数组是某种类型的数据按照一定的顺序组成的数据的集合。如果将有限个类型相同的变量的集合命名,那么这个称为数组名。组成数组的各个变量称为数组的分量,也称为数组的元素,有时也称为下标变量。用于区分数组的各个元素的数字编号称为下标。
题目描述:
数字1~1000放在含有1001个元素的数组中,其中只有唯一的一个元素值重复,其他数字均只出现一次。设计一个算法,将重复元素找出来,要求每个数组元素只能访问一次。如果不使用辅助存储空间,能否设计一个算法实现?
方法:
- 空间换时间法
- 累加求和法
- 异或法
- 数据映射法
- 环形相遇法
1.空间换时间法
对于题目,首先需要分析题目所要达到的目标以及其中的限定条件。本题的目标是在一个有且仅有一个元素值重复的数组中找出这个唯一的重复元素,而限定条件是每个数组元素只能访问一次,并且不许使用辅助存储空间。
从前面Hash法的分析中可知,若未对是否可以使用辅助数组做限制的话,最简单的方法是使用Hash法,而在python中可以使用字典来替代Hash法。
当使用字典时,具体过程如下所示:首先定义一个字典,将字典中的元素的值(key值)都初始化为0,将原数组中的元素逐一映射到该字典的key中,当对应的key中value值为0时,则置该key的value值为1,当对应的key的value值为1时,则表明该位置的数在原数组中是重复的,输出即可。
代码实现:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2020/1/26 19:35
# @Author : buu
# @Software: PyCharm
# @Blog :https://blog.csdn.net/weixin_44321080
def findDup(array):
"""
在数组中找唯一重复的元素
:param array: 数组的引用
:return: 重复元素的值,否则返回-1
"""
if array == None:
return -1
lens = len(array)
hashTable = dict()
i = 0
while i < lens - 1: # 去掉重复元素,则含有lens-1个元素
hashTable[i] = 0
i += 1 # 跳出循环,i = lens - 1;
j = 0
while j < lens:
if hashTable[array[j] - 1] == 0:
hashTable[array[j] - 1] = array[j] - 1
else:
return array[i]
j += 1
return -1
if __name__ == '__main__':
array = [1, 3, 4, 2, 5, 3]
print('dup element:', findDup(array))
结果:

算法性能分析:
本方法以空间换时间,时间复杂度为O(n),空间复杂度也为O(n);
2.累加求和法
所谓累加求和法,是将数组中的所有 N+1 (此处N的值取1000)个元素相加,然后用得到的和减去 1+2+3+…+N(此处 N 的值为1000)的和,得到的差即为重复的元素。
为简化问题,以数组序列(1,3,4,2,5,3)为例,该数组长度为6,除了数字3以外,其他4个数字没有重复。sums=18,但数组中只包含1~5的数,和为15,所以重复数字为18-15=3。
算法性能分析:
时间复杂度为O(n);空间复杂度为O(1);
在使用求和法计算时,需要注意一个问题,当数据量巨大时,有可能会导致计算结果溢出。另外,若累加求和法能够成立的话,那累乘呢?求积的方式理论上是成立的,只是实际的使用过程中可操作性不强而已,一般推荐累加法求和。
3.异或法
采用累加求和的方法,虽然能够解决本题,但是存在一个潜在的风险,就是当数组中的元素值太大或者数组太长时,计算的和有可能会出现溢出的情况,因而无法求解出数组中唯一的重复元素。
鉴于求和法存在的局限性,可以采用位运算中异或的方法。根据异或运算的性质可知,当相同元素异或时,其运算结果为0;当相异元素异或时,其运算结果为非0;任何数与数字0进行异或运算,其运算结果为该数。本题中,正好可以使用此方法,将数组里的元素逐一进行异或运算,得到的值再与数字1、2、3、...、N进行异或运算,得到的最终结果即为所求的重复元素。
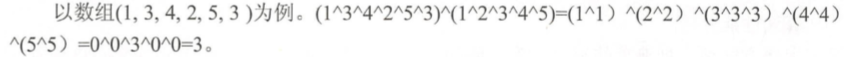
代码实现:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2020/1/26 20:32
# @Author : buu
# @Software: PyCharm
# @Blog :https://blog.csdn.net/weixin_44321080
def findDup(array):
if array == None:
return -1
lens = len(array)
result = 0
i = 0
while i < lens:
result ^= array[i] # 原数组的所有元素进行异或运算
i += 1
j = 1
# 原数组所有元素的取值范围为 1~lens-1;
while j < lens: # j 取值1,2,...,lens-1,最后跳出循环 j=lens
result ^= j
j += 1
return result
if __name__ == '__main__':
array = [1, 3, 4, 2, 5, 3]
print('2dup element:', findDup(array))
结果:

