph-cluster
$ ceph-deploy admin node-clientceph-deploy 部署工具会将密钥信息复制到 node-client 的 /etc/ceph 目录,要确保该密钥环文件有读权限,若没有,到 node2 节点上执行 sudo chmod +r /etc/ceph/ceph.client.admin.keyring 命令。
本次演示,我们不增加新节点,直接在 admin-node 节点上操作,在集群搭建时已经完成上述操作,这里就不用再安装配置 Ceph 了。接下来需要配置 RBD。
3.2 ceph-rbd创建和使用
3.2.1 创建基于ceph-rbd的盘
1、首先在client节点上创建一个块设备镜像 image。
$ rbd create foo --size 1024 //创建一个大小为 1024M 的 ceph image查看已创建的 rbd 列表**
$ rbd list
foo2、创建成功后,在 client节点上,把 foo image 映射到内核,并格式化为块设备(完成后会生成/dev/rbd0和/dev/rbd/rbd/foo -> ../../rbd0)。
$ rbd map foo --name client.admin
报错了,这个原因是没有权限执行,sudo 执行一下。

又报错了,看日志 RBD image feature set mismatch,看样子是 feature 不匹配啊!ceph新版中在map image时,给image默认加上了许多feature,通过rbd info可以查看到 foo 都有哪些 feature:

我们可以看到 rbd image foo 支持匹配的 feature 为:layering, exclusive-lock, object-map, fast-diff, deep-flatten。
rbd的feature表:

--image-feature:
layering: 支持分层
striping: 支持条带化 v2
exclusive-lock: 支持独占锁
object-map: 支持对象映射(依赖 exclusive-lock )
fast-diff: 快速计算差异(依赖 object-map )
deep-flatten: 支持快照扁平化操作
journaling: 支持记录 IO 操作(依赖独占锁)通过dmesg | tail可以看到:

这个地方提示的很清楚了,不支持的属性0x38,0x38是16进制的数值,换算成10进制是3*16+8=56
56的意思是不支持:
32+16+8 = deep-flatten, fast-diff, object-map也就是不支持这些属性,现在关闭这些feature,有两种方式可以修改:
方式一:通过 rbd feature disable {poolname}/{imagename} {feature}命令临时关闭不支持的 feature 类型:

注意:这种方式设置是临时性,一旦 image 删除或者创建新的 image 时,还会恢复默认值。
方式二:通过设置 /etc/ceph/ceph.conf 配置文件,增加 rbd_default_features 配置可以永久的改变默认值:
vim /etc/ceph/ceph.conf
rbd_default_features = 3注意:这种方式设置是永久性的,要注意在集群各个 node 上都要修改。
配置完毕,再次执行 map 命令。

map 成功。
3.2.2 rbd的盘初始化和使用
1.创建文件系统
将 foo image 格式化为 ext4 格式的文件系统:
$ sudo mkfs.ext4 -m0 /dev/rbd/rbd/foo注意这里上边 map 时返回的路径为 /dev/rbd0,这里格式化路径为 /dev/rbd/rbd/foo,其实是同一个地址:
$ ls -al /dev/rbd/rbd/foo
lrwxrwxrwx 1 root root 10 12 7 18:10 /dev/rbd/rbd/foo -> ../../rbd0稍等片刻之后,就格式化成功了。
2.在管理节点(admin-node)上挂载该块设备就可以测试使用了。
$ sudo mkdir /mnt/rbd
$ sudo mount /dev/rbd/rbd/foo /mnt/rbd查看挂载情况:

3.最后,我们测试一下生成一个 500M 大文件,看是否自动同步到 osd节点吧!
$ cd /mnt/rbd
$ sudo dd if=/dev/zero of=testrbd bs=500M count=1
记录了1+0 的读入
记录了1+0 的写出
524288000字节(524 MB)已复制,1.99325 秒,263 MB/秒查看挂载磁盘信息:
$ df -h | grep sdd可以看到其中两个osd节点的空间减少了500M。
4.移除rbd块设备过程:
- 先umount掉
- 再rbd unmap掉
- 最后rbd remove
参考:
1.http://docs.ceph.com/docs/master/rados/deployment/ceph-deploy-osd/
2.https://www.cnblogs.com/boshen-hzb/p/6796604.html
3.http://blog.csdn.net/aixiaoyang168/article/details/78788703
4.http://www.zphj1987.com/2016/06/07/rbd%E6%97%A0%E6%B3%95map-rbd-feature-disable/