如何生成聚类图
1.计算n个样本点两两之间的距离,记为矩阵
2.构造n个类,每一个类中只包含一个样本点,每一类的平台高度均为0
3.合并距离最近的两类为新类,并且以这两类间的距离值作为聚类图中的平台高度
4.计算新类与当前各类的距离,若类的个数已经等于1,转入步骤5,否则回到步骤3
5.画聚类图
6.决定类的个数和类
EG:
设有5个销售员,他们的销售业绩由二维变量(v1,v2)描述,见表格

使用绝对值距离来测量点与点之间的距离,是用最短距离法来测量类与类之间的距离
1.算出距离矩阵
w1 w2 w3 w4 w5
w1 0 1 4 6 6
w2 1 0 3 5 5
w3 4 3 0 2 4
w4 6 5 2 0 4
w5 6 5 4 4 0
2.进行聚类分析
(1)所有的元素自成一类 H1 = {w1, w2,w3,w4,w5}。每一个类的平台高度为0,
(2)把w1,w2 合成一个新类h6,新类的平台高度为1,此时的分类情况是:
H2 = {h6,w3,w4,w5}
(3)把w3,w4 合成一个新类h7,新类的平台高度为2,此时的分类情况是:
H3 = {h6,h7,w5}
(4)把h6,h7 合成一个新类h8,新类的平台高度为3,此时的分类情况是:
H4 = {h8,w5}
(5)把h8,w5 合成一个新类h9,新类的平台高度为4,此时的分类情况是:
H5 = {h9}
代码如下:
clc,clear
a = [1,0;1,1;3,2;4,3;2,5];
[m,n] = size(a);
d = mandist(a')
d = tril(d);
nd = nonzeros(d);
nd = union(nd,nd);
for i = 1:m-1
nd_min = min(nd);
[row,col] = find(d == nd_min);tm = union(row,col);
tm = reshape(tm,1,length(tm));
fprintf('第%d次合成,平台高度为%d时的分类结果为:%s',i,nd_min,int2str(tm));
nd(find(nd == nd_min)) = [];
if length(nd) == 0
break
end
end
代码详解:(按行注释)
聚类前的准备:
1.clc表示清除命令行窗口的所有代码,clear表示清除工作区保存的所有变量。清除某一变量时,直接跟在clear后即可,即 clear x
2.生成矩阵:首尾用中括号括住 [ ],同一行之间的元素用分号或者空格分隔,不同行元素用分号或者回车分隔
3.size(a)表示矩阵的维数,其值赋给两个变量,分别表示行数,列数。即:m =矩阵的行数,n = 矩阵的列数
4.mandist()函数求行向量组之间的两两绝对值距离,详见上一篇博客
5.tril()表示截取矩阵的下三角元素;triu表示截取矩阵的上三角元素
6.nonzeros()表示去除矩阵中所有的零元素,并将剩余的非零元素按序排列
7.union()用于求并集,所求按序排列。可以用其方法去除重复元素
开始聚类
8.for循环,在这里循环的范围设置为1到m-1的原因为:对于m个数值,最多只能合并m-1次,最少合并1次
9.min()求最小值
10.find()函数的基本功能是返回向量或者矩阵中不为0的元素的位置索引
有多种用法,在此只介绍本代码,详细用法参见底部链接
检索矩阵时,可返回两个或三个数组:
eg:
[row,col] = find(x == 3)
意义:row:返回矩阵x中元素值为3的所有行数
col:返回矩阵x中元素值为3的所有列数
eg:
[row,col,val] = find(x>3)
意义:row:返回矩阵x中元素值大于3的所有行数
col:返回矩阵x中元素值大于3的所有列数
val:返回矩阵x中元素值大于3的所有值
11.reshape(A,m,n)函数将矩阵A返回到到一个维数为 mxn 的矩阵B中(元素不变,只是矩阵的维数发生了变化)
此行代码将数组tm变成了行向量,以便于下一行代码的格式化输出
12.%d 表示输出整型,%s表示输出字符串
int2str()表示将数据结构转化为字符串
引号外的参数分别置于引号内语句的格式化结构中
