1.Hadoop的简单安装
安装Hadoop前提需要配置安装好JDK
1.1.进入hadoop官网
http://hadoop.apache.org/
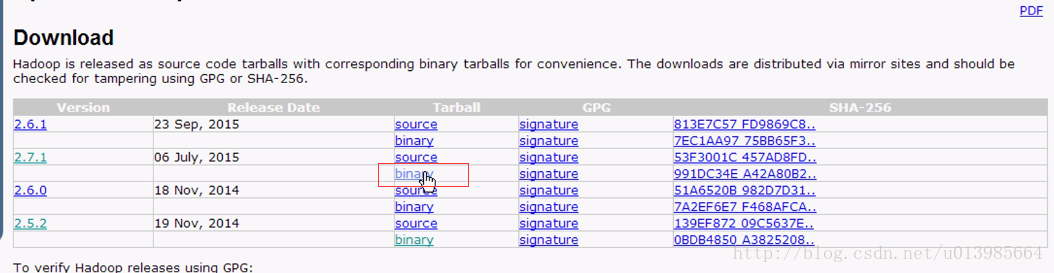
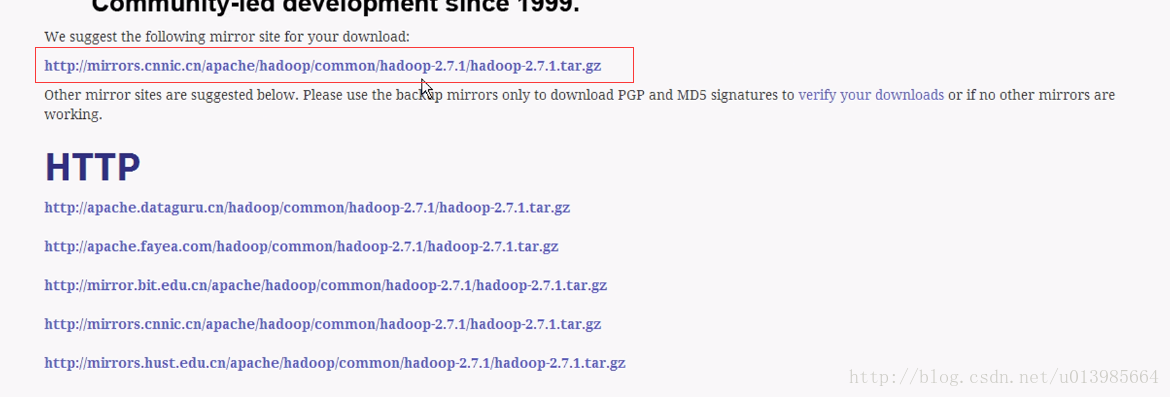
镜像地址:http://mirror.bit.edu.cn/apache/hadoop/common/
1.2.解压安装Hadoop
1.2.1 解压压缩文件
1.2.2 移动重命名
1.2.3 配置环境变量
sudo gedit /etc/profile
注意:此处不用HADOOP_HOME 由于在bin/sbin可执行文件下会动态创建HADOOP_HOME环境变量,若我们自定义了之后可能会干扰动态创建,所以用一个个性化的环境变量名来表示
source /etc/profile 配置文件立即生效
1.2.4 检验
hadoop version
2.Hadoop集群搭建
2.1 同上上传解压hadoop
2.2 修改配置文件
hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
伪分布式需要修改5个配置文件
hadoop-env.sh
之后启动通过ssh方式,${}获取参数会失效,所以改为定值,各配置文件参考中注释自行去除、否则之后初始化会失败

