import tensorflow as tf
import numpy as np
#使用numpy生成100个随机点
x_data=np.random.rand(100)
y_data=x_data*0.1+0.2 #这里我们设定已知直线的k为0.1 b为0.2得到y_data
#构造一个线性模型
b=tf.Variable(0.)
k=tf.Variable(0.)
y=k*x_data+b
#二次代价函数(白话:两数之差平方后取 平均值)
loss=tf.reduce_mean(tf.square(y_data-y))
#定义一个梯度下降法来进行训练的优化器(其实就是按梯度下降的方法改变线性模型k和b的值,注意这里的k和b一开始初始化都为0.0,后来慢慢向0.1、0.2靠近)
optimizer=tf.train.GradientDescentOptimizer(0.2) #这里的0.2是梯度下降的系数也可以是0.3...
#最小化代价函数(训练的方式就是使loss值最小,loss值可能是随机初始化100个点与模型拟合出的100个点差的平方相加...等方法)
train=optimizer.minimize(loss)
#初始化变量
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for step in range(201):
sess.run(train)
if step%20==0:
print(step,sess.run([k,b])) #这里使用fetch的方式只是打印k、b的值,每20次打印一下,改变k、b的值是梯度下降优化器的工作
贴一张我的运行结果:
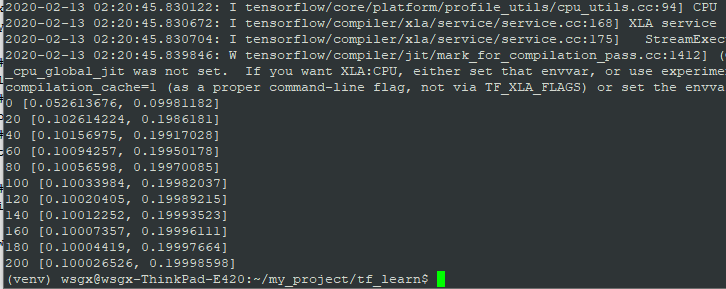
看,k和b在一步步逼近0.1和0.2,是不是很神奇!最终的误差仅为0.000026526和0.00001402,厉害吧,感受到深度学习的强大了么,这里还只是一个神经元,如果成千上万个甚至几十万个会有什么效果呢?
这就是深度学习的power,当然前提是你得配上tensorflow的接口,才能快速高效的搭建自己的神经网络。