13.a(x) = [ ],表示将a矩阵中索引为x的元素全部删除
14.length(x)表示数列的长度,即数列中元素的个数;当x是一个矩阵时,该函数返回行数或列数的最大值 即:length(x) = max(size(x))
15.循环中的breakbreak终止for或while循环的执行。break语句之后循环中的语句不执行。在嵌套循环中,break只从发生它的循环中退出。控件传递到循环结束后的语句。
循环中的continue:continue将控制权传递给for或while循环的下一个迭代。它跳过当前迭代中循环主体中的任何剩余语句。程序从下一次迭代开始继续执行。continue只应用于调用它的循环体。在嵌套循环中,continue只跳过发生它的循环主体中的其余语句。
结果输出:
第1次合成,平台高度为1时的分类结果为:1 2
第2次合成,平台高度为2时的分类结果为:3 4
第3次合成,平台高度为3时的分类结果为:2 3
第4次合成,平台高度为4时的分类结果为:1 3 4 5
结果解释:
第一次合并,w1,w2距离最近,为1,将其合并为新类h6,并且将其距离值作为平台高度
第二次合并,各类间(h6,w3,w4,w5)中距离最近的为w3,w4,为2,将其合并为新类h7,并且将其距离作为平台高度
第三次合并,各类间(h6,h7,w5)中距离最近的为h6中的w2,与h7中的w3(根据类与类距离的最短距离法),为3,所以将h6,h7合并为新类h8,但输出结果显示为合并w2,w3
第四次合并,各类间(h8,w5)距离最近的为{w1,w3};{w3,w5};{w4,w5},为4,所以将w1,w3,w4,w5合并,也就是将h8与w5合并为h9
生成聚类图,代码如下:
clc,clear
a = [1,0;1,1;3,2;4,3;2,5];
y = pdist(a,'cityblock'); %求a的两两行向量之间的绝对值距离
yc = squareform(y); %变换成距离方阵
z = linkage(y) %产生等级聚类树
[h,t] = dendrogram(z) %画聚类树
T = cluster(z,'maxclust',3) %把对象划分成3类
for i =1:3
tm = find(T == i); %求第i类对象
tm = reshape(tm,1,length(tm)); %变成行向量
fprintf('第%d类的有%s\n',i,int2str(tm)); %显示分类结果
end
代码详解:
1.pdist()函数: Y = pdist(X)计算 m×n 矩阵X(看作m个n维行向量)中两两对象间的欧氏距离。对于有m个对象组成的数据集,共有 (m-1) × m/2 个两两对象组合。
输出Y是包含距离信息的长度为 (m-1) × m/2 的向量。
可用squareform函数将此向量转换为方阵,这样可使矩阵中的元素(i,j)对应原始数据集中对象 i 和 j 间的距离。
2.linkage()函数:
Z = linkage(Y)使用最短距离算法生成具有层次结构的聚类树。输入矩阵Y为pdist函数输出的 (m-1) × m/2 维距离行向量。
Z = linkage(Y,‘method’)使用由method指定的算法计算生成聚类树,‘method’可取:‘single’(最短距离法,默认),‘average’(无权平均距离),‘ward’(离差平方和方法’)等等。
输出Z为包含聚类树信息的 (m-1)×3 矩阵。聚类树上的叶节点为原始数据集中的对象,为1~m。它们是单元素的类,级别更高的类都由它们生成。对应于Z中第 j 行每个新生成的类,其索引为 m+j,其中m为初始叶节点的数量。
矩阵Z的每一列元素的意义:
第一列和第二列,即Z(:,[1:2]),包含了被两两连接生成一个新类的所有对象的索引。生成的新类索引为 m+j.
第三列Z(:,3)包含了相应的在类中的两两对象间的连接距离。
3.dendrogram()函数,根据聚类树生成聚类图
[h,t] = dendrogram(z)的返回值解释:
H — Handles to lines
vector
Handles to lines in the dendrogram plot, returned as a vector.
