由于网上资料很多,这里就不再对算法原理进行推导,仅给出博主用Python实现的代码,供大家参考
二项逻辑斯谛回归
适用问题:二类分类
可类比于感知机算法
实验数据:train_binary.csv
实现代码:
# encoding=utf-8
import time
import math
import random
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
class LogisticRegression(object):
def __init__(self):
self.learning_step = 0.0001 # 学习率
self.max_iteration = 5000 # 分类正确上界,当分类正确的次数超过上界时,认为已训练好,退出训练
def train(self,features, labels):
self.w = [0.0] * (len(features[0]) + 1) # 初始化模型参数
correct_count = 0 # 分类正确的次数
while correct_count < self.max_iteration:
# 随机选取数据(xi,yi)
index = random.randint(0, len(labels) - 1)
x = list(features[index])
x.append(1.0)
y = labels[index]
if y == self.predict_(x): # 分类正确的次数加1,并跳过下面的步骤
correct_count += 1
continue
wx = sum([self.w[i] * x[i] for i in range(len(self.w))])
while wx>700: # 控制运算结果越界
wx/=2
exp_wx = math.exp(wx)
for i in range(len(self.w)):
self.w[i] -= self.learning_step * \
(-y * x[i] + float(x[i] * exp_wx) / float(1 + exp_wx))
def predict_(self,x):
wx = sum([self.w[j] * x[j] for j in range(len(self.w))])
while wx>700: # 控制运算结果越界
wx/=2
exp_wx = math.exp(wx)
predict1 = exp_wx / (1 + exp_wx)
predict0 = 1 / (1 + exp_wx)
if predict1 > predict0:
return 1
else:
return 0
def predict(self,features):
labels = []
for feature in features:
x = list(feature)
x.append(1)
labels.append(self.predict_(x))
return labels
if __name__ == "__main__":
print("Start read data...")
time_1 = time.time()
raw_data = pd.read_csv('../data/train_binary.csv', header=0) # 读取csv数据,并将第一行视为表头,返回DataFrame类型
data = raw_data.values
features = data[::, 1::]
labels = data[::, 0]
# 避免过拟合,采用交叉验证,随机选取33%数据作为测试集,剩余为训练集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)
time_2 = time.time()
print('read data cost %f seconds' % (time_2 - time_1))
print('Start training...')
lr = LogisticRegression()
lr.train(train_features, train_labels)
time_3 = time.time()
print('training cost %f seconds' % (time_3 - time_2))
print('Start predicting...')
test_predict = lr.predict(test_features)
time_4 = time.time()
print('predicting cost %f seconds' % (time_4 - time_3))
score = accuracy_score(test_labels, test_predict)
print("The accruacy score is %f" % score)代码可从这里logistic_regression/logistic_regression.py获得
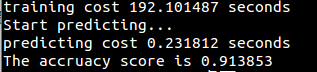
运行结果:
(多项)逻辑斯谛回归
适用问题:多类分类
实验数据:train.csv
实现代码(用sklearn实现):
# encoding=utf-8
import pandas as pd
import time
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
if __name__ == '__main__':
print("Start read data...")
time_1 = time.time()
raw_data = pd.read_csv('../data/train.csv', header=0)
data = raw_data.values
features = data[::, 1::]
labels = data[::, 0]
# 随机选取33%数据作为测试集,剩余为训练集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)
time_2 = time.time()
print('read data cost %f seconds' % (time_2 - time_1))
print('Start training...')
# multi_class可选‘ovr’, ‘multinomial’,默认为ovr用于二类分类,multinomial用于多类分类
clf = LogisticRegression(max_iter=100,solver='saga',multi_class='multinomial')
clf.fit(train_features,train_labels)
time_3 = time.time()
print('training cost %f seconds' % (time_3 - time_2))
print('Start predicting...')
test_predict = clf.predict(test_features)
time_4 = time.time()
print('predicting cost %f seconds' % (time_4 - time_3))
score = accuracy_score(test_labels, test_predict)
print("The accruacy score is %f" % score)代码可从这里logistic_regression/logistic_regression_sklearn.py获得
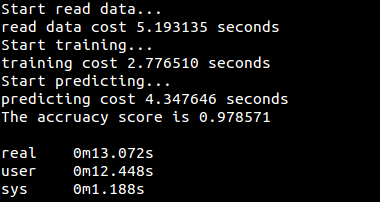
运行结果: