1. 逻辑斯谛回归模型
1.1 逻辑斯谛分布

注:从公式中可以看出,F(x)的取值范围为(0,1),且γ值越小,曲线在中心附近增长越快(试数即可看出).
逻辑斯谛分布的密度函数f(x)与分布函数F(x)如下:

分布函数的图像是一条S曲线,该曲线以点(μ,1/2)为中心对称,即满足:
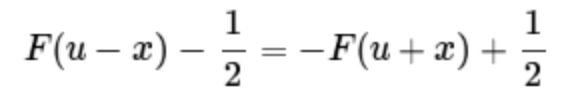
注:两点关于点(μ,1/2)中心对称,则F(μ-x)+F(μ+x)=1,从而推出上面公式
1.2 二项逻辑斯谛回归模型

注:根据这两个式子可以求得P(Y=1|x)和P(Y=0|x),通过比较两个值的大小,将实例x分到概率值较大的那一类.

注: 从该式可以看出,线性函数的值越接近于正无穷,概率值越接近1,线性函数的值越接近负无穷,概率值越接近0.

注: 从该式可以看出,输出Y=1的对数几率是输入x的线性函数,或者说,输出Y=1的对数几率是由输入x的线形函数表示的模型,即逻辑斯谛回归模型.
1.3 模型参数估计

注: 该式即所有训练数据集中Y=1的概率

1.4 多项逻辑斯谛回归

2. 最大熵模型
2.1 最大熵原理
原理: 最大熵原理认为,学习概率模型时,在所有可能的概率模型中,熵最大的模型是最好的模型.所以最大熵原理就是在满足约束条件的模型集合中选取熵最大的模型.即满足约束条件的情况下使平均分布
假设离散随机变量X的概率分布是P(X),则熵为:
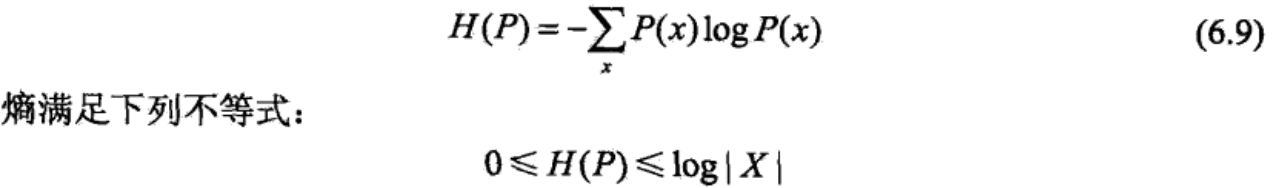
注:|X|表示X的取值个数,当X均匀分布时,熵最大为log|X|.
最大熵原理认为要选择的概率模型在满足已有事实(约束条件)的条件下,如果没有更多信息,则认为哪些不确定的部分是等可能的,最大熵原理通过熵的最大化来表示等可能性.“等可能”不容易操作,而熵是一个可优化的数值指标.
2.2最大熵模型定义
边缘分布:在概率论和统计学的多维随机变量中,只包含其中部分变量的概率分布。


注:P概率上带-表示在给定训练数据中的概率,而不带则表示实际概率
2.3 最大熵模型的学习
2.3.1 求解最大熵模型




2.3.2 求解最大熵模型实例


2.3.3 极大似然估计

注:第一步和最后一步都用到了


3. 模型学习的最优化算法(看不懂了…)
3.1 改进的迭代尺度法




3.2 拟牛顿法


