质数判断算法优化 之 (哥德巴赫猜想8位数验证)
这是一篇有关解决哥德巴赫猜想10位数验证的的c语言问题,最主要的算法优化在于质数判断。
最终,8位数哥德巴赫猜想验证总共用时5.328秒.期待继续优化。
思维导图先上

一,明确问题
什么是哥德巴赫猜想?
即任一大于2的偶数都可写成两个素数(也叫质数)之和。
百度百科:https://baike.baidu.com/item/%E5%93%A5%E5%BE%B7%E5%B7%B4%E8%B5%AB%E7%8C%9C%E6%83%B3/72364
二,分析问题
1.质数
定义:质数是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。
2.质数的范围
大于2的偶数(num),它等于一个数(i)与另一个数的和(num - i)。所以,i 与(num - i)的范围
是质数的范围。
3.质数的判断
判断 i 与(num - i)是不是质数,可以一个函数专门解决。
三,解决问题
1.0解决版本
1)质数范围问题解决:从2遍历到原数
2)质数判断问题解决:Num和所有比它小的数取余
**验证歌德巴赫猜想函数:**从四开始的偶数
void checkGoldBach(int Maxnum) {
int num;
for (num = 4; num < Maxnum; num += 2) { //从4开始的偶数
if(!canResolve(num)) {
printf("这个数%d无法分解为两个质数,哥德巴赫也要学学编程",num);
return;
}
}
printf("哥德巴赫猜想不亏为“数学王冠上的明珠”!\n");
}
分解偶数函数: 从哪个范围里找质数-----从2遍历到原数
boolean canResolve(int num) {
int i;
for (i = 3; i < num; i += 2) { //为什么不是从质数2开始?因为偶数减2必然是偶数,
//所以从3开始,+=2,避免分解偶数
if (isprime(i) && isprime(num - i)) {
printf("%d = %d + %d\n",num, i, (num - i) );
return TRUE;
}
}
return FALSE;
}
判断质数函数: Num和所有比它小的数取余
boolean isprime(int num) {
int i;
for (i = 2; i < num && num % i; i++) {
; //Num和所有比它小的数取余
}
return i >=num;
}
验证:10000以内的哥德巴赫猜想

但是,效果不好所以,2.0版本就得出世了
2.0版本
1)质数范围问题解决:
思考: 从 i 开始遍历,判断 i 与 (num - i)是不是质数,那么当 i 大于 (num / 2)时,遍历此时无意义。
例如: 偶数18 先判断 3 与 15,接着 5 与 13 ,(假设·继续)接着 7 与 11, 接着 9 和 9 ,
接着 11 与 7 此时就无意义了。两个质数最大都为原数的一半,例如 6 = 3 + 3, 10 = 5 + 5.
所以,此处只用遍历到原数的一半

2)质数判断问题解决:
思考: (i = 2; i <num && num % i; i++), 从 i 遍历 到 num 太浪费时间。 如果 i 是偶数,偶数如果是质数的因数,那么 2 必定是,所以可以 把偶数排除。
换个说法,原数是10000,
如果 2 不是它的因数,则 5000也不是它的因数,那么在5001 ~ 10000也肯定找不到它的因数,
同样,3不是他的因数,那么3333也不是他的因数,则3334 ~ 5000 里也不存在它的因数。
于是,4 与 2500 ,5与 2000等等
直到,10000^0.5 = 100 是,此时100 ~ 10000以后的数都不需要找因数,只用看2 到 100.
所以,从 2遍历到原数的开方,就足够。

运行

3.0版本?
不不,不是的。细心的你可能发现了,boolean,这是什么东东?
一个真假的定义。1 代表TRUE ,0代表 FALSE,增强代码可读性。建立在一个.h文件里。
直接建立在同一文件夹就行。
#ifndef _MEC_H_
#define _MEC_H_
typedef unsigned char boolean; //用于真假声明
#define TRUE 1
#define FALSE 0
#define NOT_FOUND -1
#endif
记得在调用此库文件。