算法性能分析:
该方法的时间复杂度为O(n),没有申请辅助的存储空间;
4.数据映射法
数组取值操作可以看作一个特殊的函数 f:D->R,定义域为下标值 0–1000,值域为 1–1000,如果对于任意一个数 i ,把 f(i) 叫做它的后继,i 叫做 f(i) 的前驱。0只有后继,没有前驱,其他数字既有后继也有前驱,重复的那个数字有两个前驱( 因为0只能存在于定义域中,即只有后继结点;1~N中的任意数,既能存在于定义域中,也能存在于值域中;重复的数字有两个下标索引,即有两个前驱),将利用这些特征。
采用此方法,可以发现一个规律,即从0开始画一个箭头指向它的后继,从它的后继继续指向后继的后继,这样,必然会有一个结点指向之前已经出现过的数,即为重复的数。
利用下标与单元中所存储的内容之间的特殊关系,进行遍历访问单元,一旦访问过的单元赋予一个标记(把数组中的元素变为它的相反数),利用标记作为发现重复数字的关键。

代码实现:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2020/1/26 20:58
# @Author : buu
# @Software: PyCharm
# @Blog :https://blog.csdn.net/weixin_44321080
def findDup(array):
if array == None:
return -1
lens = len(array)
index = 0
while True:
if array[index] > lens: # 数组中的元素的值只能小于lens,否则会越界
# 因为 arr[i] 可能会作为某个元素的前驱
return -1
if array[index] < 0:
break
array[index] *= -1 # 访问过的值标记为相反数
index = -1 * array[index] # index的后继为 array[index]
if index > lens:
print('数组中含有非法数字')
return -1
return index
if __name__ == '__main__':
array = [1, 3, 4, 2, 5, 3]
print('3dup element:', findDup(array))
结果:
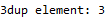
算法性能分析:
时间复杂度为O(n),没有申请辅助的存储空间;
这种方法的缺点是改变了数组中元素的值,当然也可以在找到重复元素之后再对数组进行一次遍历,把数组中的元素修改为它的绝对值的方法来恢复对数组的修改。
5.环形相通法
该方法就是采用类似于单链表是否存在环的方法进行问题求解。单链表可以用数组实现,此时每个元素的值作为 next 指针指向下一个元素。本体可以转化为“已知一个单链表中存在环,找出环的入口”这种想法。

从上图中可以看出这个链表有环,且环的入口点为3,所以这个数组中重复元素为3。
用两个速度不同的变量 slow 和 fast 来访问,其中,slow 每次前进一步,fast 每次前进两步。在有环的结构中,它们总会相遇。接着从数组首元素与相遇点开始分别遍历,每次各走一步,它们必定相遇,且相遇点一定环的入口点。
代码实现:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2020/1/26 21:26
# @Author : buu
# @Software: PyCharm
# @Blog :https://blog.csdn.net/weixin_44321080
def findDup(array):
if array == None:
return -1
slow = 0
fast = 0
while True:
fast = array[array[fast]]
slow = array[slow]
if slow == fast:
break
fast = 0
while True:
fast = array[fast]
slow = array[slow]
if fast == slow: # 找到环的入口
return slow
if __name__ == '__main__':
array = [1, 3, 4, 2, 5, 3]
print('4dup element:', findDup(array))
结果:

算法性能分析:
时间复杂度为O(n),没有申请辅助的存储空间;
当数组中的元素不合理的时候,上述算法有可能会有数组越界的可能性,所以,为了安全性和健壮性,可以在执行 fast=array[array[fast]];slow=array[slow];操作的时候分别检查array[slow]与array[fast]的值是否越界,如果越界,说明提供的数据不合理。
引申:
对于一个给定的自然数 N,有一个 N+M个元素的数组,其中存放了小于等于 N 的所有自然数,求重复出现的自然数序列 [X]。
思路:
对于这个扩展需要,已经标记过的数字在后面一定不会再访问到,除非它是重复的数字,也就是说只要每次将重复数字中的一个改为靠近 N+M 的自然数,让遍历能够访问到数组后面的元素,就能够将整个数组遍历完。
代码实现:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2020/1/26 21:37
# @Author : buu
# @Software: PyCharm
# @Blog :https://blog.csdn.net/weixin_44321080
def findDup(array, num):
s = set()
if array == None:
return s
lens = len(array)
index = array[0]
num = num - 1
while True:
if array[index] < 0:
num -= 1
array[index] = lens - num # 将重复的值改为靠近 lens 的数
s.add(index)
if num == 0:
return s
array[index] *= -1
index = array[index] * (-1)
if __name__ == '__main__':
array = [1, 2, 3, 3, 3, 4, 5, 5, 5, 5, 6] # 共11个元素
num = 6
s = findDup(array, num)
print('result: ', end='')
for i in s:
print(i, end=' ')
结果:
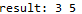
算法性能分析:
时间复杂度为O(n),没有申请辅助的存储空间;
end