core-site.xml

hdfs-site.xml

mapred-site.xml
mv mapred-site.xml.template mapred-site.xml

yarn-site.xml

2.3 初始化HDFS
hdfs namenode -format (hadoop namenode -format)
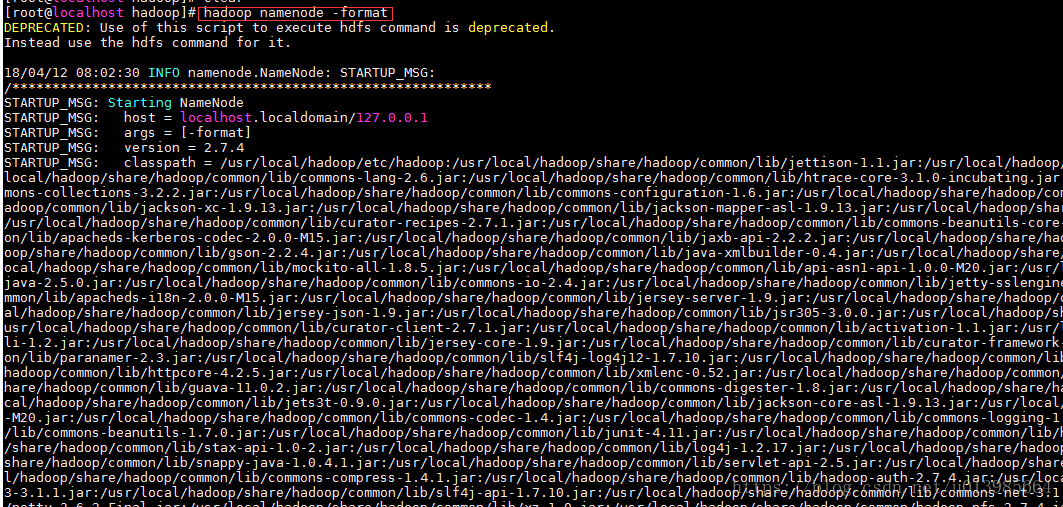
检验
主服务器 启动namenode sbin/hadoop-daemon.sh start namenode
启动完成之后通过JPS 可以查看到namenode正在运行