真 3.0版本
1)质数范围问题解决:还有更好的吗?也许。
2)质数判断问题解决:
引入一个思想,自幂数查找里讲过,以空间换时间,建立一个质数池子。怎么建?
看图:
 初步池子是弄好了,虽然很大。那么怎么筛选呢?
初步池子是弄好了,虽然很大。那么怎么筛选呢?
介绍一个方法 -----质数筛选法(爱拉陶斯芬筛法)
筛选的主要方法:
1.划去2的倍数;
2.划去3的倍数;
3 划去5的倍数;(4的倍数同为2的倍数,已被划去)
4.划去7的倍数;(6的倍数同为3的倍数,已被划去)
5.划去11的倍数;(8和10的倍数同为2的倍数,而9的倍数也是3的倍数)
所以验证一个数是否是素数,可以用它来除以2,3,5,7,11…)
刚才上面笔者聊到先把偶数去除,也就是该方法的雏形,
你看,2 的倍数,偶数一定不是质数, 3 的倍数也一定不是质数。如此如此。
相当于,一个数是质数,那么就可以断定他的倍数不是质数。
而且
 接下来
接下来
 构建好质数池子之后,可以使用了。
构建好质数池子之后,可以使用了。

运行:

4.0版本?
是真的,不过先介绍下位运算。
 具体有关位运算会在专门文章里写一写。感觉一时半会讲不清楚。先用吧
具体有关位运算会在专门文章里写一写。感觉一时半会讲不清楚。先用吧
位运算文章链接:凶悍的位运算
每一个字节都是从0~7标注下标。


void screenPrime(int count) {
int prime = 2;
unsigned int index; //
unsigned int i;
int lastNum;
for (index = 4; index < count; index += 2) {
SETB(primePool[index >> 3], index & 7); //偶数置为1;位运算法SETB:把某一字节的指定位给置1
}
lastNum = (int) (sqrt(count) + 1);
for (index = 3; index <= lastNum; index += 2) {
// 3的倍数置为1,接着5的倍数置为1.....
if (!GETB(primePool[(unsigned int) index >> 3], index & 7)) {
for (i = index * index; i < count; i += index) {
// inde*index,这里涉及一个跳转问题,具体看质数的爱拉陶斯芬筛法。
SETB(primePool[i >> 3], i & 7);
}
}
}
}
位运算带来的变化:

疯狂运用位运算,

最终上场:主函数的的故事
int main() {
int Maxnum;
int i;
long startTime;
long midTime;
long endTime;
printf("请输入查找最大范围:");
scanf("%d", &Maxnum);
primePool = (boolean *) calloc(sizeof(boolean), (num + 7) >> 3);
// 4到8要一个字节,9到16要两个字节。于是(4,8)+ 7 = (11,15)/ 8 == 1
// (9, 16) + 7 = (16, 23) / 8 == 2 所以使用(num + 7) >> 3
startTime = clock();
screenPrime(Maxnum);
midTime = clock();
checkGoldBach(Maxnum);
endTime = clock();
midTime -= startTime;
endTime -= startTime;
printf("建质数池子耗时%d.%03d,总共耗时:%d.%03d\n", midTime / 1000, midTime %1000
, endTime / 1000, endTime % 1000);
free(primePool);
return 0;
}
最后运行。
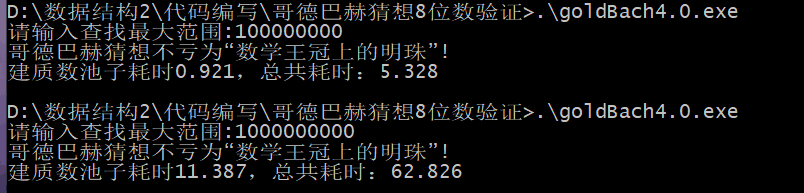 时间上同3.0差不太多,但空间上效率却节省了3.0的87.5%的空间。完结散花!!!
时间上同3.0差不太多,但空间上效率却节省了3.0的87.5%的空间。完结散花!!!
三,总结
1.算法优化需要做好数学分析。方法比想法有效。
2.函数功能的单一化。越纯粹越好编写。
3.不断优化,追求卓越。接触新的,好的想法。
感谢指导老师:铁血教主
笔者水平有限,目前只能描述以上问题,如果有其他情况,可以留言,有错误,请指教,有继续优化的,请分享,谢谢!
2019年11月30日 图书馆
