Q:所有可能隐含状态的集合
V:所有可能观测状态的集合
S:长度为T的状态序列
O:长度为T的观测序列
A:状态转移矩阵
表示在t时刻处于状态的条件下转移到状态
的概率
B:观测概率矩阵
表示在t时刻处于状态的条件下生成观测
的概率
:初始状态概率矩阵
表示在时刻1处于各种状态的概率
两个基本假设:
- 齐次马尔科夫性假设:隐马尔科夫链的t时刻的状态只和t-1时刻的状态有关
- 观测独立性假设:观测状态只与当前时刻的隐含状态有关
三要素:
HMM一般有三类问题:
1.知道 ,由观测序列求隐含状态序列,称为解码问题,即通过维特比算法求解
2.知道,由观测序列求其出现概率,称为评估问题,可通过前向和后向算法解决
3.未知,如何调整这些参数使得观测序列出现的概率尽可能大,称为学习问题
先来看解码问题,本文是学习维基百科上维特比算法的学习笔记
维特比算法(Viterbi )用于寻找最有可能产生观测事件序列的维特比路径——隐含状态序列,特别是在马尔可夫信息源上下文和隐马尔可夫模型中。
说白了,就是已知HMM模型三个参数,通过一个观测序列,找出最有可能的即概率最大的隐含状态序列
下面拿维基百科上这个例子讲一下这个算法的大概意思
背景是一个人生病了去看医生,病人连续三天看医生。病人的状态(即为上面的隐含状态)有两种“健康”和“发烧”,他的感觉(即为观测状态)有三种:正常、冷或头晕。医生发现第一天他感觉正常,第二天感觉冷,第三天感觉头晕。 医生根据经验初步判断(初始状态)其健康的概率为0.6,发烧的概率为0.4,其余黑色线为状态转移矩阵,彩色线为观测概率矩阵

计算第0步:
第一天病人感觉normal,所以

计算第1步:
第二天病人感觉cold,所以
故这这一步在以H为末端的链中,取概率最大的,即为H,H,放弃F,H
以F为末端的链中,取概率最大的,即为H,F,放弃F,F

计算第2步:
第三天病人感觉dizzy,所以
由于已经到了链的末端,所以取概率值最大的隐含状态链即可
故最有可能的隐含状态链为H,H,F
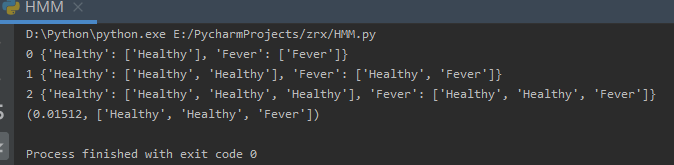
维基给的上述例子的python代码:
# -*- coding: utf-8 -*-
states = ('Healthy', 'Fever')
observations = ('normal', 'cold', 'dizzy')
start_probability = {'Healthy': 0.6, 'Fever': 0.4}
transition_probability = {
'Healthy': {'Healthy': 0.7, 'Fever': 0.3},
'Fever': {'Healthy': 0.4, 'Fever': 0.6},
}
emission_probability = {
'Healthy': {'normal': 0.5, 'cold': 0.4, 'dizzy': 0.1},
'Fever': {'normal': 0.1, 'cold': 0.3, 'dizzy': 0.6},
}
def viterbi(obs, states, start_p, trans_p, emit_p):
V = [{}]
path = {}
# Initialize base cases (t == 0)初始状态,第0步
for y in states:
V[0][y] = start_p[y] * emit_p[y][obs[0]]
path[y] = [y]
print(0,path)
# Run Viterbi for t > 0
for t in range(1,len(obs)):
V.append({})
newpath = {}
for y in states:
#计算隐状态yo->y的概率,并求最大路径
(prob, state) = max([(V[t - 1][y0] * trans_p[y0][y] * emit_p[y][obs[t]], y0) for y0 in states])
V[t][y] = prob
newpath[y] = path[state] + [y]#取到状态y概率最大的链中的前一个状态
# Don't need to remember the old paths
path = newpath
print(t,path)
(prob, state) = max( [(V[len(obs) - 1][y], y) for y in states])
return (prob, path[state])
def example():
return viterbi(observations,
states,
start_probability,
transition_probability,
emission_probability)
print(example())