浏览器访问http://10.102.150.231:50070可以查看相关信息
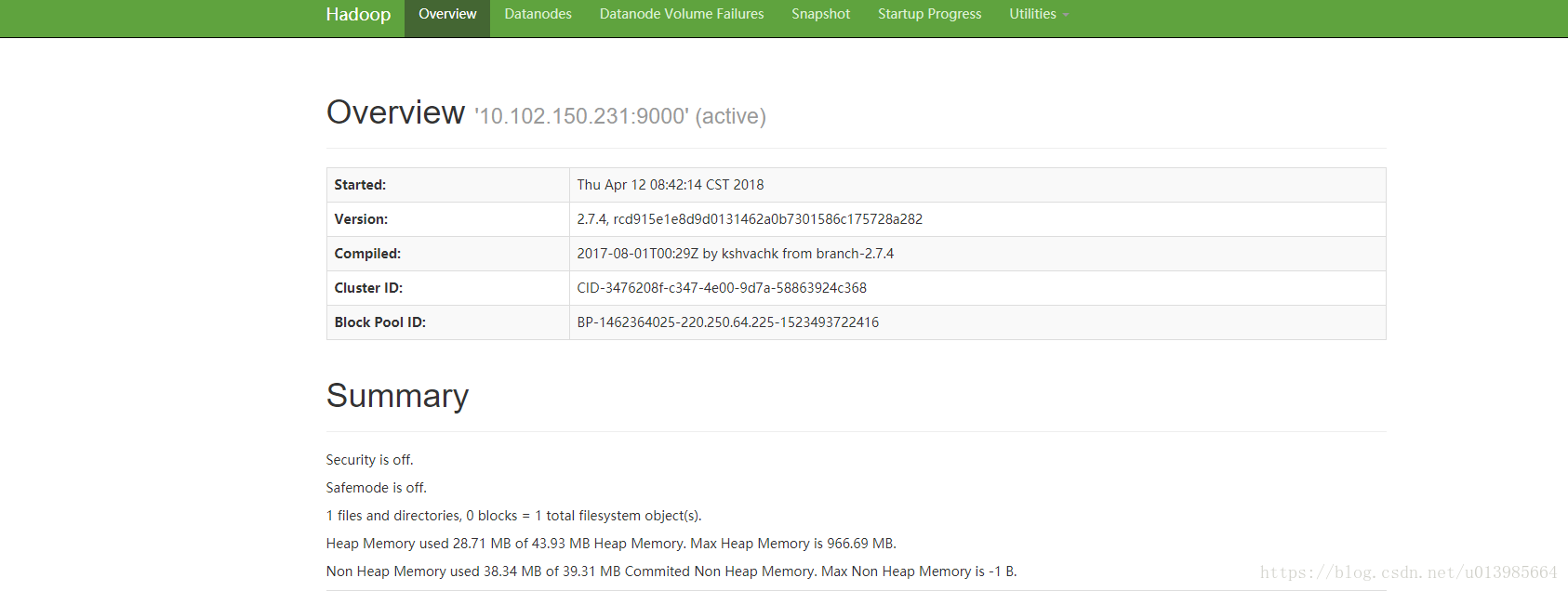
然后任意服务器启动datanode sbin/hadoop-daemon.sh start datanode
同理JPS 可以查看datanode正在运行
再次访问http://10.102.150.231:50070可以看到集群最新状态
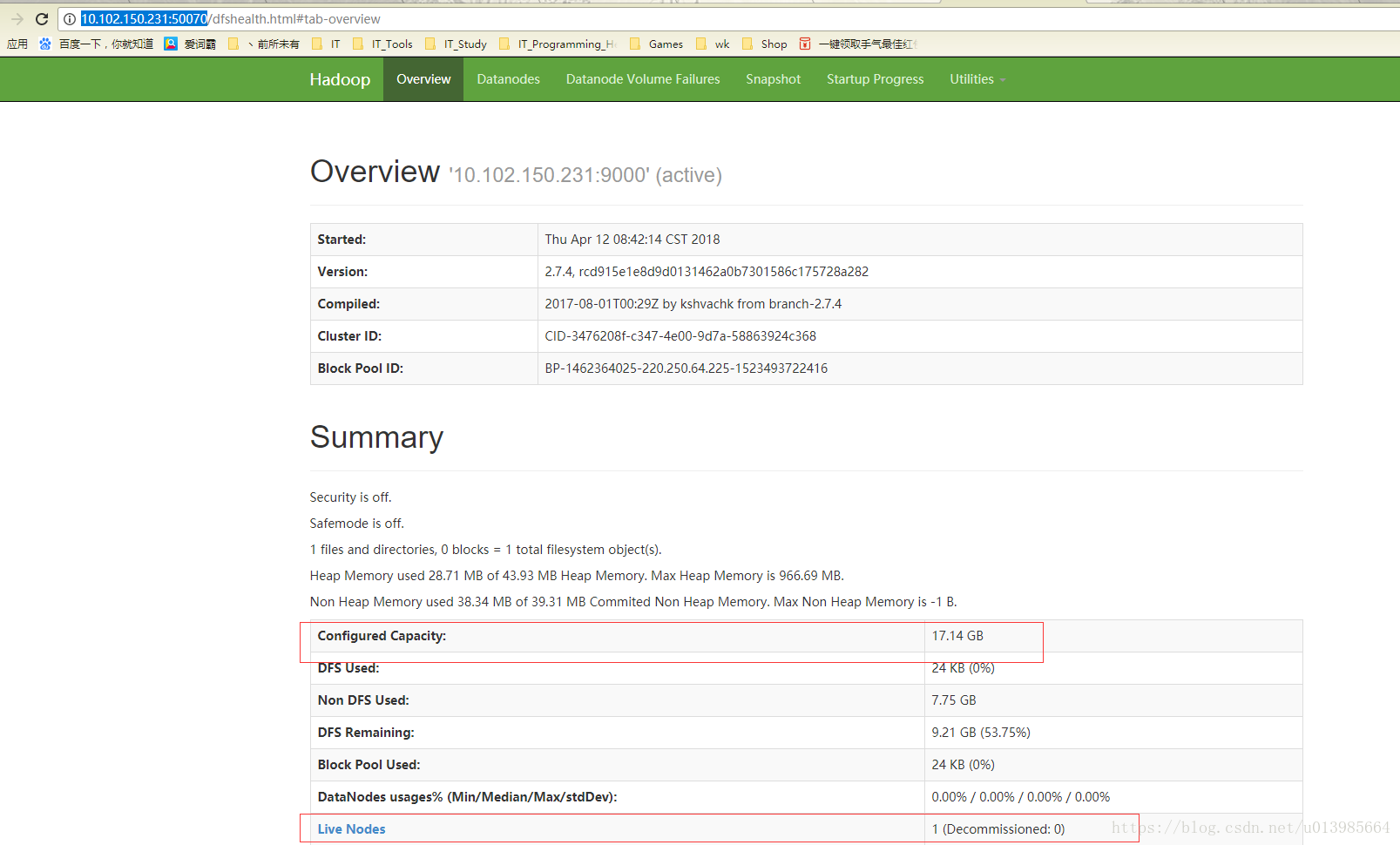
注意:
如果启动datanode之后,界面并未监测到最新状态,例如Live Nodes依然为0,则通过以下方法可能解决:
1)由于多次初始化HDFS导致
删除core-site.xml 中hadoop.tmp.dir中配置文件夹下的其他所有因为初始化生成的文件
rm -rf /home/hadoop/tmp
重新初始化
2)未知的名称或服务
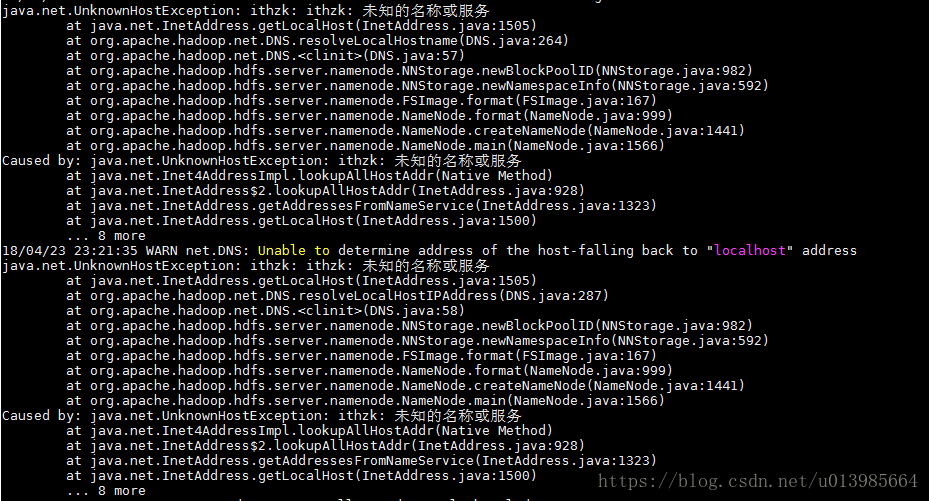
执行hostname查看主机名