H:处理聚类图中的行,并作为向量返回
T — Leaf node numbers
column vector
Leaf node numbers for each data point in the original data set, returned as a column vector of length M, where M is the number of data points in the original data set.
When there are fewer than P data points in the original data (P is 30, by default), all data points are displayed in the dendrogram, with each node containing a single data point. In this case, T is the identity map, T = (1:M)’.
T is useful when P is less than the total number of data points. That is, when some leaf nodes in the dendrogram display correspond to multiple data points. For example, to find out which data points are contained in leaf node k of the dendrogram plot, use find(T==k).
T:表示叶子节点数,作为一个列向量返回。原始数据集中每一个数据的叶节点数,都存储在一个长度为M的列向量中被返回,M即为原始数据集中数据的个数。
当数据个数小于P值(P默认为30)时,所有的数据都被展示在聚类图中,即全部都是单元素类,在这种情况下,T是单位映射。
只有当数据个数大于P值时,T才是有意义的。即一些叶节点对应于多个数据。举个例子,为了找出在聚类图中,叶节点K包含哪些数据,需要用到find(T == K)函数。
P:最大叶子节点数,不指定时,默认为30
4.cluster函数:
T = cluster(Z,‘maxclust’,n) constructs a maximum of n clusters using the ‘distance’ criterion.
cluster finds the smallest height at which a horizontal cut through the tree leaves n or fewer clusters.
If n is a vector, T is a matrix of cluster assignments with one column per maximum value.
结果输出与解释:

将a矩阵看作5个2维行向量,计算两两行向量之间的绝对值距离,得到行向量y
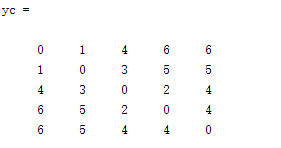
通过squareform函数将距离向量y变换为距离方阵yc

产生等级聚类树的过程:根据默认算法——最短距离法生成聚类树。
在距离方阵中,找到最小值,合并该距离最小值所对应的单元素类,即合并w1,w2,其距离为1,并且新类的索引值为m+1 = 6
继续查找剩余类之间的距离最小值,即合并w3,w4,其距离为2,新类的索引值为m+2 = 7
继续查找剩余类之间的距离最小值,即合并w2,w3,其距离为3,也就是合并类6,类7,并且新类的索引值为8
最后合并w5与类8,其距离为4
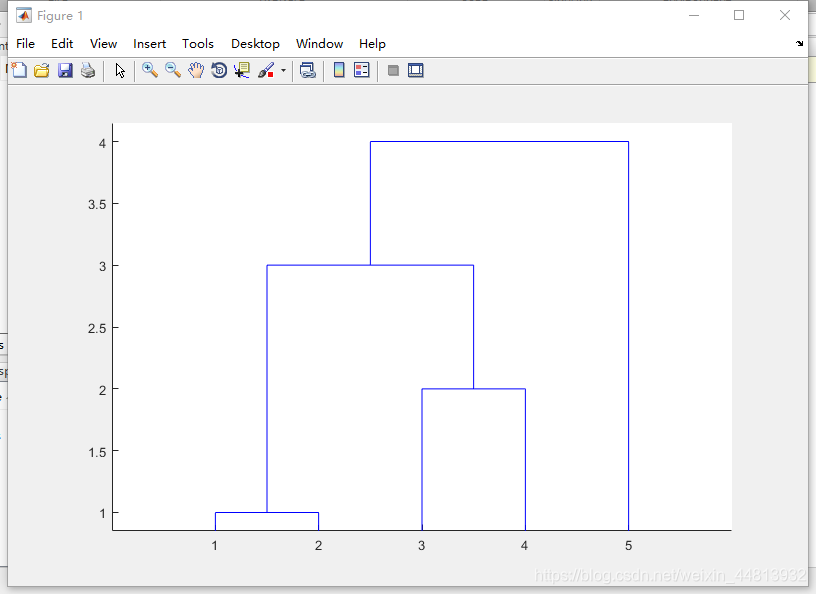
聚类图如上

分类结果如上
待解问题:
1.squareform函数
2.cluster函数
