步骤大概如下


先解压Hadoop的安装包,
然后在 .bash_profile文件中进行修改该安装包的环境变量目录。
(.bash_profile是最重要的一个配置文件,它在用户每次登录系统时被读取,里面的所有命令都会被bash执行)
同时将相应的bin也加入到path中。
然后就是对一些核心文件进行配置。
配置这些文件后,格式化namenode,然后就可以启动集群了。
启动完后,基本也就完成了。
具体步骤如下
1、先将Hadoop的安装包通过Xshell传上到主节点上。
然后需要解压,解压之前,现在home的目录下创建一个data的文件夹。等下将解压的目录方到data 下面


通过ll命令查看,就可以看到刚刚创建的文件夹,如下图所示

接着就可以将Hadoop进行解压到该data文件夹中。
通过输入命令: tar -zxvf hadoop-2.7.4.tar.gz -C data 解压这个Hadoop文件,
并且通过-C进行制定解压到data的目录下,然后回车。
(可查看 https://blog.csdn.net/penghao_1/article/details/103546497tar命令详解)
解压完后,可以通过cd命令,进入到data里面,再通过查看命令ll,如下图所示

然后cd进入到Hadoop的文件中,通过pwd获取当前的路径。 如下图所示

然后通过cd ~,回到目录下。 通过vi命令,进入到 .bash_profile中,进行添加路径操作,如下图所示
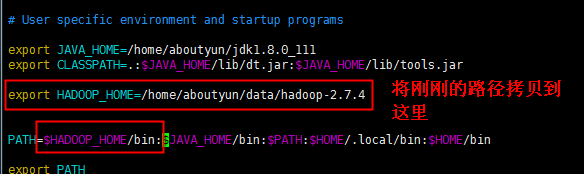
然后保存退出。
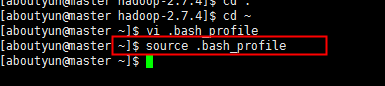
然后通过source 命令,使它进行生效,如下图所示
接下来就是对其核心文件进行配置。(Hadoop的二进制的核心文件都在etc下的hadoop下面)

然后呢,进入到hadoop-env.sh这个文件 输入命令: vi hadoop-env.sh,找到java_home的地方注掉,换一个jdk的
打开另外一个主节点窗口,将jdk的路径拷贝过来。 先进入cd 解压后的jdk(因为hadoop是用Java写的所以要Java的jdk)
然后,pwd命令获取它的当前路径。拷贝过来。如下图所示。

然后保存退出。
同样的方法进行编辑 yarn-env.sh文件,输入命令: vi yarn-env.sh

也是对其java_home 进行添加上。 如图所示

然后保存退出。
然后就是进入到slaves文件里面,把从节点的名称给加上。
![]()
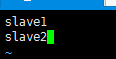
然后就是保存退出。
接下来就是继续配置各种site类型的文件。
1、先配置core-site.xml ,先进入到文件,输入命令 vi core-site.xml,然后输入命令如下

然后就是保存退出。
2、第二个就是配置vi hdfs-site.xml,
但是配置这个之前,先将其路径都要配置好。 打开另外一个主节点窗口。
用创建命令进行 创建目录, 用-p进行创建子目录。如图所示

创建完两个子目录后,就可以在 hdfs-site.xml文件里面进行加上。配置完后如图所示 (前一个是错误的)

保存退出。
3、第三个就是配置 vi mapred-site.xml 但是mapred-site.xml这个文件是没有的,需要从template里面直接复制一个
输入命令 cp mapred-site.xml.template mapred-site.xml ,复制完后再进行编辑 ,如下图所示

配置完后,保存退出,配置如下图所示
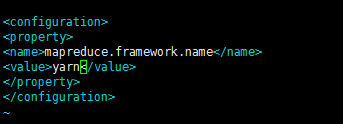
4、对于yarn-site.xml这个文件很多都是默认的,所以不需要对其进行配置。
到此,算是配置完了,最后一步
就是通过cat命令再进行检查一下。
cat core-site.xml
cat hdfs-site.xml
到此为止,算是对主节点的配置完成。
接下来,就是将其分发到各个从节点中去。
1、先回到根目录下面
![]()
2、将一开始配置的环境变量也是需要复制过去
scp .bash_profile aboutyun@slave1:~/ 回车。复制到 aboutyun@slave1的home目录下(~)
scp .bash_profile aboutyun@slave2:~/ 回车。复制到 aboutyun@slave2的home目录下(~)
3、然后通过免密登录 ssh slave1 去执行 source 生效命令
![]()

slave2也是一样,如上图所示
4、然后再将data的整个目录进行复制过去。(因为是复制整个目录,目录底下还有子目录所以用-r)
也是复制到home目录下 scp -r data aboutyun@slave1:~/ 回车。 slave2 也是这么操作
拷贝完后,可以通过ll命令查看。看到data再里面后就表示,其所以节点都已经有了,都已经分发过去了。

其上面的内容和主节点是一样的。
接下来就是可以进行格式化 Hadoop的nameNode
输入命令: hadoop namenode -format 对主节点进行格式化
格式化完后,就可以进行启动了
启动后报错了

格式化完后,就可以进行启动了,
然后进入到sbin下,如图所示: 
![]()
遇到问题,直接yes 同意。
启动start-dfs.sh。启动完了,如图所示

接着启动yarn.sh

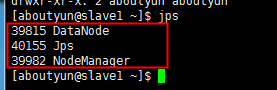
启动完后,通过jps命令,进行验证,看其是否已经启动了
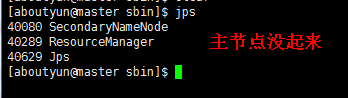

从节点的起来了。
后期关闭服务器时,一定要先将hadoop集群关闭后才能关闭服务器,不然容易出现很多问题。我这里是出现的namenode无法启动,可能还有其他的问题,出了问题一定去日志中看出了什么问题,然后才能对症下药解决。
如果都起来了,那么集群就是启动成功了,接下来就通过浏览器去验证一下
通过8080端口去验证

在这里可以看到集群资源管理器的一个界面,
平时在这里运行一下作业的时候可以看到资源运行的消耗,还有Map的数或reduce数等
一些信息。看到这个界面说明集群已经安装成功了。
遇到主节点启动失败后的处理: Hadoop安装配置中遇到的问题异常处理——aboutyun