修改localhost为hostname显示的主机名,通上删除初始化生成文件重新初始化

3)由于hadoop 不使用hostname,使用ip遇到的问题
(Datanode denied communication with namenode because hostname cann)
通过查看hadoop安装目录下的日志发现
tail -f /usr/local/hadoop/logs/hadoop-root-datanode-ithzk.log
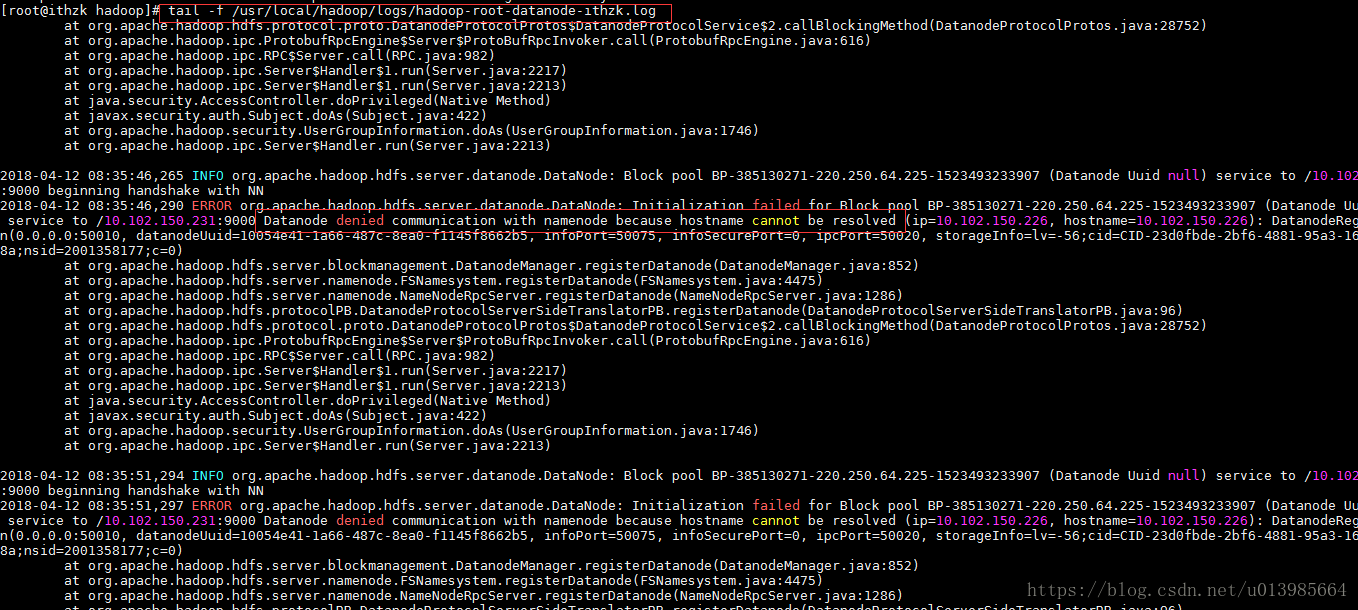
需要在hdfs-site.xml加上以下配置
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property> 重新初始化HDFS即可
2.4 启动 hadoop
2.4.1 先启动 hdfs
vi /usr/local/hadoop/etc/hadoop/slaves
此处配置启动datanode的hostname或者ip都可

sbin/start-dfs.sh
启动之后slaves配置的服务器使用jps可以发现开启了datanode
主服务器会出现namenode和secondarynamenode则启动成功
此操作需要输入各服务器密码
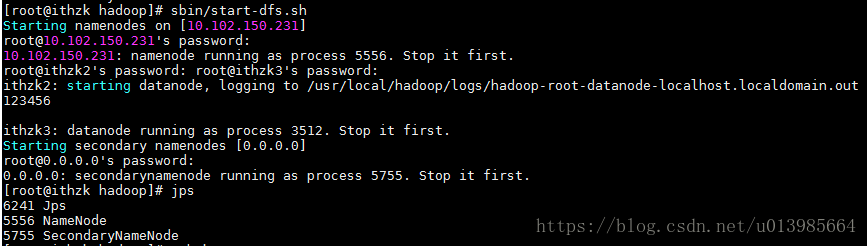
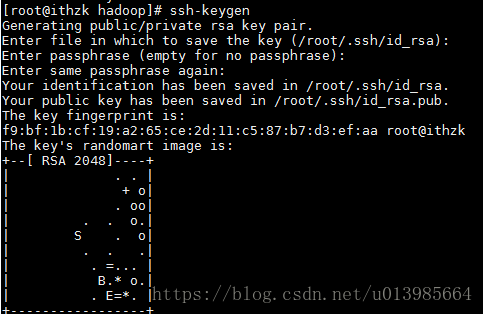
2.4.2 配置免密登录
a)ssh-keygen(生成公钥和私钥文件)
b)ssh-copy-id 10.102.150.231
依次配置主服务器连接其他服务器的免密登录
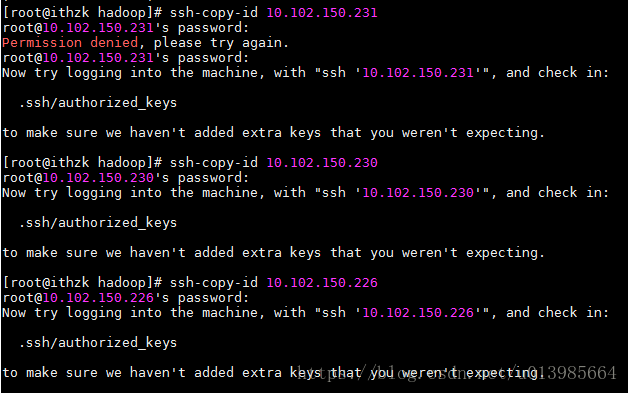
c)通过ssh ip 可验证

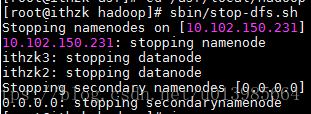
2.4.3 stop dfs
sbin/stop-dfs.sh
配置免密登录后,运行该命令则可免密关闭所有相关功能
2.4.3 再启动 yarn
sbin/start-yarn.she
3.Hadoop基本使用
3.1 查看本地文件系统
hadoop fs -ls /

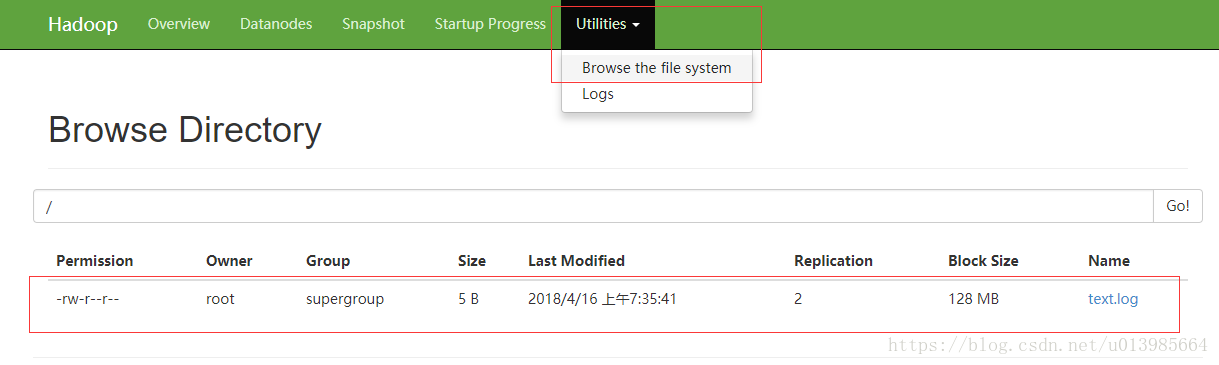
3.2 从本地系统拷贝文件到DFS
hadoop fs -put text.log /

3.3 展示文件内容
hadoop fs -cat /text.log

4.HDFS的Java API简单使用
4.1 pom引用
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>4.2 HdfsClientDemo
package com.ithzk.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
/**
* @author hzk
* @date 2018/4/23
*/
public class HdfsClientDemo {
FileSystem fileSystem = null;
@Before
public void init() throws IOException {
Configuration configuration = new Configuration();
//获取文件系统操作的客户端实例对象
fileSystem = FileSystem.get(configuration);
}
@Test
public void test() throws IOException {
fileSystem.copyFromLocalFile(new Path("G://blogs.txt"),new Path("/blogs.txt.copy"));
fileSystem.close();
}
}

此时运行可能会抛出以上错误,由于此时拿到的是本地文件系统,windows下未配置hadoop所需文件
第一种解决办法:
1.配置HADOOP_HOME环境变量
2.由于hadoop本身bin下文件不适用于windows,可以将以下地址下载文件bin目录下替换原来的bin下文件
Hadoop-2.7.4-win-bin
第二种解决办法:
或者加上这一句也是可以解决的System.setProperty(“hadoop.home.dir”,”G://JavaUtils/Hadoop/hadoop-2.7.4” );
此处设置hadoop路径
4.3 第一种调用方式
客户端去操作hdfs时有一个用户身份
默认情况下会从JVM中获取一个参数作为自己的用户参数 -DHADOOP_USER_NAME 或者通过代码设置
HdfsClientDemo
package com.ithzk.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
/**
* 客户端去操作hdfs时有一个用户身份
* 默认情况下会从JVM中获取一个参数作为自己的用户参数 -DHADOOP_USER_NAME 或者通过代码设置
* @author hzk
* @date 2018/4/23
*/
public class HdfsClientDemo {
FileSystem fileSystem = null;
@Before
public void init() throws IOException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://10.102.150.231:9000");
//获取文件系统操作的客户端实例对象
fileSystem = FileSystem.get(configuration);
}
@Test
public void test() throws IOException {
fileSystem.copyFromLocalFile(new Path("G://blogs.txt"),new Path("/blogs.txt.copy"));
fileSystem.close();
}
}
IDEA设置JVM参数
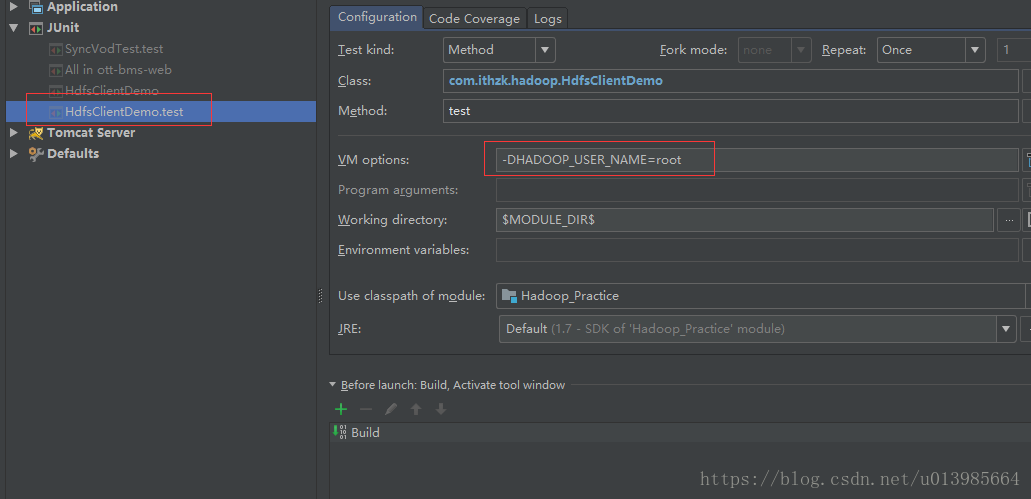
此时,可以看到HDFS上已经存在该文件,即成功
